



A medida que las aplicaciones monolíticas se desglosaban en microservicios, los contenedores se convirtieron en la vivienda de facto para estos microservicios. Los microservicios son un enfoque arquitectónico nativo del cloud en el que una sola aplicación consta de muchos componentes o servicios implementables independientes, de acoplamiento flexible y más pequeños. Los contenedores garantizan que el software se ejecute correctamente cuando se mueve entre diferentes entornos. A través de contenedores, los microservicios funcionan al unísono con otros microservicios para formar una aplicación totalmente funcional.
Aunque dividir las aplicaciones monolíticas en servicios más pequeños resuelve un problema, crea problemas mayores en términos de administración y mantenimiento de una aplicación sin un tiempo de inactividad significativo, redes de los diversos microservicios, almacenamiento distribuido, entre otros. Los contenedores ayudan a desacoplar las aplicaciones en bases de código más pequeñas y rápidas, centrándose en el desarrollo de características. Sin embargo, aunque este desacoplamiento es limpio y sencillo al principio, ya que hay menos contenedores que administrar, a medida que aumenta el número de microservicios de una aplicación, resulta casi imposible depurar, actualizar o incluso implementar los microservicios en contenedores de forma segura en la pila sin romper nada ni provocar interrupciones.
La inclusión de aplicaciones en contenedores fue el primer gran paso hacia la creación de entornos de reparación automática sin tiempo de inactividad, pero esta práctica debía evolucionar aún más, especialmente en términos de desarrollo de software y entrega en entornos nativos en el cloud. Esto condujo al desarrollo de programadores y motores de orquestación como Mesos, Docker Swarm, Nomad y Kubernetes. En este capítulo y el siguiente, nos centraremos en Kubernetes debido a su madurez y a su amplia adopción del sector.
Google introdujo Kubernetes al mundo en 2014, después de pasar casi una década perfeccionando y aprendiendo de su sistema interno de gestión de clústeres, Borg. Sencillamente, Kubernetes es un sistema de orquestación de contenedores de código abierto. El término orquestación de contenedores se refiere principalmente al ciclo de vida completo de la administración de contenedores en entornos dinámicos como el cloud, donde las máquinas (servidores) vienen y van según sea necesario. Un orquestador de contenedores automatiza y administra una variedad de tareas, como el aprovisionamiento y la implementación, la programación, la asignación de recursos, el escalado, el equilibrio de carga y la supervisión del estado del contenedor. En 2015, Google donó Kubernetes a la Cloud Native Computing Foundation (CNCF).
Kubernetes, también conocido como K8s, es una de las piezas nativas del cloud más adoptadas, ya que se encarga de la implementación, la escalabilidad y el mantenimiento de aplicaciones en contenedores. Kubernetes ayuda a los ingenieros de fiabilidad del sitio (SRE) y a los ingenieros de DevOps a ejecutar sus cargas de trabajo en el cloud con resiliencia, a la vez que se encarga del escalado y la conmutación por error de aplicaciones que abarcan varios contenedores en varios clústeres.
¿Por qué Kubernetes se llama K8s?
Kubernetes se deriva de una palabra griega que significa timonel o capitán de barco. Kubernetes también se llama K8s. Este numerónimo es el resultado de reemplazar las ocho letras entre K y S («ubernete») con un 8.
A continuación, se incluyen algunas de las características clave que Kubernetes proporciona «out of the box»:
Reparación automática
Una de las características más destacadas de Kubernetes es el proceso de creación de nuevos contenedores cuando un contenedor se bloquea.
Detección de servicios
En un entorno nativo del cloud, los contenedores se mueven de un host a otro. El proceso de averiguar cómo conectarse a un servicio o aplicación que se ejecuta en un contenedor se conoce como detección de servicios. Kubernetes expone los contenedores automáticamente utilizando DNS o sus direcciones IP.
Equilibrio de carga
Para mantener la aplicación implementada en un estado estable, Kubernetes equilibra la carga y distribuye el tráfico entrante automáticamente.
Implementaciones automáticas
Kubernetes funciona con una sintaxis declarativa, lo que significa que no tienes que preocuparte por cómo implementar las aplicaciones. Más bien, tú sabes lo que hay que implementar y Kubernetes se encarga de ello.
Compactación (bin packing)
Para aprovechar al máximo los recursos informáticos, Kubernetes implementa automáticamente los contenedores en el mejor host posible sin desperdiciar ni mermar la disponibilidad general de otros contenedores.
En este capítulo, profundizaremos en los componentes principales y los conceptos subyacentes de Kubernetes. Aunque este capítulo no pretende enseñar Kubernetes en su totalidad, ya que ya hay una amplia variedad de libros1 que tratan el tema en detalle, queremos crear una base sólida. Este enfoque práctico te ayudará a comprender mejor el meollo del entorno en general. Empecemos con un análisis de cómo funciona el clúster de Kubernetes.
Componentes de Kubernetes
El clúster de Kubernetes contiene dos tipos de componentes de nodo:
Plano de control
Este es el componente que gobierna el clúster de Kubernetes. Garantiza que un par de servicios importantes (por ejemplo, la programación o el inicio de nuevos pods2) siempre estén funcionando. El objetivo principal del nodo del plano de control es asegurarse de que el clúster siempre esté en buen estado.
Nodos de trabajo
Estas son las instancias de computación que ejecutan la carga de trabajo en tu clúster de Kubernetes, que hospeda todos tus contenedores.
En la figura 4-1 se ilustran los componentes de alto nivel de Kubernetes. Las líneas son las conexiones, como los nodos de trabajo que aceptan una conexión con el equilibrador de carga, que distribuye el tráfico.
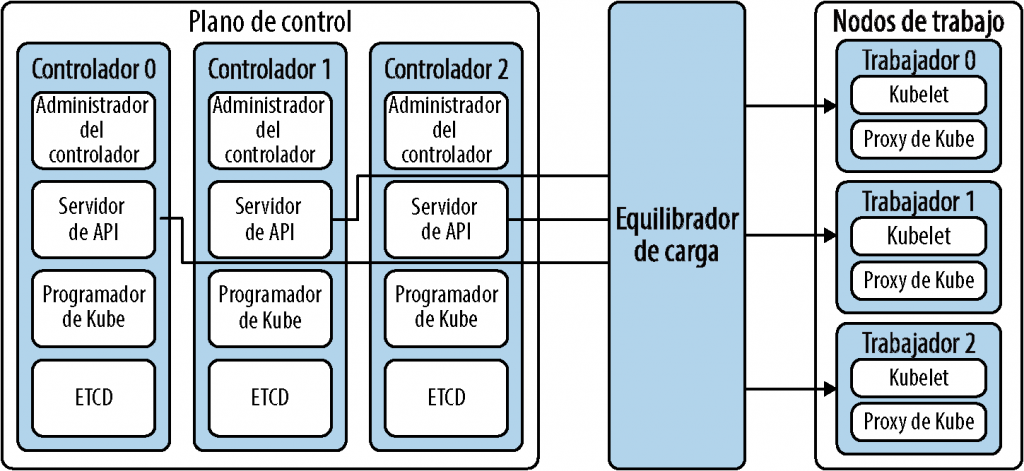
Ahora, examinemos detalladamente cada componente.
Plano de control
El plano de control es principalmente responsable de tomar decisiones globales sobre el clúster de Kubernetes, como detectar el estado del clúster, programar pods en nodos y administrar el ciclo de vida de los pods. El plano de control de Kubernetes tiene varios componentes, que describimos en los apartados siguientes.
kube-apiserver (servidor de API)
El servidor de API es el front-end del plano de control de Kubernetes y el único componente con acceso directo a todo el clúster de Kubernetes. Como hemos visto en la Figura 4-1, el servidor de API sirve como punto central para todas las interacciones entre los nodos de trabajo y los nodos del controlador. Los servicios que se ejecutan en un clúster de Kubernetes utilizan el servidor de API para comunicarse entre sí. Puedes ejecutar varias instancias del servidor de API, porque está diseñado para escalar horizontalmente.
Programador de Kube
El programador de Kube es responsable de determinar qué nodo de trabajo ejecutará un pod (o una unidad básica de trabajo; explicaremos los pods con más detalle más adelante en este capítulo). El programador de Kube se comunica con el servidor de API, que determina qué nodos de trabajo están disponibles para ejecutar el pod programado de la mejor manera posible. El programador busca los pods recién creados que aún están por asignar a un nodo y, a continuación, encuentra los nodos factibles como candidatos potenciales y puntúa cada uno de ellos en función de diferentes factores, como la capacidad de recursos de nodo y los requisitos de hardware, para garantizar que se toma la decisión de programación correcta. El nodo con la puntuación más alta se elige para ejecutar el pod. El programador también notifica al servidor de API acerca de esta decisión en un proceso denominado enlace.
Administrador de controlador de Kube
Kubernetes tiene una característica integrada básica que implementa las capacidades de autorreparación en el clúster. Esta característica se denomina administrador de controlador de Kube y se ejecuta como un demonio. El administrador del controlador ejecuta un bucle de control llamado bucle de conciliación, que es un bucle no predeterminado que es responsable de lo siguiente:
- Determinar si un nodo ha caído y, si es así, tomar medidas. Esto lo hace el controlador de nodo.
- Mantener el número correcto de pods. Esto lo hace el controlador de replicación.
- Unir los objetos del punto de conexión (es decir, los servicers y los pods). Esto lo hace el controlador de punto de conexión.
- Asegurarse de que se crean cuentas y puntos de conexión predeterminados para los espacios de nombres nuevos. Esto lo hacen los controladores de cuenta de servicio y token.
El bucle de conciliación es la fuerza motriz que está detrás de la capacidad de autorreparación de Kubernetes. Kubernetes determina el estado del clúster y sus objetos ejecutando continuamente los siguientes pasos en un bucle:
- Recupera el estado declarado por el usuario (el estado deseado).
- Observa el estado del clúster.
- Compara los estados observados y deseados para encontrar las diferencias.
- Lleva a cabo acciones basadas en el estado observado
etcd
Kubernetes utiliza etcd como almacén de datos. etcd es un almacén de pares clave-valor que se encarga de conservar todos los objetos de Kubernetes. Fue creado originalmente por el equipo de CoreOS y ahora lo administra CNCF. Normalmente se inicia con una configuración de alta disponibilidad y los nodos etcd se alojan en instancias independientes.
Nodos de trabajo
Un clúster de Kubernetes contiene un conjunto de máquinas de trabajo denominadas nodos de trabajo que ejecutan las aplicaciones en contenedores. El plano de control administra los nodos de trabajo y los pods del clúster. Algunos componentes se ejecutan en todos los nodos de trabajo de Kubernetes; estos se tratan en los apartados siguientes.
Kubelet
Kubelet es el agente de demonio que se ejecuta en cada nodo para garantizar que los contenedores siempre estén en ejecución en un pod y que estén en buen estado. Kubelet informa al servidor de API sobre los recursos actualmente disponibles (CPU, memoria y disco) en los nodos de trabajo, de modo que el servidor de API pueda utilizar el administrador del controlador para observar el estado de los pods. Dado que kubelet es el agente que se ejecuta en los nodos de trabajo, los nodos de trabajo se encargan de tareas básicas, como reiniciar contenedores si es necesario y realizar comprobaciones de estado sistemáticamente.
Proxy de Kube
El proxy de Kube es el componente de red que se ejecuta en cada nodo. El proxy de Kube mira todos los servicios de Kubernetes3 del clúster y se asegura de que, cuando se realiza una solicitud a un servicio en particular, se enruta al punto de conexión de IP virtual específico. El proxy de Kube es responsable de implementar un tipo de IP virtual para los servicios.
Ahora que ya tienes los conceptos básicos de los componentes de Kubernetes, vamos a profundizar un poco más y a obtener más información sobre el servidor de API de Kubernetes.
Objetos del servidor API de Kubernetes
El servidor de API es responsable de toda la comunicación dentro y fuera de un clúster de Kubernetes y expone una API HTTP RESTful. El servidor de API, en un nivel fundamental, te permite consultar y manipular objetos de Kubernetes. En términos simples, los objetos de Kubernetes son entidades con estado que representan el estado general del clúster (Figura 4-2). Para empezar a trabajar con estos objetos, necesitamos entender los fundamentos de cada uno de ellos.
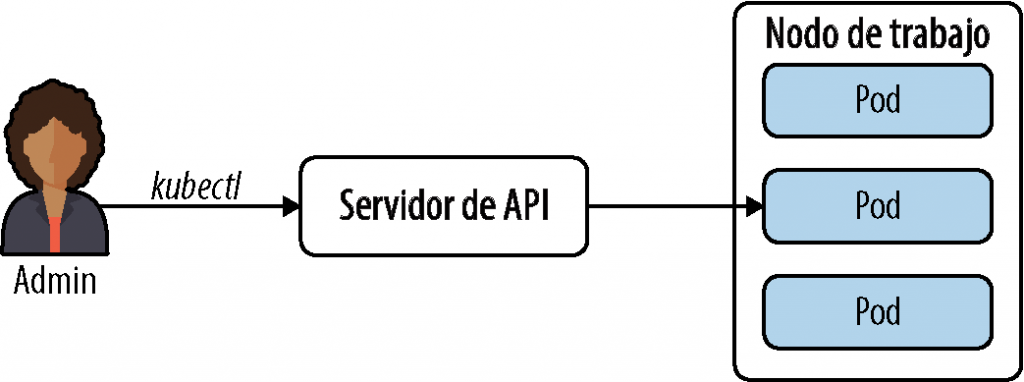
Pods
En Kubernetes, los pods son la unidad atómica básica más pequeña. Un pod es un grupo de uno o más contenedores que se implementan en los nodos de trabajo. Kubernetes es responsable de administrar los contenedores que se ejecutan dentro de un pod. Los contenedores dentro de un pod siempre terminan en el mismo nodo de trabajo y están estrechamente acoplados. Puesto que los contenedores de un pod están coubicados, se ejecutan en el mismo contexto (es decir, comparten la red y el almacenamiento). Este contexto compartido es característico de los espacios de nombres, cgroups y otros aspectos de Linux que mantienen el aislamiento (como explicamos en el capítulo 3). Los pods también obtienen una dirección IP única.
En los escenarios habituales, un solo contenedor se ejecuta dentro de un pod, pero hay casos en los que varios contenedores necesitan trabajar juntos en un pod. Esta última configuración se conoce normalmente como contenedor sidecar. Uno de los ejemplos más comunes de ejecución de contenedores sidecar es cuando se ejecuta un contenedor de registro para una aplicación que enviará los registros al almacenamiento externo, como un servidor ELK (Elasticsearch, Logstash y Kibana), en caso de que el pod de aplicación se bloquee o se elimine un pod. Los pods también son inteligentes, ya que, si finaliza un proceso en un contenedor, Kubernetes lo reiniciará instantáneamente en función de las comprobaciones de estado definidas en el nivel de la aplicación.
Otra característica de los pods es que permiten el escalado horizontal mediante la replicación implementada a través de ReplicaSets. Esto significa que, si quieres que tu aplicación escale en horizontal, debes crear más pods mediante ReplicaSets.
Los pods también son efímeros por naturaleza, lo que significa que, si un pod termina, se moverá y reiniciará en un host diferente. Esto también se consigue mediante el uso de ReplicaSets.
ReplicaSets
La fiabilidad es una característica principal de Kubernetes y, como nadie ejecutaría una sola instancia de un pod, la redundancia es importante. Un ReplicaSet es un objeto de Kubernetes que garantiza que se ejecuta un conjunto estable de pods de réplica para mantener un clúster de recuperación automática. Todo esto se consigue mediante el bucle de conciliación, que sigue ejecutándose en segundo plano para observar el estado general del clúster de Kubernetes. Los ReplicaSets utilizan el bucle de reconciliación y garantizan que, si alguno de los pods se bloquea o se reinicia, se inicia un nuevo pod para mantener el estado de replicación deseado. En general, no debes tratar directamente con ReplicaSets, sino más bien utilizar el objeto Deployment, que garantiza actualizaciones sin tiempo de inactividad de la aplicación y tiene un enfoque declarativo para administrar y utilizar Kubernetes.
Implementaciones
Kubernetes es principalmente un orquestador declarativo centrado en la sintaxis. Esto significa que, para poder implementar nuevas características, debes indicar a Kubernetes lo que necesitas hacer y es responsabilidad de Kubernetes averiguar cómo realizar esa operación de forma segura. Uno de los objetos que ofrece Kubernetes para hacer que el lanzamiento de nuevas versiones de aplicaciones sea más fluido es Deployment. Si actualizas manualmente los pods, deberás reiniciarlos, lo que causará tiempo de inactividad. Aunque un ReplicaSet sabe cómo mantener el número deseado de pods, no hará una actualización sin tiempo de inactividad. Aquí es donde entra en escena el objeto Deployment, ya que ayuda a implementar cambios en los pods sin tiempo de inactividad al mantener un número predefinido de pods activos todo el tiempo antes de implementar un nuevo pod actualizado.
Service
Para exponer una aplicación que se ejecuta dentro de un pod, Kubernetes ofrece un objeto llamado Service. Dado que Kubernetes es un sistema muy dinámico, es necesario asegurarse de que las aplicaciones se comunican con los back-end correctos. Los pods son procesos de corta duración en el mundo de Kubernetes, ya que se crean o destruyen con frecuencia. Los pods se acoplan con una dirección IP única, lo que significa que si te basas solo en la dirección IP de los pods, lo más probable es que termines con la interrupción del servicio cuando un pod falle, ya que el pod recibirá una dirección IP diferente después del reinicio, aunque ya tengas ReplicaSets en ejecución. El objeto Service ofrece una abstracción mediante la definición de un conjunto de pods y una política mediante la cual acceder a ellos. Cada objeto Service obtiene una dirección IP estable y un nombre DNS que se puede utilizar para acceder a los pods. Puedes definir declarativamente los servicios que lideran tus pods y utilizar el selector de etiquetas para acceder al servicio.
Espacios de nombres
Dado que varios equipos y proyectos se implementan en un entorno de producción, es necesario organizar los objetos de Kubernetes. Desde un punto de vista sencillo, los espacios de nombres son clústeres virtuales separados por particiones lógicas; es decir, puedes agrupar tus recursos, como implementaciones, pods, entre otros, en función de particiones lógicas. A algunas personas les gusta pensar en los espacios de nombres como directorios para separar nombres. Cada objeto del clúster tiene un nombre que es único para ese tipo concreto de recurso y, de manera similar, cada objeto tiene un UID que es único en todo el clúster. Los espacios de nombres también te permiten dividir los recursos del clúster entre varios usuarios estableciendo cuotas de recursos.
Etiquetas y selectores
A medida que empieces a usar Kubernetes y crear objetos, te darás cuenta de la necesidad de identificar o marcar tus recursos de Kubernetes para agruparlos en entidades lógicas. Kubernetes ofrece etiquetas para identificar los metadatos de los objetos, lo que te permite agrupar y utilizar fácilmente los recursos. Las etiquetas son pares de clave-valor que se pueden conectar directamente a objetos como pods, espacios de nombres, DaemonSets, etcétera. Puedes añadir etiquetas en cualquier momento y modificarlas como quieras. Para encontrar o identificar tus recursos de Kubernetes, puedes consultar las etiquetas utilizando selectores de etiquetas. Por ejemplo, una etiqueta para un tipo de nivel de aplicación puede ser:
«tier» : «frontend», «tier» : «backend», «tier» : «midtier»
Anotaciones
Las anotaciones también son pares de clave-valor, pero, a diferencia de las etiquetas, que se utilizan para identificar objetos, las anotaciones se utilizan para contener información no identificativa sobre el propio objeto. Por ejemplo, la información de compilación, versión o imagen, como marcas de tiempo, los id. de versión, la rama de Git, los números de PR, hashes de imagen y la dirección del registro, se pueden registrar en una anotación.
Controlador de entrada
Para que tus servicios reciban el tráfico de Internet, necesitas exponer los puntos de conexión HTTP y HTTPS desde el exterior a los servicios de Kubernetes que se ejecutan en pods. Una entrada te permite exponer los servicios que se ejecutan dentro del clúster al mundo exterior ofreciendo equilibrio de carga con terminaciones SSL/TLS (Capa de sockets seguros/Seguridad de la capa de transporte) mediante hosting virtual basado en nombres. Para admitir una entrada, primero debes elegir un controlador de entrada, que es similar a un proxy inverso, para aceptar conexiones entrantes para HTTP y HTTPS.
StatefulSets
Para administrar y escalar tus cargas de trabajo con estado en Kubernetes, debes asegurarte de que los pods sean estables (es decir, que haya una red estable y un almacenamiento estable). Los StatefulSets garantizan el orden de los pods y mantienen su singularidad (a diferencia de los ReplicaSets). Un StatefulSet es un controlador que te ayuda a implementar grupos de pods que siguen siendo resilientes ante reinicios y reprogramaciones. Cada pod de un StatefulSet tiene convenciones de nomenclatura únicas cuyo valor ordinal comienza en 0 y tiene un id. de red estable asociado (a diferencia de un ReplicaSet, en el que la convención de nomenclatura es aleatoria por naturaleza).
DaemonSets
En entornos normales, ejecutamos una serie de servicios y agentes de demonio en el host, incluidos agentes de registro y agentes de supervisión. Kubernetes te permite instalar estos agentes ejecutando una copia de un pod en un conjunto de nodos de un clúster mediante DaemonSets. Al igual que los ReplicaSets, los DaemonSets son procesos de larga ejecución que garantizan que el estado deseado y el estado observado permanezcan iguales. Al eliminar un DaemonSet, también se eliminan los pods que este creó anteriormente.
Trabajos
Los trabajos en el mundo de Kubernetes son entidades de corta duración, que pueden ser pequeñas tareas, como ejecutar un script independiente, por ejemplo. Los trabajos finalmente crean pods. Los trabajos se ejecutan hasta que finalizan correctamente, lo que es la principal diferencia entre un pod que controla un trabajo y un pod normal, que se reiniciará y reprogramará si finaliza. Si se produce un error en un pod de trabajo antes de la finalización, el controlador creará un nuevo pod basado en la plantilla.
Este capítulo es un curso intensivo sobre Kubernetes y solo tiene que ver con la superficie de la orquestación de contenedores. Hay otros recursos disponibles que pueden ayudarte a obtener más información sobre Kubernetes. Algunos de los que recomendamos son:
- Managing Kubernetes de Brendan Burns y Craig Tracey (O’Reilly, 2018)
- Kubernetes: Up and Running, 2ª edición de Brendan Burns, Joe Beda y Kelsey Hightower (O’Reilly 2019)
- “Introduction to Kubernetes”, un curso gratuito de LinuxFoundationX
- Cloud Native DevOps with Kubernetes, 2ª edición de John Arundel y Justin Domingus (O’Reilly, 2022)
Ahora que hemos cubierto alguna terminología básica en el mundo de Kubernetes, echemos un vistazo a los detalles operativos para administrar el clúster.
Observar, operar y gestionar clústeres de Kubernetes con kubectl
Una de las formas más habituales de interactuar con un orquestador de contenedores es usar una herramienta de línea de comandos o una herramienta gráfica. En Kubernetes, puedes interactuar con el clúster de ambos modos, pero la forma preferida es la línea de comandos. Kubernetes ofrece kubectl como CLI. kubectl se utiliza ampliamente para administrar el clúster. Kubectl es como la navaja suiza de Kubernetes, con varias funciones que te permiten implementar y administrar aplicaciones. Si eres administrador del clúster de Kubernetes, utilizarías el comando kubectl extensivamente para administrar el clúster. kubectl ofrece varios comandos, como los siguientes:
- Comandos de configuración de recursos, que son de naturaleza declarativa
- Comandos de depuración para obtener información sobre cargas de trabajo
- Comandos de depuración para manipular e interactuar con pods
- Comandos generales de administración de clústeres
básicos del clúster para administrar clústeres, pods y otros objetos de Kubernetes con la ayuda de kubectl.
Información general del clúster y comandos
El primer paso para interactuar con el clúster de Kubernetes es aprender a obtener conocimientos sobre el clúster, la infraestructura y los componentes de Kubernetes con los que trabajarás. Para ver los nodos de trabajo que ejecutan las cargas de trabajo en tu clúster, ejecuta el siguiente comando kubectl:
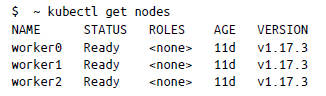
Esto enumerará los recursos del nodo y su estado, junto con la información de versión. Puedes obtener un poco más de información utilizando la marca -o wide en el comando get nodes de la manera siguiente:


Para obtener aún más detalles específicos de un recurso o trabajo, puedes utilizar el comando describe de la siguiente manera:
$ ~ kubectl describe nodes worker0
kubectl describe es un comando de depuración muy útil. Posiblemente podrías utilizarlo para obtener información detallada sobre pods y otros recursos.
El comando get se puede utilizar para obtener más información sobre pods, servicios, controladores de replicación, etc. Por ejemplo, para obtener información sobre todos los pods, puedes ejecutar:

Para obtener una lista de todos los espacios de nombres de tu clúster, puedes usar get de la manera siguiente:
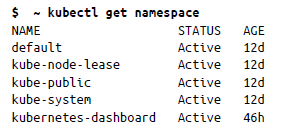
De forma predeterminada, kubectl interactúa con el espacio de nombres predeterminado. Para usar un espacio de nombres diferente, puedes pasar la marca –namespace para hacer referencia a los objetos de un espacio de nombres:
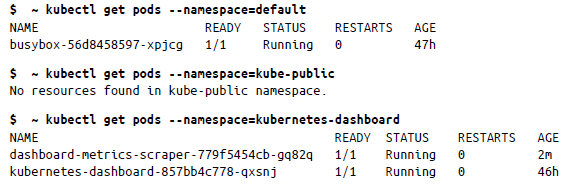
Para ver los detalles generales del clúster, puedes utilizar cluster-info de la siguiente manera:

El comando cluster-info te proporciona los detalles del equilibrador de carga de la API donde está el plano de control, junto con otros componentes.
En Kubernetes, para mantener una conexión con un clúster específico se utiliza un contexto. Un contexto ayuda a agrupar los parámetros de acceso con un nombre. Cada contexto contiene un clúster de Kubernetes, un usuario y un espacio de nombres. El contexto actual es el clúster que es actualmente el predeterminado para kubectl y todos los comandos que kubectl ejecuta se ejecutan en este clúster. Puedes ver el contexto actual de la siguiente manera:

Para cambiar el espacio de nombres predeterminado, puedes utilizar un contexto que se registre en el archivo kubectl kubeconfig de tu entorno. El archivo kubeconfig es el archivo real que le dice a kubectl cómo encontrar tu clúster de Kubernetes y, a continuación, autenticarse basándose en los secretos que se han configurado. El archivo normalmente se almacena en tu directorio principal bajo .kube/. Para crear y utilizar un nuevo contexto con un espacio de nombres diferente como predeterminado, puedes hacer lo siguiente:

Asegúrate de que realmente tienes el contexto (el clúster de Kubernetes de prueba) o de lo contrario no podrás utilizarlo realmente.
Las etiquetas, como hemos mencionado anteriormente, se utilizan para organizar los objetos. Por ejemplo, si quieres etiquetar el pod busybox con un valor llamado production, puedes hacerlo de la siguiente manera, donde environment es el nombre de la etiqueta:

A veces, es posible que quieras averiguar qué sucede con tus pods e intentar depurar un problema. Para ver un registro de un pod, puedes ejecutar el comando logs en un nombre de pod:

A veces, puedes tener varios contenedores ejecutándose dentro de un pod. Para elegir contenedores dentro de él, puedes pasar la marca -c.
Administrar pods
Como ya comentamos antes, los pods son los artefactos implementables más pequeños de Kubernetes. Como usuario final o administrador, tratas directamente con pods y no con contenedores. Kubernetes gestiona los contenedores internamente y esta lógica se abstrae. También es importante recordar que todos los contenedores de un pod se colocan en el mismo nodo. Los pods también tienen un ciclo de vida definido cuyos estados se mueven de Pendiente a En ejecución y a Conseguido o Fallido.
Una de las formas en que puedes crear un pod es con el comando kubectl run de la siguiente manera:
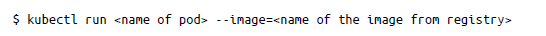
El comando kubectl run extrae una imagen pública de un repositorio de contenedor y crea un pod. Por ejemplo, puedes ejecutar una imagen de hazelcast de la siguiente manera y exponer también el puerto del contenedor:

En los entornos de producción, nunca debes ejecutar ni crear pods, ya que estos pods no están administrados directamente por Kubernetes y no se reiniciarán ni reprogramarán en caso de error. Las implementaciones son la forma preferida de utilizar pods.
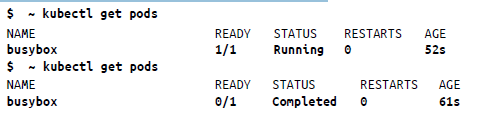
El comando kubectl run contiene conjuntos de características muy completos y permite controlar muchos comportamientos de los pods. Por ejemplo, si deseas ejecutar un pod en primer plano (es decir, con un terminal interactivo dentro del pod) y no deseas reiniciarlo si se bloquea, puedes hacer lo siguiente:

Este comando te registrará directamente dentro del contenedor. Además, dado que ejecutas el pod en modo interactivo, puedes comprobar cómo cambia el estado de busybox de En ejecución a Completado, como a continuación:
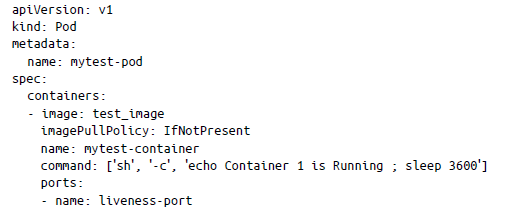
Otra forma de crear pods en Kubernetes es usar la sintaxis declarativa en los manifiestos de pod. Los manifiestos de pod, que deben tratarse con la misma importancia que el código de la aplicación, se pueden escribir usando YAML o JSON. Puedes crear un manifiesto de pod para ejecutar un pod Nginx de la siguiente manera:

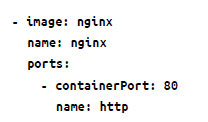
El pod manifiesta información como kind, spec y otra información que se envía al servidor de API de Kubernetes para actuar a partir de ella. Puedes guardar el manifiesto pod con una extensión YAML y usar apply de la siguiente manera:
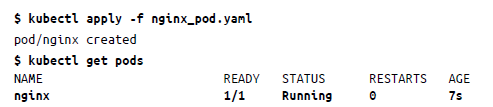
Cuando ejecutas kubectl apply, el manifiesto de pod se envía al servidor de API de Kubernetes, que programa al instante el pod para que se ejecute en un nodo en buen estado del clúster. El pod se supervisa mediante el proceso del demonio kubelet y, si el Pod se bloquea, se reprograma para ejecutarse en otro nodo en buen estado.
Ahora vamos a seguir adelante y a echar un vistazo a cómo implementar comprobaciones de estado de tus servicios en Kubernetes.
Comprobaciones de estado
Kubernetes ofrece tres tipos de comprobaciones de estado HTTP, denominadas sondeos, para garantizar que la aplicación esté realmente activa y en buen estado: sondeos de estado de vida, sondeos de preparación y sondeos de arranque.
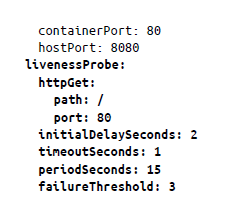
Sondeo de estado de vida. Este sondeo es responsable de garantizar que la aplicación se encuentre en buen estado y funcione correctamente. Después de la implementación, la aplicación puede tardar unos segundos antes de que esté lista, por lo que puede configurar este sondeo para comprobar un punto de conexión determinado en la aplicación. Por ejemplo, en el siguiente manifiesto de pod, se ha utilizado un sondeo de estado de vida para realizar una operación httpGet en la ruta / en el puerto 80. initialDelaySeconds se establece en 2, lo que significa que el punto de conexión / no se alcanzará hasta que haya transcurrido este período. Además, hemos establecido el tiempo de espera en 1 segundo y el umbral de error en 3 errores de sondeo consecutivos. periodSeconds se define como la frecuencia con la que Kubernetes llamará a los pods. En este caso, son 15 segundos.
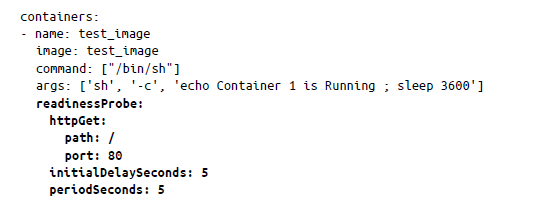
Sondeo de preparación. La responsabilidad del sondeo de preparación es identificar cuándo un contenedor está listo para atender la solicitud del usuario. Un sondeo de preparación ayuda a Kubernetes al no añadir el punto de conexión de un pod no leído a un equilibrador de carga demasiado pronto. Un sondeo de preparación se puede configurar simultáneamente con un bloque de sondeo de estado vivo en el manifiesto de pod de la siguiente manera:
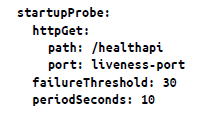
Sondeo de arranque. A veces una aplicación requiere más tiempo de arranque en su primera inicialización. En tales casos, puedes configurar un sondeo de arranque con una comprobación HTTP o TCP que tenga un valor failureThreshold * periodSeconds, que es tiempo suficiente para cubrir el tiempo de arranque en el peor de los casos:
Límites de recursos
Al trabajar con pods, puedes especificar los recursos que necesitará tu aplicación. Algunos de los requisitos de recursos más básicos para ejecutar un pod son la CPU y la memoria. Aunque hay más tipos de recursos que Kubernetes puede gestionar, lo simplificaremos hablando solo de la CPU y la memoria.
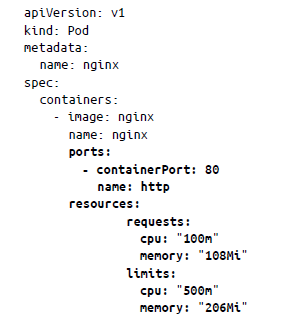
Puedes declarar dos parámetros en el manifiesto de pod: request y limit. En el bloque request le indicas a Kubernetes los requisitos de recursos mínimos para que funcione tu aplicación y en el bloque limit le indicas a Kubernetes el umbral máximo. Si tu aplicación incumple el umbral del bloque de límite, finalizará o se reiniciará y el pod normalmente se expulsará. Por ejemplo, en el siguiente manifiesto de pod, vamos a colocar un límite máximo de CPU de 500 m4 y un límite de memoria máximo de 206 Mi5, lo que significa que si se cruzan estos valores, el pod se expulsará y se reprogramará en algún otro nodo:
Volúmenes
Algunas aplicaciones requieren el almacenamiento permanente de los datos, pero, dado que los pods son entidades de corta duración y con frecuencia se reinician o destruyen sobre la marcha, también se pueden destruir todos los datos asociados al pod. Los volúmenes resuelven este problema con una capa de abstracción de discos de almacenamiento en Azure. Un volumen es una forma de almacenar, recuperar y conservar datos entre pods durante todo el ciclo de vida de la aplicación. Si la aplicación tiene estado, debe utilizar un volumen para conservar los datos. Azure proporciona Azure Disk y Azure Files para crear los volúmenes de datos que ofrecen esta funcionalidad.
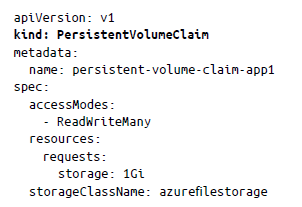
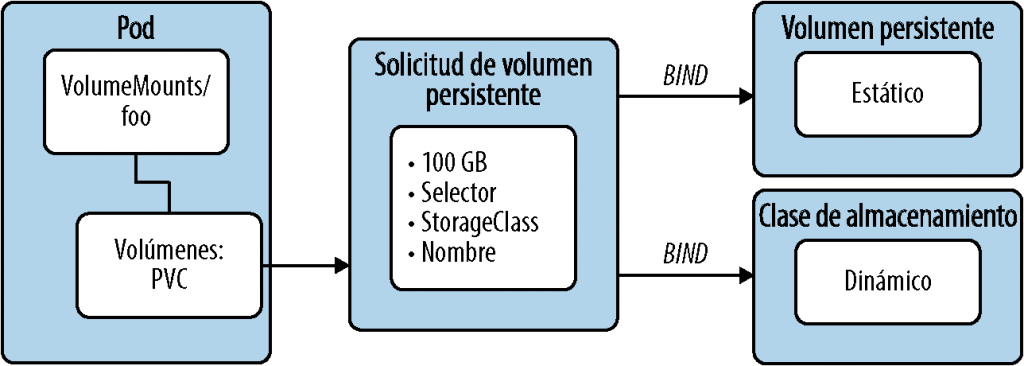
Solicitud de volumen persistente (PVC). La PVC actúa como una capa de abstracción entre el pod y el almacenamiento. En Kubernetes, el pod monta volúmenes con la ayuda de las PVC y estas se comunican con los recursos subyacentes. Cabe destacar que una PVC permite consumir el recurso de almacenamiento subyacente abstraído; es decir, permite solicitar un almacenamiento aprovisionado previamente. La PVC define el tamaño y el tipo del disco, y, a continuación, monta el almacenamiento real en el pod; este proceso de enlace puede ser estático, como en un volumen persistente (PV), o dinámico, como en una clase de almacenamiento. Por ejemplo, en el siguiente manifiesto solicitamos una PersistentVolumeClaim con un almacenamiento de 1 Gi:
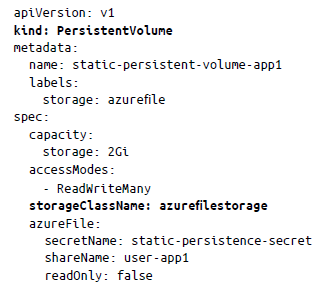
Volumen persistente: estático. Un administrador de clústeres, normalmente el equipo de SRE o DevOps, puede crear un número predefinido de volúmenes persistentes manualmente, que los usuarios del clúster pueden utilizar según lo requieran. El volumen persistente es el método de aprovisionamiento estático. Por ejemplo, en el siguiente manifiesto creamos un PersistentVolume con una capacidad de almacenamiento de 2 Gi:
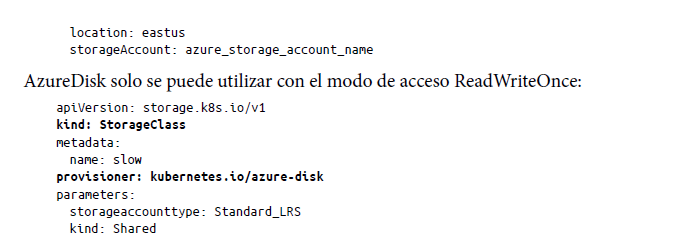
Clase de almacenamiento: dinámico. Las clases de almacenamiento son volúmenes aprovisionados dinámicamente para la PVC; es decir, permiten crear volúmenes de almacenamiento a petición. Básicamente, las clases de almacenamiento proporcionan a los administradores de clústeres una forma de describir las clases de almacenamiento que se pueden ofrecer. Cada clase de almacenamiento tiene un aprovisionador que determina qué complemento de volumen se utiliza para aprovisionar los volúmenes persistentes.
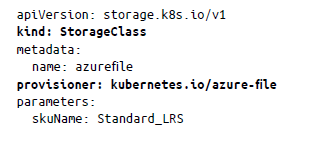
En Azure, dos tipos de aprovisionadores determinan el tipo de almacenamiento que se utilizará: AzureFile y AzureDisk.
AzureFile se puede utilizar con el modo de acceso ReadWriteMany:
En la figura 4-3, se muestra la relación lógica entre los distintos objetos de almacenamiento que ofrece Kubernetes.
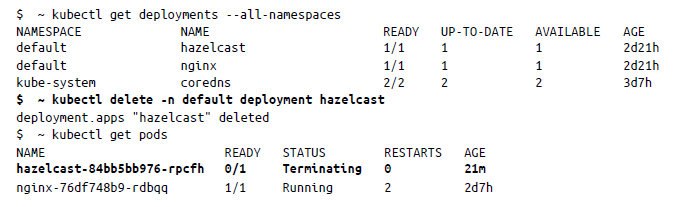
Por último, para eliminar un pod, se utiliza kubectl delete pod de la manera siguiente:

Es importante asegurarse de que, al eliminar un pod, no esté realmente controlado mediante una implementación, porque, si es así, volverá a aparecer. Por ejemplo:
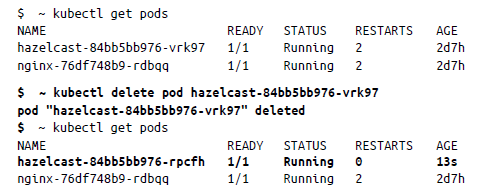
El motivo por el que se derivó un nuevo pod es porque Kubernetes observó que se producía una interrupción en un estado del clúster que hacía que los estados deseados y observados no coincidiesen y, por lo tanto, el bucle de conciliación se activaba para equilibrar los pods. La causa podría ser que el pod se implementase
realmente a través de una implementación y tuviese ReplicaSets asociados.
Por lo tanto, para eliminar un pod, habría que eliminar la implementación, con lo cual, a su vez, se eliminaría el pod automáticamente. Esto se muestra a continuación:
Kubernetes en producción
Ahora que hemos tratado los conceptos básicos de los pods, los conceptos de Kubernetes y cómo funciona el clúster de Kubernetes, echemos un vistazo a cómo vincular los pods y tener todo listo para la producción en un clúster de Kubernetes. En esta sección, veremos cómo los conceptos analizados en la sección anterior habilitan las cargas de trabajo de producción y cómo se implementan las aplicaciones en Kubernetes.
ReplicaSets
Como ya hemos comentado, los ReplicaSets permiten la capacidad de recuperación automática de Kubernetes en el nivel de infraestructura al mantener un número estable de pods. Si se produce un error en el nivel de infraestructura (es decir, los nodos que contienen los pods), el ReplicaSet reprogramará los pods en un nodo correcto diferente. Un ReplicaSet incluye lo siguiente:
Selector
Los ReplicaSets utilizan etiquetas de pod para encontrar y enumerar los pods que se ejecutan en el clúster para crear réplicas en caso de error.
Número de réplicas que se crearán
Especifica cuántos pods se deben crear.
Plantilla
Especifica los datos asociados de los nuevos pods que debe crear un ReplicaSet para satisfacer el número deseado de pods.
En casos prácticos de producción, hará falta un ReplicaSet para mantener un conjunto estable de pods en ejecución mediante la introducción de redundancia. Sin embargo, no es necesario ocuparse del ReplicaSet directamente, ya que es una capa de abstracción. En su lugar, se utilizan implementaciones, que ofrecen una forma mucho mejor de implementar y administrar los pods.

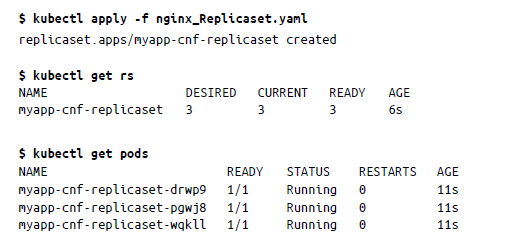
Para crear el ReplicaSet a partir de la configuración anterior, es preciso guardar el manifiesto como nginx_Replicaset.yaml y aplicarlo. Esto creará un ReplicaSet y tres pods, tal como se muestra a continuación:
Implementaciones
En los entornos de producción, lo constante es el cambio. Allí, las aplicaciones se seguirán actualizando o cambiando a un ritmo muy rápido, ya que la tarea más habitual en producción es implementar las nuevas características de la aplicación. Kubernetes ofrece el objeto Deployment como estándar para realizar actualizaciones graduales y proporciona una experiencia fluida tanto al administrador de clústeres como a los usuarios finales. Esto significa que se pueden enviar actualizaciones a las aplicaciones sin retirarlas, ya que Deployment garantiza que solo un número determinado de pods deje de funcionar mientras se actualizan. Es lo que se conoce como implementación con cero tiempo de inactividad. De forma predeterminada, las implementaciones garantizan que al menos el 75 % del número deseado de pods esté en funcionamiento. Las implementaciones son la forma fiable, segura y actual de implementar nuevas versiones de aplicaciones sin tiempo de inactividad en Kubernetes.

Para aplicar la configuración anterior, guárdala en un archivo denominado nginx_Deployment.yaml y luego utiliza kubectl apply del siguiente modo:

Curiosamente, la implementación también gestiona los ReplicaSets, ya que declaramos que necesitaríamos tres réplicas para el pod de implementación. Podemos comprobarlo de la siguiente manera:
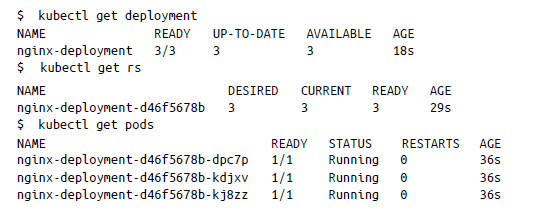
Por lo tanto, en el archivo de manifiesto, creamos tres réplicas en el archivo .spec.replicas y, para que el objeto Deployment encuentre los pods gestionados mediante nginx-deployment, utilizamos el campo spec.selector. Los pods se etiquetan utilizando el campo de plantilla mediante metadata.labels.
Ahora vamos a crear una nueva versión de Nginx. Supongamos que queremos anclar la versión de Nginx en la 1.14.2. Solo tenemos que editar el manifiesto de implementación editando el archivo, es decir, cambiando la versión y guardando el archivo de manifiesto como se indica a continuación:

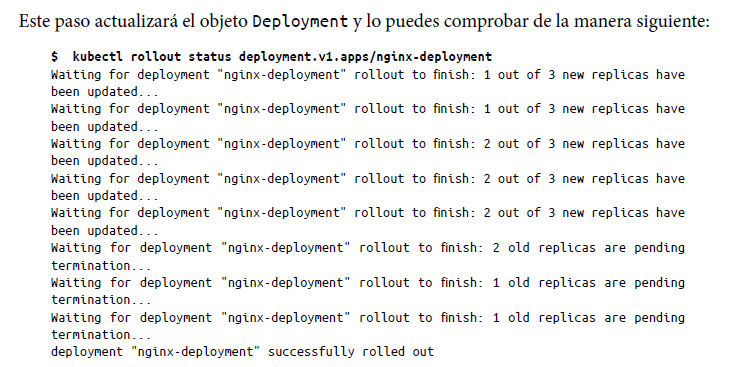
El objeto Deployment garantiza que un determinado número de pods estén siempre disponibles y en servicio mientras se actualizan los pods más antiguos. Como ya hemos mencionado, de forma predeterminada, mientras se realiza una actualización, el número de pods que no están disponibles nunca supera el 25 %. La implementación garantiza un porcentaje de incremento máximo del 25 %, lo que asegura que solo se cree un número de pods determinado por encima del número de pods deseado. Así, en el rollout status, se ve claramente que al menos hay dos pods disponibles en todo momento mientras se está implementando un cambio. Puedes volver a obtener los detalles de la implementación mediante kubectl describe deployment.
Ejecutamos directamente un comando deployment mediante kubectl edit, pero el enfoque preferido es siempre actualizar el archivo de manifiesto real y luego aplicar kubectl. Esto también ayuda a mantener los manifiestos de implementación en el control de versiones. También se puede usar el comando –record o set para actualizar.
Escalador automático de pods horizontales
Kubernetes admite el escalado dinámico mediante el uso del escalador automático de pods horizontales (HPA), donde los pods se escalan horizontalmente; es decir, puedes crear un número n de pods según las métricas observadas de tu pod si, por ejemplo, quieres aumentar o disminuir el número de pods dinámicamente en función de la métrica de la CPU que se está observando. HPA funciona a través de un bucle de control que, en un intervalo de 15 segundos, de forma predeterminada, comprueba la utilización de recursos especificada en las métricas (consulta la Figura 4-4).
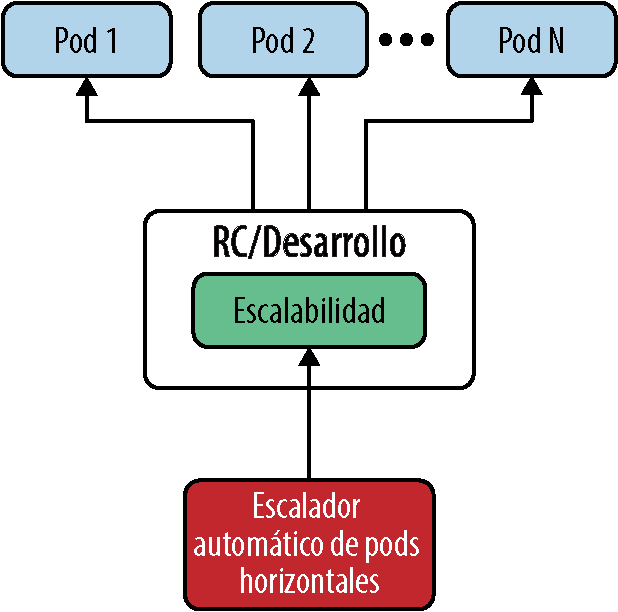
Es importante tener en cuenta que, para usar HPA, necesitamos metrics-server, que recopila las métricas de kubelets y las expone en el servidor de API de Kubernetes a través de la API de métricas para su uso por parte de HPA. Primero creamos un escalado automático mediante kubectl autoscale para nuestra implementación, de la siguiente manera:

El comando kubectl anterior creará un HPA que garantizará que se utilicen no menos de tres y no más de 10 pods en nuestra nginx-deployment. El HPA aumentará o reducirá el número de réplicas para mantener un uso medio de la CPU en todos los pods de no más del 50 %.
Puedes ver tu HPA utilizando lo siguiente:

Podemos añadir el factor de escalado en el que podemos crear el escalado automático con la ayuda de un archivo YAML de manifiesto de HPA vinculado a la implementación.
Service
Como hemos mencionado anteriormente, el entorno de Kubernetes es un sistema muy dinámico donde se crean, destruyen y mueven los pods a un ritmo variable. Este entorno dinámico también abre una puerta a un problema conocido: encontrar los pods de réplica donde reside una aplicación, ya que se ejecutan varios pods para una implementación. Los pods también necesitan una forma de encontrar a los otros pods para comunicarse. Kubernetes ofrece el objeto Service como abstracción para un único punto de entrada al grupo de pods. El objeto Service tiene una dirección IP, un nombre DNS y un puerto que nunca cambia mientras el objeto exista.
Formalmente conocida como detección de servicios, esta función ayuda básicamente a otros pods/servicios a llegar a otros servicios en Kubernetes sin lidiar con la complejidad subyacente. Hablaremos del enfoque de detección de servicios nativos en el cloud con más detalle en el capítulo 6.
Para usar un servicio, puedes utilizar el archivo YAML de manifiesto del servicio. Supongamos que ya tienes una aplicación sencilla «hello world» que se ejecuta como implementación. Una técnica predeterminada para exponer este servicio es especificar el tipo de servicio como ClusterIP. Este servicio estará expuesto en la IP interna del clúster y solo será accesible desde dentro del clúster, como se muestra a continuación:
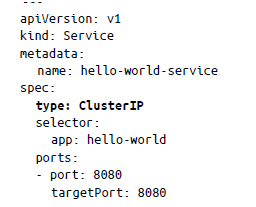
El port representa el puerto en el que el servicio estará disponible y el targetPort es el puerto del contenedor real en el que se reenviará el servicio. En este caso, hemos expuesto el puerto 8080 de la aplicación hello-world en el puerto de destino 8080 en la IP del pod:

La dirección IP mostrada es la IP del clúster y no la dirección IP del equipo real. Si utilizas SSH en un nodo de trabajo, puedes comprobar si el servicio se ha expuesto en el puerto 8080 simplemente haciendo un curl de la siguiente manera:

Si intentas llegar a esta dirección IP desde fuera del clúster (es decir, cualquier otro nodo aparte de los de trabajo), no podrás conectarte a él. Por lo tanto, puedes utilizar NodePort, que expone un servicio en la IP de cada nodo en un puerto definido de la siguiente manera:
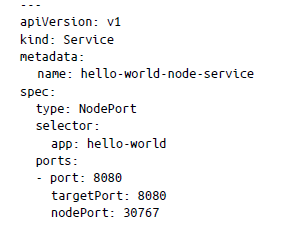
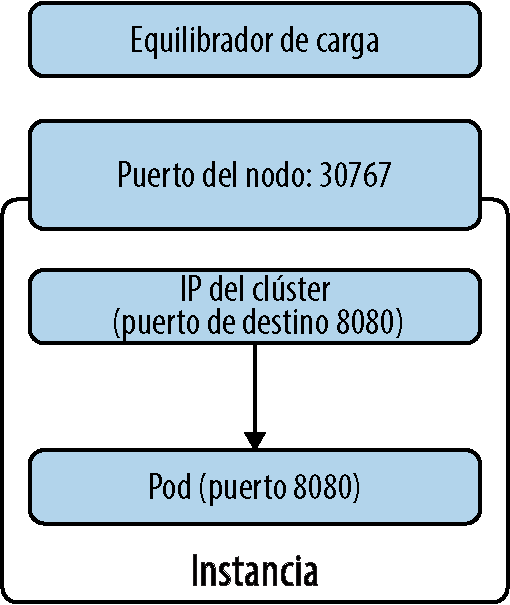
En el manifiesto del servicio, hemos asignado el puerto del pod 8080 a NodePort (es decir, puerto de instancia física) 30767. De esta manera, puedes exponer la IP directamente o colocar un equilibrador de carga de tu elección. Si ahora ejecutas get svc, puedes ver la asignación de puertos de la siguiente manera:
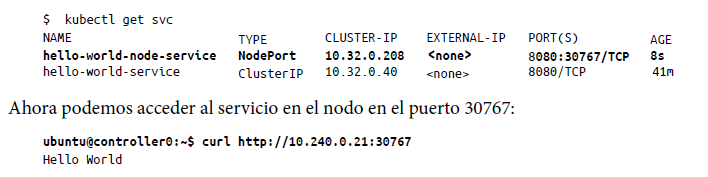
La IP del comando curl es la dirección IP física del nodo de trabajo (no la IP del clúster) y el puerto que se expone es 30767. Incluso puedes llegar directamente a la IP pública del nodo para el puerto 30767. En la Figura 4-5 se muestra cómo se relacionan entre sí la IP del clúster, el puerto del nodo y el equilibrador de carga.
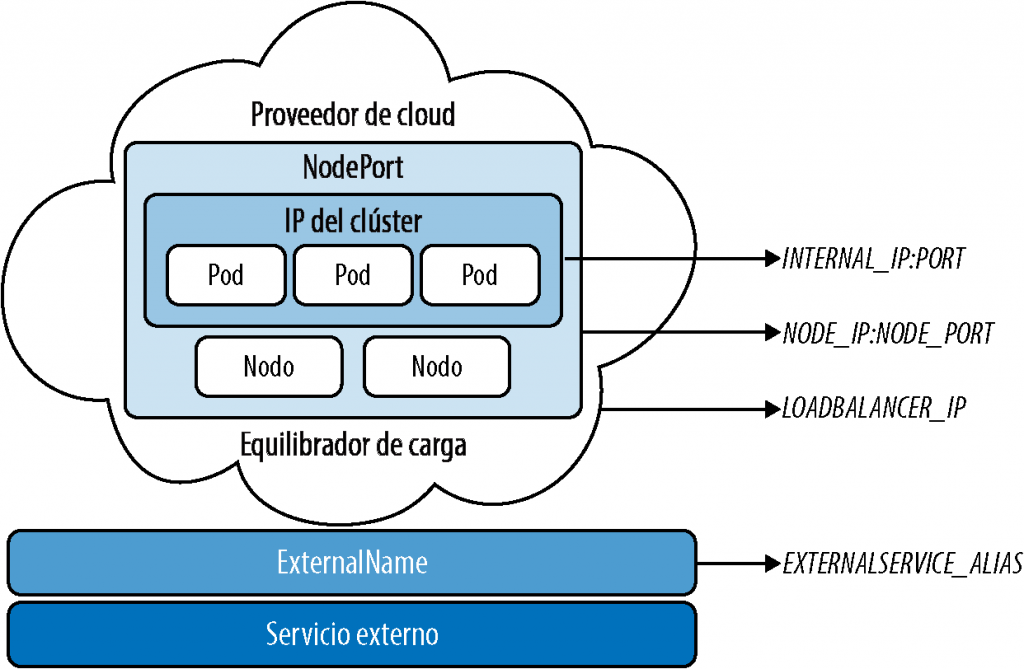
Otros tipos de servicios incluyen LoadBalancer y ExternalName. LoadBalancer expone el servicio externamente utilizando el equilibrador de carga de un proveedor de cloud. Los servicios NodePort y ClusterIP, a los que se enruta el equilibrador de carga externo, se crean automáticamente, mientras que ExternalName asigna un servicio a un nombre DNS como my.redisdb.inter nal.com. En la Figura 4-6, puedes ver cómo están relacionados entre sí diferentes tipos de servicios.
Ingress
El objeto Service ayuda a exponer la aplicación tanto dentro como fuera del clúster, pero en los sistemas de producción no podemos permitirnos seguir abriendo puertos nuevos y únicos para todos los servicios que implementamos con NodePort, ni podemos crear un nuevo equilibrador de carga cada vez que elegimos el tipo de servicio para que sea LoadBalancer. A veces tenemos que implementar un servicio basado en HTTP y también realizar la descarga de SSL, y el objeto Service realmente no nos ayuda en esos casos. En Kubernetes, el equilibrio de carga HTTP (o, formalmente, el equilibrio de carga de Capa 7) lo realiza el objeto Ingress.
Para trabajar con Ingress, primero tenemos que configurar un controlador de entrada.6 Configuraremos un controlador de entrada de Azure Kubernetes Service (AKS) Application Gateway para entenderlo mejor y ver cómo se comporta, pero, en general, una de las formas más sencillas de entenderlo mejor es observando lo siguiente:

En el manifiesto de entrada, hemos creado dos reglas y hemos asignado foo.bar.com como host a un subdominio /bar, que se enruta a nuestro servicio anterior hello-world-node-service.
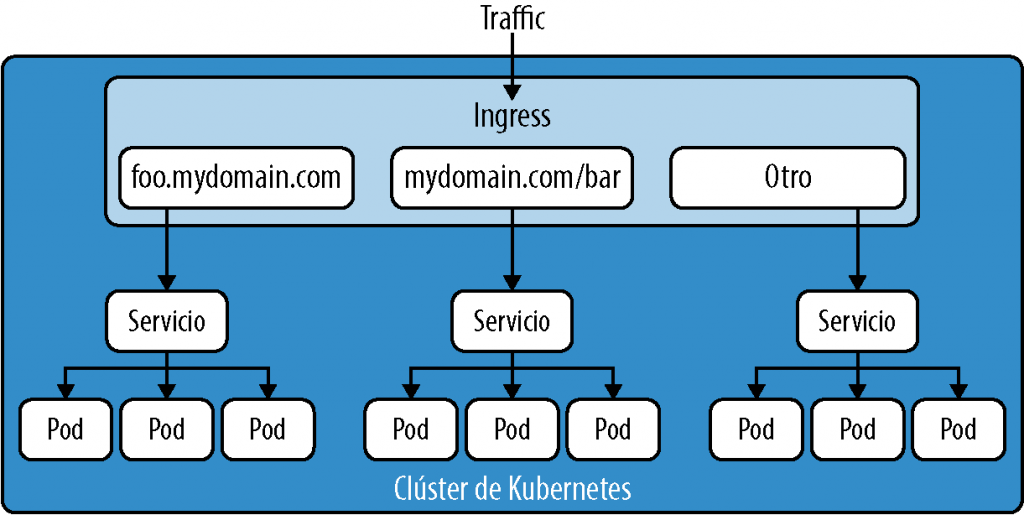
Del mismo modo, podemos tener varias rutas definidas para un dominio y enrutarlas a otros servicios. Hay varias maneras de configurar la entrada según tus necesidades, desde un enrutamiento de un único dominio a varios servicios o el enrutamiento de varios dominios a varios dominios (consulta la Figura 4-7).
Por último, puedes especificar la compatibilidad con TLS creando un objeto Secret y utilizando después ese secreto en tus especificaciones de entrada de la siguiente manera:
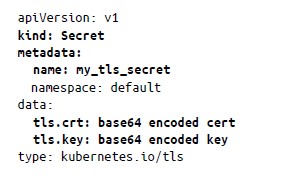
Puedes proteger la entrada especificando solo el certificado TLS codificado en Base64 y la clave. Cuando hagas referencia a este secreto en tu manifiesto de entrada, aparecerá de la siguiente manera:
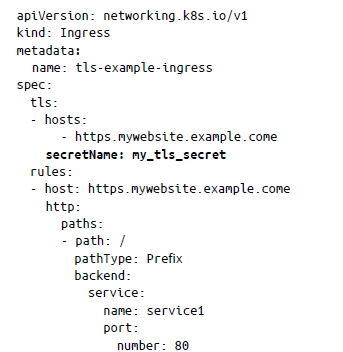
Los controladores de entrada tienen que lidiar con muchas características y complejidades, y el controlador de entrada de Azure Gateway se encarga de muchas de ellas; por ejemplo, aprovechando el equilibrador de carga de la puerta de enlace de aplicaciones de Capa 7 nativo de Azure para exponer tus servicios a Internet. Hablaremos de esto con más detalle en la introducción a AKS, en el capítulo 5.
DaemonSet
Los DaemonSets, como ya comentamos anteriormente, se suelen utilizar para ejecutar un agente en varios nodos del clúster de Kubernetes. El agente se ejecuta dentro de un contenedor abstraído por los pods. La mayoría de las veces, los ingenieros de SRE y DevOps prefieren ejecutar un agente de registro o un agente de supervisión en cada nodo para obtener telemetría y eventos de aplicación. De forma predeterminada, un DaemonSet crea una copia de un pod en cada nodo, aunque esto también se puede limitar mediante un selector de nodos. Hay muchas similitudes entre replicaSets y DaemonSets, pero la distinción clave entre ellos es el requisito (con DaemonSets) de ejecutar una aplicación de un solo agente (es decir, pod) en todos tus nodos.
Una de las formas de ejecutar un contenedor de registro es implementar un pod en cada nodo mediante un DaemonSet. Fluentd es una solución de registro de código abierto ampliamente utilizada para recopilar registros de sistemas. En este ejemplo, se muestra una de las formas de implementar Fluentd mediante un DaemonSet:

En la configuración de DaemonSet anterior, creamos un DaemonSet que implementará el contenedor Fluentd en cada nodo. También hemos creado una tolerancia, que no programa el nodo Fluentd en los nodos maestros (del plan de control).
Kubernetes ofrece características de programación denominadas contaminaciones y tolerancias:
- Las contaminaciones en Kubernetes permiten que un nodo repela un conjunto de pods (es decir, si quieres que determinados nodos no programen algún tipo de pod).
- Las tolerancias se aplican a los pods y permiten (pero no requieren) que los pods se programen en nodos con contaminaciones coincidentes.
Las contaminaciones y tolerancias funcionan en conjunto para garantizar que los pods no se programen en nodos inadecuados. Una o más contaminaciones se aplican a un nodo; esto indica que el nodo no debe aceptar ningún pod que no tolere las contaminaciones.

Jobs
A veces tenemos que ejecutar un script pequeño hasta que termine correctamente. Kubernetes le permite hacerlo con el objeto Job. El objeto Job crea y administra pods que se ejecutarán hasta completarse correctamente y, a diferencia de los pods normales, una vez completada la tarea dada, estos pods creados por Job no se reinician. Puedes utilizar un archivo YAML de Job para describir un objeto Job sencillo de la siguiente manera:
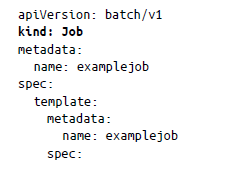
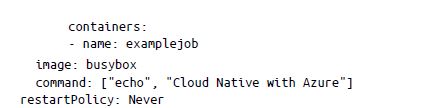
Aquí hemos creado un objeto Job para imprimir un comando de shell. Para crear un objeto Job, puedes guardar el archivo YAML anterior y aplicarlo usando kubectl apply. Una vez que apliques el manifiesto de trabajo, Kubernetes creará el trabajo y lo ejecutará inmediatamente. Puedes comprobar el estado del trabajo mediante kubectl describe de la manera siguiente:
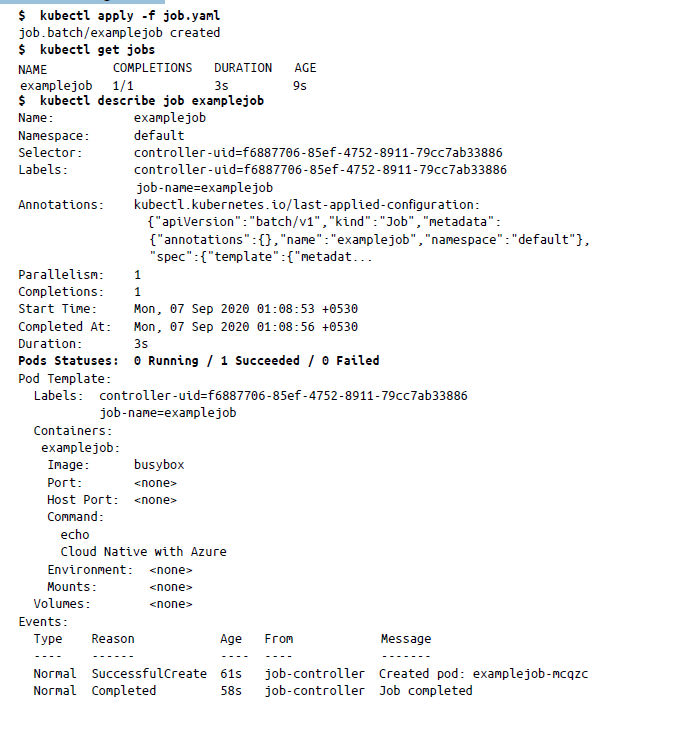
Resumen
Kubernetes es una poderosa plataforma que se creó a partir de una década de experiencia obtenida al convertir aplicaciones en contenedores a escala en Google. Kubernetes básicamente condujo al nacimiento de la Cloud Native Computing Foundation y fue el primer proyecto en graduarse en ella. Esto generó una gran cantidad de racionalización del ecosistema de microservicios con respecto al soporte y una mayor adopción de un entorno nativo del cloud. En este capítulo, hemos visto los diversos componentes y conceptos que permiten que Kubernetes funcione a escala. En él también se ha preparado el escenario para los próximos capítulos, en los que utilizaremos la plataforma Kubernetes para servir aplicaciones nativas en el cloud de producción.
Dada la complejidad subyacente de administrar un clúster de Kubernetes, en el capítulo 5 vamos a ver cómo crear y utilizar un clúster de este tipo. También vamos a ver Azure Kubernetes Service, entre otras cosas.