



Randomized Cross‑Validation: How It Works and When to Use It in Machine Learning
When training a Machine Learning model, it’s not just about how we split the data, but also how we vary those splits to get a more robust evaluation. Classic k-fold cross-validation is a great tool, but sometimes we need something more flexible and less rigid. That’s where randomized cross-validation comes in.
What is randomized cross-validation?
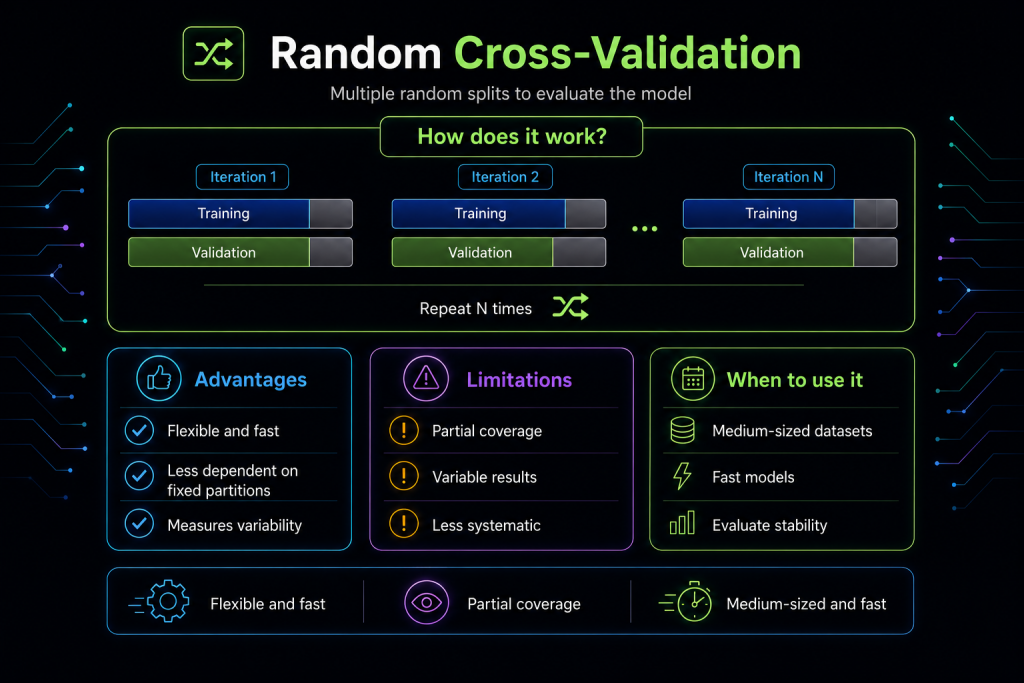
Randomized Cross-Validation consists of generating multiple random partitions of the dataset and evaluating the model on each one. Instead of dividing the data into k fixed folds, N independent random splits are created, each with its own training and validation set.
It’s similar to the hold-out method, but repeated many times with different partitions in each iteration.
Why use it?
Because it introduces controlled variability. Each random split offers a different perspective on model performance, which allows you to:
- Measure model stability
- Detect dependencies on specific partitions
- Obtain more representative metrics on medium-sized or noisy datasets
Advantages
Flexible: doesn’t depend on a fixed number of folds.
Fast: lighter than LOOCV and, in many cases, faster than k-fold.
Robust: by repeating several random partitions, it reduces the risk of an unfortunate split.
Ideal for fast models: allows many iterations without great cost.
Limitations
No complete coverage guarantee: some observations may never appear in validation.
Variable results: depend on the number of repetitions and the random seed.
Less systematic than k-fold: doesn’t ensure balanced use of all samples.
When should you use it?
This technique is especially useful when:
- The dataset is medium-sized and you don’t want the computational cost of k-fold
- The model is fast to train and you can afford several repetitions
- You want to measure performance variability
- You’re looking for a more flexible alternative to traditional hold-out
Conceptual example
If you choose 10 repetitions with an 80/20 split:
- Each iteration generates a random 80% training / 20% validation partition
- The model is trained and evaluated 10 times
- Final metrics are obtained by averaging the results
Comparison with other techniques
| Technique | Idea | Advantage | Limitation | Best scenario |
|---|---|---|---|---|
| Hold-out | Single split | Fast | Unstable | Large datasets |
| K-Fold CV | K fixed splits | Stable | More costly | Small/medium datasets |
| Randomized CV | Multiple random splits | Flexible and fast | Less systematic | Medium datasets |
| LOOCV | Leave one out | Maximum precision | Very slow | Very small datasets |
Conclusion
Randomized cross-validation is an intermediate technique between hold-out and classic cross-validation: more flexible than k-fold, more robust than a single partition, and less costly than LOOCV.
It’s a technique that many overlook, but it can make a difference in real projects. If you’re looking for a balance between speed, variability, and robustness, it’s an excellent option for evaluating your Machine Learning models.
TL;DR
- Randomized CV = multiple random partitions
- More flexible than k-fold, more robust than hold-out
- Ideal for medium datasets and fast models
- Doesn’t guarantee complete coverage, but offers good stability