



Ahora que ya entiendes los conceptos básicos del funcionamiento de un clúster de Kubernetes por dentro, es el momento de poner a prueba ese conocimiento, y crear y utilizar un clúster de Kubernetes. Hay varias herramientas disponibles para crear y ejecutar un clúster de Kubernetes en un entorno de producción con alta disponibilidad. Algunas de las herramientas más comunes son kops, kubeadm, Kubespray y Rancher. Estas herramientas tienen cuadernos de trabajo previamente escritos sobre la creación de un clúster que se puede ejecutar en un entorno de producción sin problemas con una combinación de tecnologías.
No utilizaremos una herramienta precompilada en este capítulo. En lugar de ello, vamos a utilizar un enfoque más práctico para crear un clúster que puedas utilizar en un entorno de producción.
Creación de un clúster de Kubernetes desde cero
En esta sección, crearemos un clúster de Kubernetes desde cero usando Ansible, Terraform y Packer. Te mostraremos cómo crear el clúster manualmente para que entiendas mejor los distintos componentes del clúster. Aunque esta no es la forma preferida de crear o ejecutar un clúster de Kubernetes de producción, te proporcionará un buen conocimiento básico.
Para empezar, tendrás que clonar GitHub para este libro y abrir la carpeta Chapter5. En este capítulo, se supone que ya has configurado tu cuenta de Azure siguiendo los pasos del Capítulo 2 y que has experimentado con la creación de la infraestructura utilizando los cuadernos de trabajo de Terraform, Packer y Ansible.
Hemos organizado el código en el repositorio Git Chapter5 del siguiente modo:


En esta sección, solo usaremos K8S_Packer_Image, Ansible-Playbooks, Kuber netes_cluster y terraform_modules.
Creación del grupo de recursos
El primer paso es crear un grupo de recursos para todos los componentes de la infraestructura para así poder agruparlos. Con este fin, ve al directorio Chapter5/Kubernetes_Cluster/A-Resource_Group y ejecuta el siguiente comando:
$ terraform init
Después de inicializar, ejecuta lo siguiente para crear un grupo de recursos:

Para continuar, escribe yes. Esto creará un grupo de recursos denominado K8Scluster en la región eastus2 de Azure.
Creación de las imágenes de máquina de las máquinas de trabajo y controlador
El segundo paso es crear las imágenes de Packer de las imágenes de instancia de controlador y trabajo. En el directorio Chapter5/K8S_Packer_Image , actualiza controller.json y worker.json con las credenciales de Azure para client_id, client_secret, tenant_id y subscription_id. Ahora, ejecuta los siguientes comandos de packer:
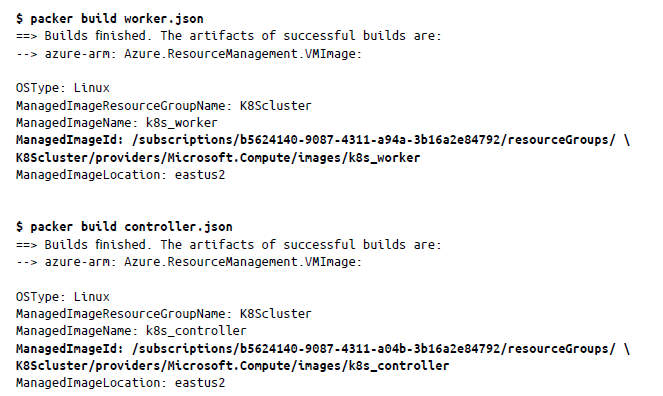
Anota el valor de ManagedImageId, que usaremos más adelante en el capítulo.
Creación de un backend de cuenta de almacenamiento
A continuación, crearemos la cuenta de almacenamiento para almacenar toda la asignación de infraestructura que usará Terraform. De nuevo, primero inicializaremos el repositorio con terraform init en Kubernetes_Cluster/B-Storage_Account_backend y después aplicaremos el siguiente comando:
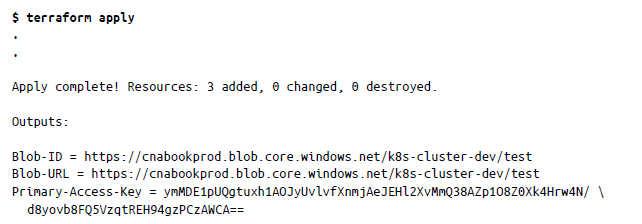
Esto creará una cuenta de almacenamiento con el nombre cnabookprod. Actualiza el bash_pro file con un valor de Primary-Access-Key usando el nombre de variable ARM_ACCESS_KEY:
Creación de una red virtual de Azure
El siguiente paso es crear la red virtual donde alojaremos nuestro clúster de Kubernetes. Ve al directorio Chapter5/Kubernetes_Cluster/C-Virtual_Network e inicializa de nuevo Terraform mediante terraform init. Una vez inicializado, aplica la siguiente configuración para crear una red virtual de Azure:
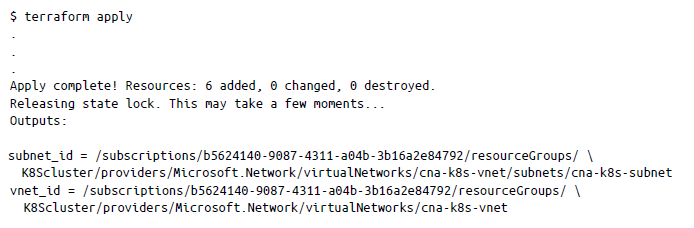
Esto creará una red virtual con el CIDR 10.240.0.0/24 llamada cnak-8s-vnet.
Creación de direcciones IP públicas para el equilibrador de carga
Ahora crearemos las direcciones IP públicas para el equilibrador de carga junto con todos los nodos de los planos de trabajo y de control. Una vez que hayamos creado las direcciones IP públicas para todos los recursos, crearemos el equilibrador de carga para los nodos del plano de control para exponer el servidor de API a los clientes remotos.
Para crear las direcciones IP públicas, ve al directorio Chapter5/Kubernetes_Cluster/D-K8S_PublicIP e inicializa Terraform mediante terraform init. El código se organizará de la siguiente manera:

Una vez inicializado Terraform, aplica la configuración mediante terraform apply de la siguiente manera, que creará las direcciones IP públicas:
El código anterior creará siete direcciones IP públicas: seis para las instancias de los nodos (trabajo y controlador) y una para el equilibrador de carga. Ahora podemos crear el equilibrador de carga y asociar la IP del equilibrador de carga yendo al directorio Chapter5/Kubernetes_Cluster/EK8S-API-Public-loadbalancer e inicializando Terraform. Después, podemos usar de nuevo terraform apply de la siguiente manera:
Este paso creará un equilibrador de carga y aplicará las reglas del equilibrador de carga que hemos predefinido en el archivo de configuración de Terraform.
Creación de instancias de trabajo y controlador
En este punto tenemos todo preparado para crear los nodos de instancia que constituirán nuestro clúster de Kubernetes. Vamos a crear un clúster de seis nodos en el que tres serán nodos de trabajo que ejecutarán la carga de trabajo real (pods, etc.) y tres formarán parte del plano de control.
Antes de hacer esto, tenemos que actualizar el archivo main.tf en el directorio /Chapter5/Kubernetes_ Cluster/F-K8S-Nodes/main.tf con el id. de imagen del nodo de trabajo y el nodo de controlador. Además, tenemos que actualizar la ruta de la ubicación de la clave de Secure Shell (SSH) que se usará para establecer una conexión ssh con las máquinas:
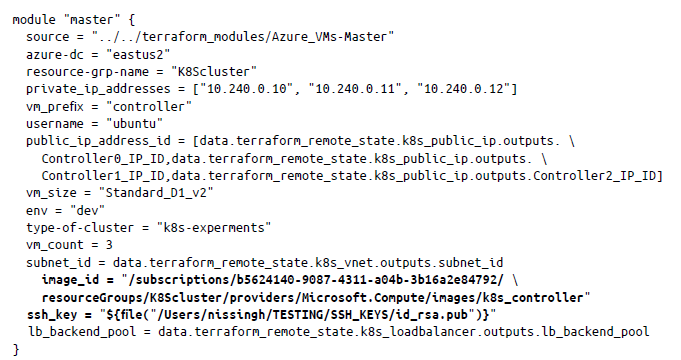
En la configuración anterior (main.tf), el id. de imagen se actualizó para el nodo de controlador (maestro) junto con la ruta a la clave SSH. Ahora puedes generar un par de claves SSH utilizando el comando ssh-keygen para ssh_key. Del mismo modo, puedes actualizar el archivo de configuración de trabajo y luego inicializar Terraform como antes. Una vez realizada la inicialización, puedes utilizar terraform apply para crear las instancias de trabajo y controlador:
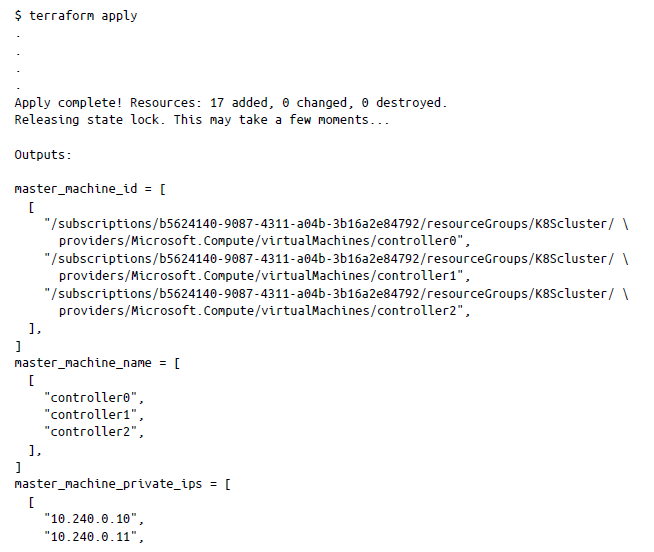
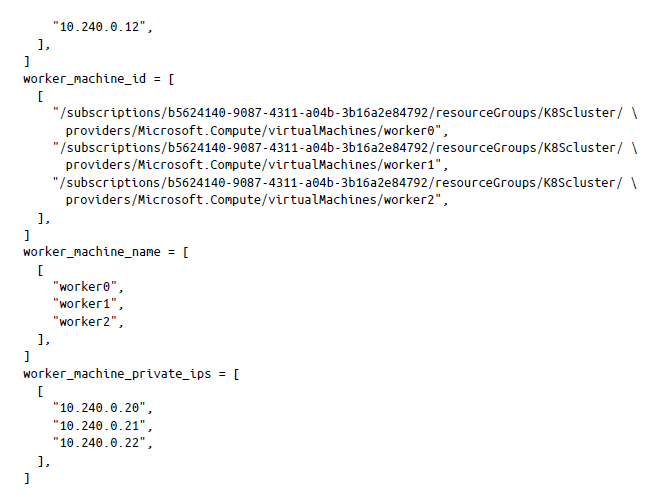
Una vez completada la aplicación terraform, verás que los nodos se han aprovisionado para tu clúster de Kubernetes (consulta la figura 5-1).
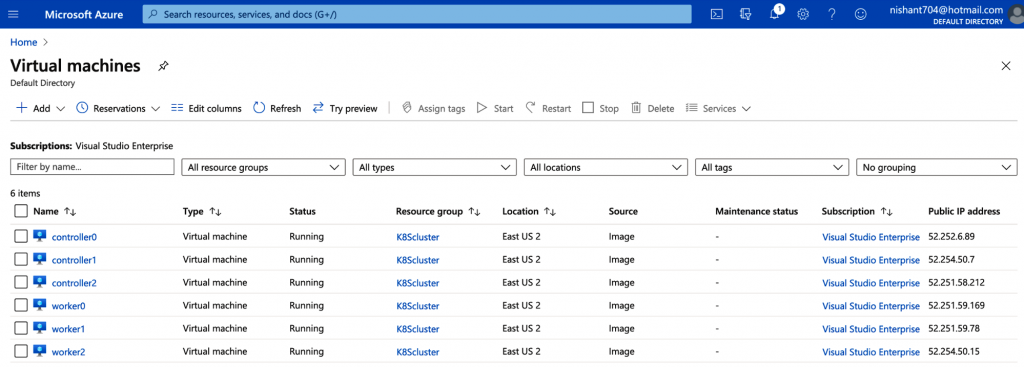
Uso de Ansible para implementar y configurar los nodos de controlador de Kubernetes
Una vez que la infraestructura está en funcionamiento, es el momento de configurar el clúster, ya que hasta ahora solo hemos preparado la estructura básica. Para implementar y configurar Kubernetes para que funcionen en el nodo, usaremos cuadernos de trabajo de Ansible.
En primer lugar, actualiza el archivo hosts en Chapter5/Ansible-Playbooks/hosts con las direcciones IP de las instancias de trabajo y controlador, junto con el nombre de usuario de SSH y la ruta de la clave privada de SSH que se generó con ssh-keygen:
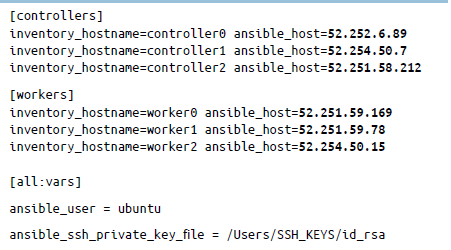
Una vez actualizado el archivo hosts, tenemos que actualizar el archivo groupvars (ubicado en el archivo all del directorio Chapter5/Ansible-Playbooks/group_vars) con la loadbalancer_public_ip y la clave de cifrado. Dado que Kubernetes almacena datos diversos, incluidos el estado del clúster, las configuraciones de replicación y los secretos, tenemos que cifrar estos datos en reposo. Kubernetes admite la capacidad de cifrar datos de clúster en reposo.
Para crear una clave de cifrado, solo tienes que enviar el siguiente comando en el terminal y pegar el secreto generado en el archivo group_vars/all de la siguiente manera:
$ head -c 32 /dev/urandom | base64
Uvivn+4ONy9yqRf0ynRVOpsEE7WsfyvYnM7VNakiNeA=
También deberás actualizar la IP del equilibrador de carga. El archivo group_vars final debería tener el aspecto siguiente:
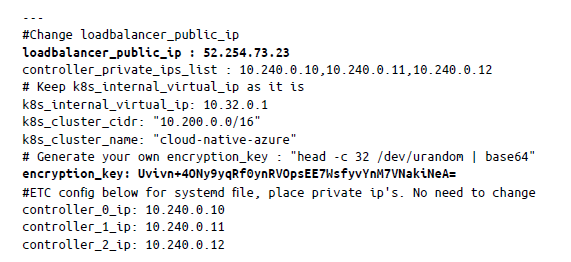
Una vez que hayamos terminado de actualizar los archivos, tenemos que instalar las herramientas del lado del cliente en el sistema local, principalmente kubectl, cfssl y cfssljson. CFSSL es el kit de herramientas de infraestructura de clave pública/Seguridad de la capa de transporte (PKI/TLS) de Cloudflare para firmar, verificar y agrupar los certificados TLS en general. Utilizaremos este kit de herramientas para generar el certificado TLS para los nodos de Kubernetes.

Esto completa la configuración de los nodos del controlador. Básicamente, con el cuaderno de trabajo controllers.yaml hemos arrancado los etcds y los nodos del controlador. El cuaderno de trabajo de Ansible contiene instrucciones paso a paso, que son evidentes, para arrancar los nodos del controlador del clúster. Te recomendamos encarecidamente que sigas las instrucciones del cuaderno de trabajo de la ruta de ejecución para entender la información más exhaustiva.
Uso de Ansible para implementar y configurar los nodos de trabajo de Kubernetes
Ahora que los nodos del controlador se han implementado, podemos implementar los nodos de trabajo mediante el archivo workers.yaml:

Esto implementará y configurará los nodos de trabajo con los binarios de Kubernetes necesarios.
Configuración de redes y enrutamiento de pods
Aún tenemos que configurar la red y el enrutamiento de pods para nuestro clúster. Para ello, primero tenemos que configurar la red entre los pods cambiando al directorio Chapter5/Kubernetes_Cluster/G-K8S-PodsNetwork y ejecutando terraform init:
$ terraform init
Una vez inicializado Terraform en el directorio, podemos ejecutar terraform apply:
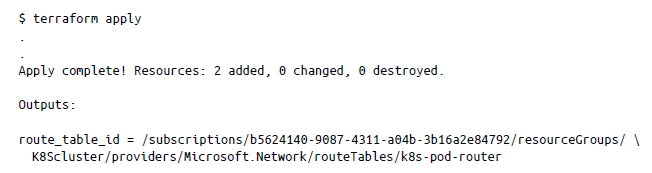
Esto configura la tabla de rutas de pods en Azure. Ahora, por fin podemos crear las rutas yendo al directorio final, Chapter5/Kubernetes_Cluster/H-k8S_Route-creation, e inicializando Terraform como antes. Una vez inicializado, podemos ejecutar terraform apply:
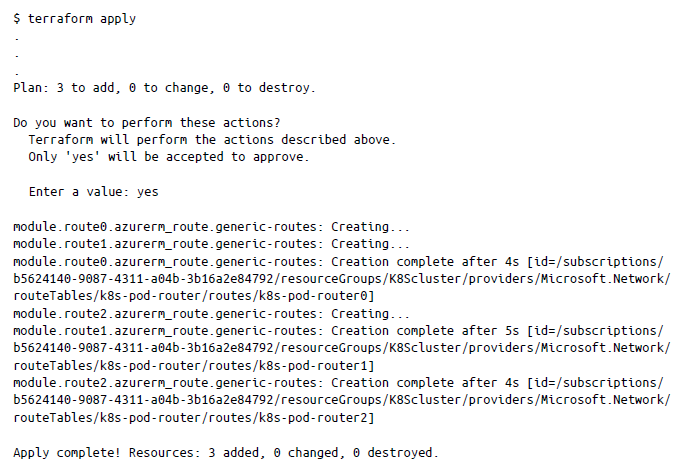
Esto completa la configuración de nuestra red para el clúster de Kubernetes.
Generación del archivo kubeconfig para acceso remoto y validación del clúster
Por último, tenemos que descargar el archivo kubeconfig para el clúster que hemos creado y probar si la configuración del clúster se ha realizado correctamente. Vuelve al directorio Ansible, Chapter5/Ansible-Playbooks, y ejecuta lo siguiente:
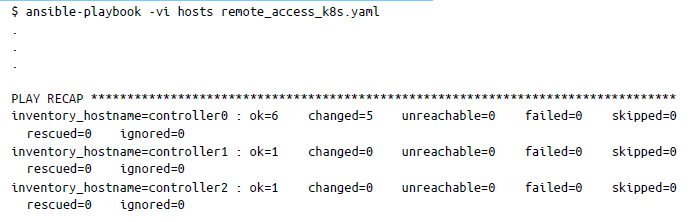
Esto descargará el archivo kubeconfig y lo almacenará localmente para que puedas acceder al clúster e interactuar con él. Comprueba si puedes hacerlo emitiendo kubectl get nodes desde tu máquina local de la siguiente manera:


El resultado presentará una lista con los nodos de trabajo del clúster. Ahora puedes utilizar este clúster para experimentar y explorar las funciones que hemos explicado en este capítulo. Por supuesto, este no es un clúster listo para producción, pero te ofrece una idea de cómo crear, ejecutar y mantener un clúster kubernetes desde cero.
Ahora que ya sabes cómo hacer esto de la manera difícil (semiautomatizada), echemos un vistazo a la forma preferida y sencilla de ejecutar un clúster de Kubernetes de producción en Azure.
Azure Kubernetes Service
Como has visto, el proceso de gestión y mantenimiento de un clúster de Kubernetes es complejo. Desde el punto de vista operativo, no se trata solo de ejecutar un clúster; se trata de la seguridad, el rendimiento, el registro, la actualización del clúster y la aplicación de parches, entre otras cosas. Para aliviar este problema, Azure ofrece una solución administrada denominada Azure Kubernetes Service o AKS.
AKS hace que el proceso de implementación y administración de un clúster de Kubernetes en Azure sea pan comido. Una solución de Kubernetes administrada por Azure elimina una gran parte del proceso de administración de Kubernetes para que lo único que tengas que hacer sea administrar tu aplicación. AKS ofrece varias ventajas, entre las que se incluyen las siguientes:
- Azure administra completamente la supervisión del estado de los clústeres.
- Las tareas de mantenimiento de los nodos subyacentes son responsabilidad de Azure.
- Azure administra y mantiene el plano de control y tú, como usuario, solo tienes que administrar los nodos de agente.
- AKS te permite la integración con Azure Active Directory y la API RBAC de Kubernetes para la seguridad y el control de acceso.
- Todos los registros de tu aplicación y clúster se almacenan en el espacio de trabajo de Azure Log Analytics.
- El escalador automático de pods horizontales (HPA) y el escalador automático del clúster son fáciles de usar para la configuración de un clúster de Kubernetes desde cero y el tratamiento de los permisos de recursos subyacentes.
- AKS ofrece soporte continuo para el volumen de almacenamiento
Ahora que ya conoces las ventajas de AKS, vamos a crear un clúster de AKS. Hay dos maneras sencillas de hacerlo: usar el portal de Azure (el modelo manual) o utilizar Terraform (el modelo automatizado).
Puedes navegar por la consola de Azure y comenzar a implementar tu clúster de AKS haciendo clic en el botón Agregar (Figura 5-2) y seguir a continuación las instrucciones que aparecen.
Otra opción es, en Terraform, ir al directorio de AKS del repositorio / cloud_ native_ azure/Chapter5/AKS y ejecutar el siguiente comando:
$ terraform apply
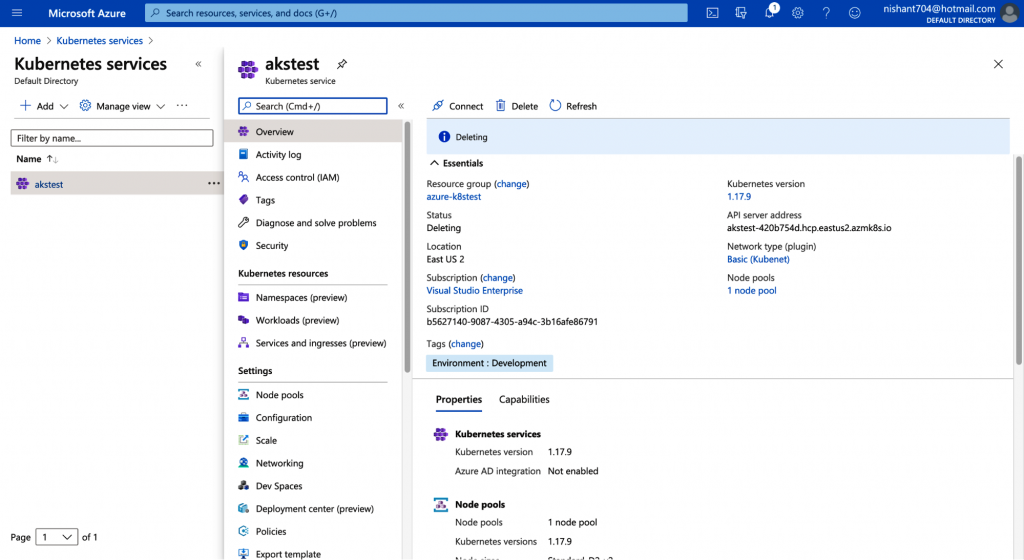
Haz clic en Aplicar y, en unos minutos, deberías tener un clúster de Kubernetes de tres nodos en funcionamiento (Figura 5-3).
Para descargar el archivo kubeconfig, puedes utilizar el comando de la CLI de Azure de tu sistema local para obtener credenciales de acceso para tu clúster de Kubernetes administrado de la siguiente manera:
az aks get-credentials –resource-group azure-k8stest –name akstest — file config
Tu kubeconfig se descargará con el nombre config; muévelo a la carpeta . kube . Ahora puedes usar este clúster del mismo modo que lo harías con el clúster que creaste de la manera difícil:
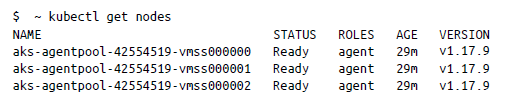
Aunque puedes crear cualquier recurso e implementar aplicaciones en este momento, obviamente no se trata de un clúster de producción. Existe un gran número de recursos online1 que pueden guiarte en la creación de clústeres de producción.
Con esta información, estamos listos para seguir adelante y estudiar las funciones de Helm, una herramienta que se utiliza fundamentalmente para optimizar la instalación y administración de aplicaciones de Kubernetes.
Implementación de aplicaciones y servicios mediante Helm: un administrador de paquetes de Kubernetes
Es probable que ya tengas claro que en Kubernetes son muchas las cosas a las que hay prestar atención. Aunque puedes utilizar un servicio administrado como Microsoft AKS, es difícil mantener implementaciones y ReplicaSets a medida que aumentan tus requisitos.
Helm es un administrador de paquetes de Kubernetes que permite capturar, implementar y administrar aplicaciones. Básicamente, Helm se encarga del mantenimiento de archivos YAML grandes, que tienen información sobre pods, ReplicaSets, servicios, configuración de RBAC, etc. Helm también ofrece reversiones, información de historial de versiones y enlaces de prueba integrados, lo que hace que sea muy fácil administrar el ciclo de vida completo de tus aplicaciones en un clúster de Kubernetes.
En este libro, estamos utilizando la versión estable de Helm, v3.3.1. Las versiones anteriores (es decir, v2) disponían de un componente de lado servidor denominado Tiller, que debía implementarse en el clúster de Kubernetes. Tiller poseía un riesgo potencial de seguridad debido a los amplios privilegios del usuario y a la sobrecarga de administración, lo que inicialmente provocó una menor tracción de Helm en la comunidad de usuarios. Al introducirse la API RBAC, Helm en la actualidad solo contiene binarios del extremo del cliente y Tiller ha sido eliminado por completo. En la figura 5-4 se ilustra el funcionamiento básico del administrador de paquetes Helm.
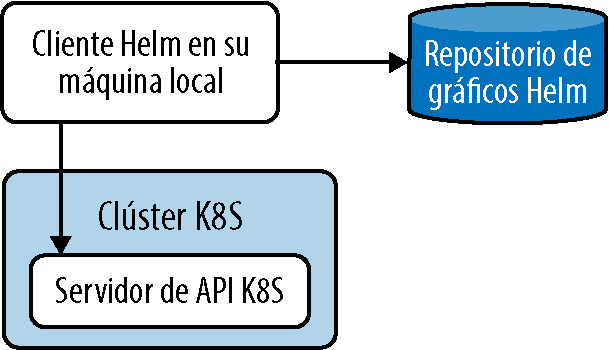
Conceptos básicos de Helm
El cliente Helm se instala como una utilidad de línea de comandos para el usuario final. La principal responsabilidad del cliente es ayudar en el desarrollo de gráficos y administrar repositorios y versiones. Helm consta de los siguientes componentes:
Gráfico
Los gráficos son los paquetes de Kubernetes que administra Helm. Los gráficos constan de toda la información necesaria para crear una aplicación en Kubernetes, incluidas las definiciones de recursos necesarias para ejecutar una aplicación o servicio en un clúster de Kubernetes.
Repositorio
Esta es la base de datos donde se almacenan todos los gráficos de Helm.
Configuración
Esta es la configuración que se puede combinar en un gráfico empaquetado para crear un objeto versionable.
Versión
Las versiones son una forma de realizar un seguimiento de todas las aplicaciones que Helm instala en el clúster de Kubernetes. Se puede instalar un solo gráfico varias veces y cada nueva instalación crea una nueva versión.
Instalación y administración de Helm
Puedes descargar la última versión del cliente Helm para tu equipo desde sus repositorios oficiales en https://github.com/helm/helm/releases.
Después de instalar Helm, tenemos que añadir un repositorio de gráficos desde el que se puedan descargar los paquetes. Google ofrece el repositorio de gráficos de Kubernetes, que se puede añadir de la siguiente manera:
$helm repo add stable https://kubernetes-charts.storage.googleapis.com/
Lo que hace Helm básicamente es extraer gráficos o paquetes de un repositorio central e instalarlos/liberarlos en el clúster de Kubernetes.
Búsqueda de repositorios Helm
Puedes buscar repositorios de Helm usando el comando helm search de dos maneras diferentes. La primera es buscar el repositorio que añadiste localmente (como en el paso anterior, cuando añadimos un repositorio estable):

Esta búsqueda se realiza en los datos locales de tu equipo.
La otra forma de buscar repositorios Helm es buscando en el Hub de Helm. El Hub de Helm consta de varios repositorios públicos disponibles, por lo que si no encuentras un gráfico en tu repositorio local, siempre puedes buscarlo en el hub. En el siguiente, hemos buscado todos los gráficos «kafka»:

Instalación de un gráfico Helm en Kubernetes
Para instalar un gráfico, puedes ejecutar el comando helm install de la siguiente manera:
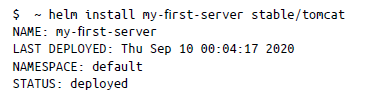

Aquí intentamos implementar un servidor Tomcat y el nombre de la versión que hemos elegido es my-first-server. Con kubectl, puedes comprobar los recursos que se crearon para el gráfico de Tomcat:

Cambio de los valores predeterminados de gráficos
A veces es posible que quieras personalizar un gráfico antes de instalarlo realmente. Para cambiar un valor de un gráfico predeterminado, primero debes ver el valor utilizando helm show values:
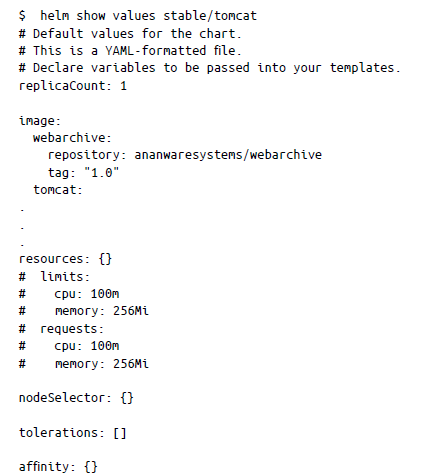
Para cambiar el valor, puedes utilizar el argumento –values o el argumento –set. La ventaja de usar el primero es que se puede especificar un archivo YAML que puedes pasar al instalar un gráfico. Esto invalida los valores de los gráficos. Por ejemplo, en el gráfico anterior, si queremos cambiar los valores predeterminados, podemos crear un archivo YAML de la siguiente manera y guardarlo como custom_vals.yaml

Para instalar los valores modificados, puedes hacer lo siguiente:
$ helm install –values custom_vals.yaml new-v2-install stable/tomcat
En la siguiente sección, analizaremos cómo administrar versiones en Helm.
Gestión de versiones de Helm
En la terminología de Helm, una versión es una instancia de un gráfico que se ejecuta en un clúster de Kubernetes. Un gráfico se puede instalar muchas veces en el mismo clúster, creándose una nueva versión cada vez que se instala. En esta sección, mostraremos cómo administrar las versiones de Helm.
Comprobación de una versión
Para encontrar el estado de la versión, puede usar helm status, que te facilitará información como, por ejemplo, el número de revisión y cuándo se implementó por última vez:
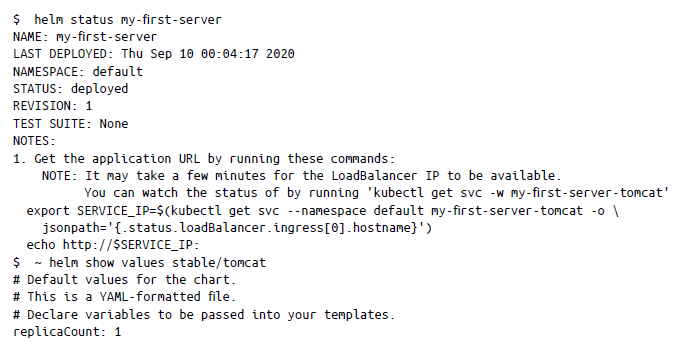
Actualización de una versión
Puedes utilizar helm upgrade para actualizar los gráficos instalados cuando se publica una nueva versión o si has realizado un cambio de configuración:
$ helm upgrade –values new_vals.yaml new-v2-install stable/tomcat
Esto actualizará new-v2-install con el mismo gráfico (stable/tomcat), pero puedes actualizar los nuevos valores en el archivo new_vals.yaml .
Revertir una versión
Si necesitas revertir un gráfico implementado (versión), solo tienes que usar la opción helm rollback de la siguiente manera:
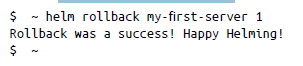
Aquí hemos revertido my-first-server a la versión 1.
Desinstalar una versión
Para eliminar permanentemente una versión del clúster, puedes usar helm uninstall:

Creación de gráficos para tus aplicaciones
Para crear un gráfico para tu aplicación, sigue el formato de empaquetado predeterminado proporcionado por Helm. Puedes utilizar los gráficos para implementar un pod simple o una pila completa de aplicaciones web que contenga servidores HTTP y bases de datos, entre otros. Los gráficos contienen una colección de archivos dentro de un directorio. La estructura del directorio es la siguiente, donde el nombre del directorio de nivel superior (nginx en este caso) es el nombre del gráfico:
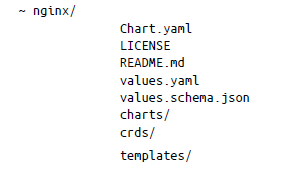
En el directorio, Helm espera que el archivo tenga la misma estructura y los mismos nombres, ya que son nombres reservados. Cada elemento del directorio tiene un propósito específico:
- Chart.yaml contiene toda la información sobre el gráfico en formato YAML.
- LICENSE es un archivo opcional de texto sin formato que contiene la licencia del gráfico.
- README.md es un archivo README legible para una persona.
- values.yaml contiene todos los valores de configuración predeterminados del gráfico.
- values.schema.json es un archivo de esquema JSON opcional que impone una estructura en values.yaml.
- charts/ incluye todos los gráficos dependientes de los que depende el gráfico actual.
- crds/ contiene definiciones de recursos personalizadas.
- templates/ es el directorio que contiene plantillas, que se pueden combinar con valores para generar archivos de manifiesto de Kubernetes.
El archivo Chart.yaml es necesario para crear el gráfico y contiene los siguientes campos:


Resumen
En este capítulo has aprendido a crear un clúster de Kubernetes, tanto manualmente desde cero con Azure como mediante Azure AKS como servicio administrado. También hemos explorado Helm, que actúa como administrador de paquetes de Kubernetes y te ayuda a crear y administrar tus aplicaciones con una sola plantilla.
Antes de seguir, queremos hacer hincapié en que Kubernetes es difícil de administrar sin ayuda (especialmente en producción), y sin duda no es una solución milagrosa para resolver todas las dificultades de administrar aplicaciones en entornos nativos en el cloud. Dada la complejidad subyacente de administrar un clúster de Kubernetes, es evidente que un enfoque como AKS es un método mejor de administrar los servicios que se ejecutan en clústeres de Kubernetes. Con AKS, no tienes que preocuparte por la infraestructura subyacente o las partes móviles del ecosistema, ya que están resueltos la mayoría de los puntos críticos, como la alta disponibilidad y la redundancia del clúster de Kubernetes.
Dicho esto, pasemos al capítulo 6, que trata sobre cómo permitir la observabilidad en sistemas distribuidos y sobre cómo ayudar a que tus aplicaciones nativas en el cloud sean más fiables