En el capítulo anterior, has aprendido las diversas estrategias de seguridad que se pueden implementar en Azure. Con una aplicación segura, gestionamos grandes cantidades de datos. El Big Data ha obtenido una mayor relevancia en los últimos años. Requiere el uso de almacenamiento, software y herramientas especializadas. Curiosamente, hace unos años, estas herramientas, plataformas y opciones de almacenamiento no estaban disponibles en forma de servicio. Sin embargo, con la nueva tecnología de cloud, Azure proporciona numerosas herramientas, plataformas y recursos para crear fácilmente soluciones de Big Data. En este capítulo se detallará la arquitectura completa para ingerir, limpiar, filtrar y visualizar los datos de manera inteligente.
En este capítulo, abordaremos los siguientes temas:
- Información general sobre Big Data
- Integración de datos
- Extracción, transformación y carga (ETL)
- Data Factory
- Data Lake Storage
- Ecosistemas de herramientas como Spark, Databricks y Hadoop
- Databricks
Big Data
Con la afluencia de dispositivos baratos, como los dispositivos del Internet de las cosas
y los dispositivos portátiles, la cantidad de datos que se generan y capturan ha aumentado
exponencialmente. Casi todas las organizaciones tienen una gran cantidad de datos y están
listas para comprar más si es necesario. Cuando llegan grandes cantidades de datos en
diferentes formatos y con una frecuencia cada vez mayor, podemos decir que estamos
tratando con Big Data. En resumen, hay tres características clave del Big Data:
- Volumen: por volumen, nos referimos a la cantidad de datos tanto en términos de
tamaño (en GB, TB y PB, por ejemplo) como en el número de registros (como en un
millón de filas de un almacén de datos jerárquico, 100 000 imágenes, medio millar
de millones de documentos JSON, etc.). - Velocidad: la velocidad hace referencia a la velocidad a la que llegan o se ingieren
los datos. Si los datos no cambian con frecuencia o no llegan con frecuencia, se dice
que la velocidad de los datos es baja, mientras que si hay actualizaciones frecuentes
y muchos datos nuevos llegan de forma continua con frecuencia, se dice que tienen
alta velocidad. - Variedad: variedad se refiere a diferentes tipos y formatos de datos. Los datos
pueden proceder de diferentes orígenes en diferentes formatos. Los datos pueden
llegar como datos estructurados (archivos separados por comas, archivos JSON
o datos jerárquicos), como bases de datos semiestructuradas (documentos NoSQL sin
esquema) o como datos no estructurados (objetos grandes binarios [blobs], imágenes,
archivos PDF, etc.). Con tantas variantes, es importante tener un proceso definido
para procesar los datos ingeridos.
En la siguiente sección, examinaremos el proceso general de Big Data.
Procesar Big Data
Cuando los datos proceden de múltiples orígenes en diferentes formatos y a diferentes
velocidades, es importante establecer un proceso de almacenamiento, integración, filtrado
y limpieza de datos de una manera que nos ayude a trabajar con ellos con mayor facilidad
y hacer que los datos sea útiles para otros procesos. Tiene que haber un proceso bien
definido para administrar los datos. El proceso general de Big Data que debe seguirse
se muestra en la Figura 9.1:

Hay cuatro etapas principales del procesamiento de Big Data. Analicémoslas en detalle:
- Adquirir: este es el proceso de incorporar e ingerir datos en el entorno de Big Data.
Los datos pueden proceder de varios orígenes y se deben usar conectores para ingerir
los datos dentro de la plataforma de Big Data. - Almacenar: después de la ingesta, los datos deben almacenarse en el grupo de datos
para un almacenamiento a largo plazo. El almacenamiento debe estar disponible
para datos tanto históricos como en tiempo real y debe ser capaz de almacenar
datos estructurados, semiestructurados y no estructurados. Debe haber conectores
para leer los datos de los orígenes de datos o los orígenes de datos deben ser capaces
de enviar datos al almacenamiento. - Analizar: una vez que se leen los datos del almacenamiento, se deben analizar,
un proceso que requiere filtrar, agrupar, unir y transformar los datos para recopilar
conocimientos. - Visualizar: el análisis se puede enviar como informes utilizando varias plataformas
de notificación o usarse para generar paneles con tablas y gráficos.
Anteriormente, las herramientas necesarias para capturar, ingerir, almacenar y analizar
Big Data no estaban disponibles para las organizaciones ya que conllevaban un hardware
caro y grandes inversiones. Además, no había ninguna plataforma disponible para
procesarlos. Con la llegada del cloud, a las organizaciones les resulta más fácil capturar,
ingerir, almacenar y realizar análisis de Big Data utilizando sus herramientas y marcos
preferidos. Pueden pagar al proveedor del cloud para que use su infraestructura y evitar
gastos de capital. Además, el coste del cloud es muy barato en comparación con cualquier
solución on-premises.
El Big Data exige una inmensa cantidad de recursos de computación, almacenamiento y
red. En general, no resulta práctico tener todos los recursos necesarios en un solo equipo o
servidor. Incluso si, de alguna manera, se dispone de suficientes recursos en un solo servidor,
el tiempo que se tarda en procesar todo un grupo de Big Data es considerablemente grande,
ya que cada trabajo se realiza secuencialmente y cada paso tiene una dependencia con
el paso anterior. Es necesario tener marcos y herramientas especializados que puedan
distribuir el trabajo a través de varios servidores y, finalmente, devolver los resultados
de ellos y presentarlos al usuario después de combinar adecuadamente los resultados
de todos los servidores. Estas herramientas son herramientas especializadas de Big Data
que ayudan a lograr la disponibilidad, escalabilidad y distribución «out of the box» para
garantizar que una solución de Big Data pueda optimizarse para ejecutarse rápidamente
con solidez y estabilidad integradas.
Los dos servicios destacados de Big Data de Azure son HD Insights y Databricks. Avancemos
y analicemos las diversas herramientas disponibles en el panorama del Big Data.
Herramientas de Big Data
Hay numerosas herramientas y servicios en el panorama del Big Data y vamos a hablar
de algunas de ellas en este capítulo.
Azure Data Factory
Azure Data Factory es el servicio ETL insignia de Azure. Define los datos entrantes
(en términos de su formato y esquema), los transforma según las reglas y filtros de
negocio, potencia los datos existentes y, por último, transfiere los datos a un almacén
de destino que otros servicios posteriores pueden consumir fácilmente. Es capaz de
ejecutar canalizaciones (que contienen lógica ETL) en Azure, así como una infraestructura
personalizada, y también puede ejecutar paquetes de SQL Server Integration Services.
Azure Data Lake Storage
Azure Data Lake Storage es un almacenamiento de Big Data de nivel empresarial resistente,
altamente disponible y seguro «out of the box». Es compatible con Hadoop y puede escalarse
a petabytes de almacenamiento de datos. Se basa en las cuentas de almacenamiento de Azure
y, por lo tanto, obtiene directamente todas las ventajas de la cuenta de almacenamiento.
La versión actual se llama Gen2, después de combinar las capacidades de Azure Storage
y Data Lake Storage Gen1.
Hadoop
Hadoop fue creado por la fundación de software Apache y es una plataforma distribuida,
escalable y fiable para el procesamiento de Big Data que divide el Big Data en fragmentos
más pequeños de datos y los distribuye dentro de un clúster. Un clúster Hadoop consta
de dos tipos de servidores: nodos maestros y esclavos. El servidor maestro contiene los
componentes administrativos de Hadoop, mientras que los esclavos son aquellos en los
quese produce el procesamiento de datos. Hadoop es responsable de los datos de partición
lógicos entre esclavos; realiza toda la transformación de los datos, recopila conocimientos
y los devuelve a los nodos maestros que los recopilarán para generar el resultado final.
Hadoop puede escalarse a miles de servidores y cada servidor proporciona computación
y almacenamiento para los trabajos. Hadoop está disponible como servicio mediante
el servicio HDInsight en Azure.
Hay tres componentes principales que conforman el sistema central de Hadoop:
HDFS: Hadoop Distributed File System es un sistema de archivos para el
almacenamiento de Big Data. Es un marco distribuido que ayuda a descomponer
grandes archivos de Big Data en fragmentos más pequeños y colocarlos en diferentes
esclavos en un clúster. HDFS es un sistema de archivos tolerante a errores. Esto
significa que, aunque los diferentes fragmentos de datos estén disponibles para
diferentes esclavos del clúster, también existe la replicación de datos entre los
esclavos para garantizar que, en caso de que se produzca un fallo del esclavo,
estos datos también estarán disponibles en otro servidor. También proporciona
al solicitante un acceso rápido y eficiente a los datos.
MapReduce: MapReduce es otro marco importante que permite que Hadoop procese
datos en paralelo. Este marco de trabajo es responsable de procesar datos almacenados
dentro de los esclavos HDFS y de asignarlos a los esclavos. Una vez los esclavos han
terminado el procesamiento, la parte «reduce» (reducir) reúne la información de cada
esclavo y la recopila como resultado final. Por lo general, tanto HDFS como MapReduce
están disponibles en el mismo nodo, de modo que los datos no tienen que viajar entre
los esclavos y se puede lograr una mayor eficiencia al procesarlos.
YARN : Yet Another Resource Negotiator (YARN) es un componente arquitectónico de
Hadoop importante que ayuda a programar trabajos relacionados con las aplicaciones
y la administración de recursos dentro de un clúster. YARN se lanzó como parte
de Hadoop 2.0, y muchos la consideraron como la sucesora de MapReduce, ya que
es más eficiente en términos de procesamiento por lotes y asignación de recursos.
Apache Spark
Apache Spark es una plataforma de análisis distribuida y fiable para el procesamiento
de datos a gran escala. Proporciona un clúster que es capaz de ejecutar trabajos de
transformación y machine learning en grandes cantidades de datos en paralelo y devolver
un resultado consolidado al cliente. Se compone de nodos maestros y de trabajo, donde los
nodos maestros son responsables de dividir y distribuir las acciones dentro de los trabajos
y datos entre nodos de trabajo, así como de consolidar los resultados de todos los nodos de
trabajo y devolver los resultados al cliente. Un aspecto importante que debemos recordar
durante el uso de Spark es que la lógica o los cálculos deben paralelizarse con facilidad y
que la cantidad de datos es demasiado grande para caber en una sola máquina. Spark está
disponible en Azure como un servicio de HDInsight y Databricks.
Databricks
Databricks se basa en Apache Spark. Es una plataforma como servicio donde un clúster de
Spark administrado se pone a disposición de los usuarios. Proporciona muchas características
añadidas, como un portal completo para administrar el clúster de Spark y sus nodos, además
de ayudar a crear blocs de notas, programar y ejecutar trabajos y proporcionar seguridad
y soporte para varios usuarios.
Ahora es el momento de aprender a integrar datos de varios orígenes y trabajar con ellos
con las herramientas de las que hemos estado hablando.
Integración de datos
Somos conscientes de cómo se utilizan los patrones de integración para las aplicaciones.
Las aplicaciones se componen de múltiples servicios y se integran mediante el uso de
distintos de patrones. Sin embargo, otro paradigma es un requisito clave para muchas
organizaciones. Se denomina integración de datos. El auge de la integración de datos
se ha producido sobre todo en la última década, cuando la generación y disponibilidad
de los datos se han vuelto increíblemente altas. La velocidad, variedad y volumen de los
datos generados han aumentado drásticamente. Hay datos en prácticamente cualquier sitio.
Cada organización tiene muchos tipos diferentes de aplicaciones y todas generan datos
con sus formatos exclusivos. Con frecuencia, los datos también se compran en el mercado.
Incluso durante las fusiones y uniones de las organizaciones, los datos deben migrarse
y combinarse.
La integración de datos hace referencia al proceso de obtener datos de múltiples fuentes
y generar una nueva información de salida con mayor significado y facilidad de uso.
Existe una necesidad evidente de integración de datos en las siguientes situaciones:
- Migración de datos desde un origen o un grupo de orígenes hasta un destino final.
Esto es necesario para que los datos estén disponibles en diferentes formatos para
distintas partes interesadas y consumidores. - Obtención de conocimientos de cualquier dato. Con el rápido aumento de la
disponibilidad de los datos, las organizaciones quieren obtener información de ellos.
Quieren crear soluciones que proporcionen conocimientos y los datos de distintos
orígenes se deben combinar, limpiar, aumentar y almacenar en un almacén de datos. - Generación de informes y paneles en tiempo real.
- Creación de soluciones de análisis.
La integración de aplicaciones tiene un comportamiento de tiempo de ejecución cuando
los usuarios consumen la aplicación (por ejemplo, en el caso de la validación e integración
de tarjetas de crédito). Por otro lado, la integración de datos es un ejercicio de back-end
que no se vincula directamente a la actividad del usuario.
Vamos a seguir describiendo el proceso ETL con Azure Data Factory.
ETL
Un proceso muy popular conocido como ETL (extracción, transformación y carga)
ayuda a crear un origen de datos de destino para albergar datos que pueden consumir las
aplicaciones. Por lo general, los datos están en un formato sin procesar y para que puedan
consumirse, deben pasar por las siguientes tres fases:
- Extracción: durante esta fase, los datos se extraen de distintas ubicaciones. Por
ejemplo, puede haber varios orígenes y todos deben estar conectados entre sí para
recuperar los datos. Las fases de extracción suelen utilizar conectores de datos que
constan de información de conexión relacionada con el origen de datos de destino.
También pueden tener almacenamiento temporal para obtener los datos de la fuente
y almacenarlos para una recuperación más rápida. En esta fase se produce la ingesta
de los datos. - Transformación: es posible que las aplicaciones no puedan consumir directamente
losdatos que están disponibles después de la fase de extracción. Esto podría deberse
a distintas razones. Por ejemplo, los datos pueden tener irregularidades, es posible que
falten datos o que haya datos erróneos. Incluso puede haber datos que no son necesarios.
Asimismo, el formato de los datos podría no ser adecuado para que lo consuman
las aplicaciones de destino. En todos estos casos, se debe aplicar la transformación
a los datos para que las aplicaciones los puedan consumir de manera eficiente. - Carga: después de la transformación, los datos deben cargarse en el origen de datos
de destino con un formato y un esquema que permita una disponibilidad más rápida,
sencilla y centrada en el rendimiento para las aplicaciones. Una vez más, suele constar
de conectores de datos para los orígenes de datos de destino y la carga de datos en
los mismos.
A continuación, vamos a ver cómo se relaciona Azure Data Factory con el proceso ETL.
Introducción de Azure Data Factory
Azure Data Factory es una herramienta fácil de usar, completamente administrada y de
alta disponibilidad y escalabilidad para crear soluciones de integración e implementar fases
de ETL. Data Factory ayuda a crear nuevas canalizaciones mediante el gesto de arrastrar
y soltar con una interfaz de usuario y sin necesidad de escribir código. Aun así, proporciona
características que permiten escribir código en el lenguaje que elijas.
Antes de usar el servicio Data Factory, es necesario dejar claros unos conceptos
importantes, que exploraremos con más detalle en las siguientes secciones:
- Actividades: las actividades son tareas individuales que permiten la ejecución
y el procesamiento de la lógica dentro de una canalización de Data Factory. Existen
varios tipos de actividades. Hay actividades relacionadas con el movimiento de datos,
la transformación de datos y actividades de control. Cada actividad tiene una política
mediante la cual se pueden decidir el mecanismo y el intervalo de reintento. - Canalizaciones: las canalizaciones de Data Factory se componen de grupos de
actividades y se encargan de reunir las actividades. Las canalizaciones son los flujos
de trabajo y los orquestadores que permiten la ejecución de las fases de ETL. Las
canalizaciones permiten enlazar las actividades y la declaración de dependencias
entre ellas. Mediante el uso de dependencias, es posible ejecutar algunas tareas
en paralelo y otras secuencialmente. - Conjuntos de datos: los conjuntos de datos son los orígenes y los destinos de los
datos. Podrían ser cuentas de Azure Storage, Data Lake Storage y otros orígenes. - Servicios vinculados: contienen la información de conectividad y conexión de
los conjuntos de datos. Las tareas individuales los utilizan para conectarse a ellos. - Entorno de ejecución de integración: se trata del motor principal responsable de
la ejecución de Data Factory. El entorno de ejecución de integración está disponible
en las tres configuraciones siguientes: - Azure: en esta configuración, Data Factory se ejecuta en los recursos de computación
que proporciona Azure. - Autohospedado: Data Factory, en esta configuración, se ejecuta cuando se utilizan los recursos de computación propios. Esto podría producirse en servidores de máquina virtual on-premises o basados en el cloud.
- Azure SQL Server Integration Services (SSIS): esta configuración permite
la ejecución de paquetes SSIS tradicionales escritos con SQL Server. - Versiones: Data Factory tiene dos versiones diferentes. Es importante comprender
que todos los desarrollos nuevos se producirán en la V2 y que la V1 permanecerá tal
cual o se eliminará en algún momento. Se recomienda la V2 por las siguientes razones:
– Permite ejecutar paquetes de integración de SQL Server.
– Tiene funcionalidades mejoradas en comparación con la V1.
– Dispone de supervisión mejorada, que no incluye la V1.
Ahora que conoces bien Data Factory, vamos a describir las diversas opciones
de almacenamiento disponibles en Azure.
Introducción de Azure Data Lake Storage
Azure Data Lake Storage proporciona almacenamiento para soluciones de Big Data.
Se ha diseñado especialmente para almacenar las grandes cantidades de datos que
se suelen necesitar en soluciones de Big Data. Es un servicio administrado de Azure.
Los clientes solo deben aportar sus datos y almacenarlos en Data Lake.
Existen dos versiones de Azure Data Lake Storage: la versión 1 (Gen1) y la actual, la versión
2 (Gen2). Gen2 tiene toda la funcionalidad de Gen1, pero con la diferencia de que se basa
en Azure Blob Storage.
Puesto que Azure Blob Storage ofrece una alta disponibilidad, se puede replicar varias veces,
está preparado para desastres y tiene un coste bajo, estas ventajas se transfieren a Data
Lake Gen2. Data Lake puede almacenar cualquier tipo de datos, incluidos datos relacionales,
no relacionales, basados en sistemas de archivos y jerárquicos.
La creación de una instancia de Data Lake Gen2 es tan sencilla como crear una nueva
cuenta de almacenamiento. El único cambio necesario es habilitar el espacio de nombres
jerárquico desde la pestaña Opciones avanzadas de la cuenta de almacenamiento.
Es importante tener en cuenta que no hay ninguna migración o conversión directas desde
una cuenta de almacenamiento general hasta Azure Data Lake Storage o viceversa. Además,
las cuentas de almacenamiento son para almacenar archivos, mientras que Data Lake está
optimizado para leer e ingerir grandes cantidades de datos.
A continuación, examinaremos el proceso y las fases principales mientras trabajamos con
Big Data. Se trata de fases distintas y cada una es responsable de las diferentes actividades
sobre los datos.
Migrar datos de Azure Storage a Data Lake Storage Gen2
En esta sección, migraremos datos de Azure Blob Storage a otro contenedor de Azure de
la misma instancia de Azure Blob Storage. También migraremos datos a una instancia de
Azure Data Lake Storage Gen2 mediante una canalización de Azure Data Factory. En las
secciones siguientes se indican los pasos necesarios que hay que realizar para crear una
solución integral.
Preparar la cuenta de almacenamiento de origen
Antes de poder crear canalizaciones de Azure Data Factory y usarlas para la migración,
debemos crear una nueva cuenta de almacenamiento con una serie de contenedores
y cargar los archivos de datos. En una situación real, estos archivos y la conexión de
almacenamiento ya estarían preparados. El primer paso para crear una nueva cuenta
de Azure Storage es crear un nuevo grupo de recursos o elegir un grupo de recursos
existente en una suscripción de Azure.
Aprovisionar un nuevo grupo de recursos
Todos los recursos de Azure se asocian a un grupo de recursos. Antes de aprovisionar una
cuenta de almacenamiento de Azure, debemos crear un grupo de recursos que hospedará
la cuenta de almacenamiento. A continuación, se ofrecen los pasos para crear un grupo de
recursos. Debe tenerse en cuenta que un nuevo grupo de recursos se puede crear mientras
se aprovisiona una cuenta de Azure Storage y que también se puede utilizar un grupo de
recursos existente:
- Dirígete a Azure Portal, inicia sesión y haz clic en + Crear un recurso y,
a continuación, busca Grupo de recursos. - Selecciona Grupo de recursos en los resultados de búsqueda y crea un nuevo grupo
de recursos. Proporciona un nombre y elige la ubicación adecuada. Ten en cuenta que
todos los recursos se deben hospedar en el mismo grupo de recursos. Selecciona una
ubicación para que sea fácil eliminarlos.
Después de aprovisionar el grupo de recursos, aprovisionaremos una cuenta
de almacenamiento dentro de él.
Aprovisionar una cuenta de almacenamiento
En esta sección, vamos a seguir los pasos necesarios para crear una nueva cuenta de
Azure Storage. Esta cuenta de almacenamiento recuperará el origen de datos desde el
que se migrarán los datos. Sigue estos pasos para crear una cuenta de almacenamiento:
- Haz clic en + Crear un recurso y busca Cuenta de almacenamiento. Selecciona Cuenta
de almacenamiento en los resultados de la búsqueda y, a continuación, crea una nueva
cuenta de almacenamiento. - Proporciona un nombre y una ubicación y, a continuación, selecciona una
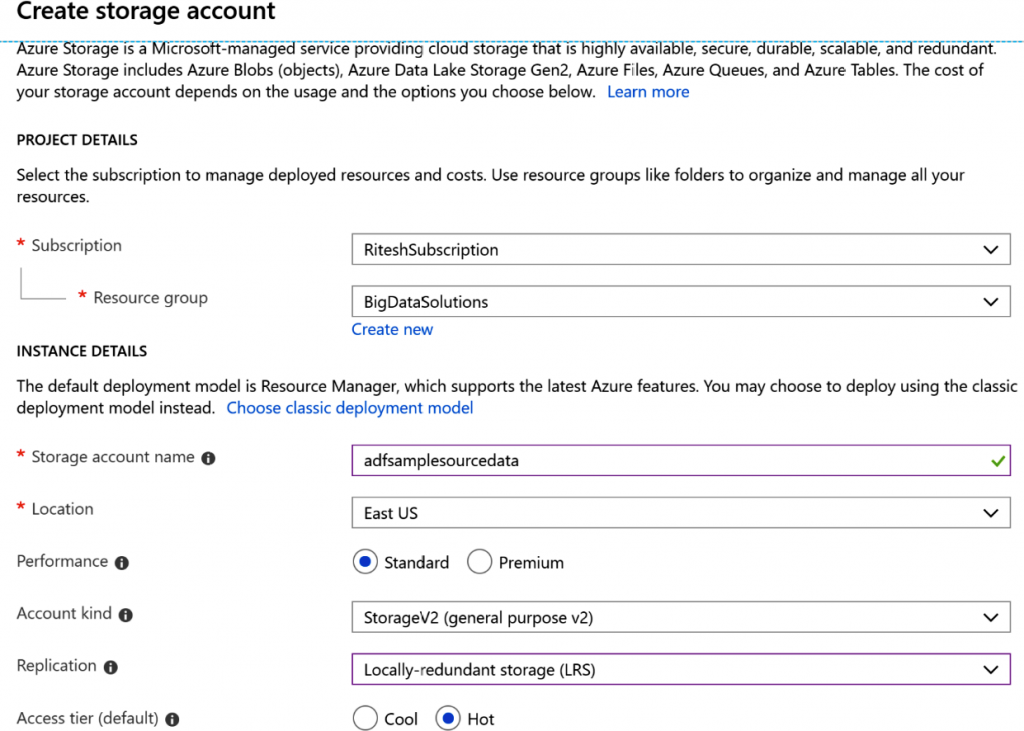
suscripción basada en el grupo de recursos que hemos creado anteriormente. - Selecciona StorageV2 (uso general v2) para Tipo de cuenta, Estándar para Rendimiento
y Almacenamiento con redundancia local (LRS) para Replicación, tal como se indica en
la Figura 9.2:
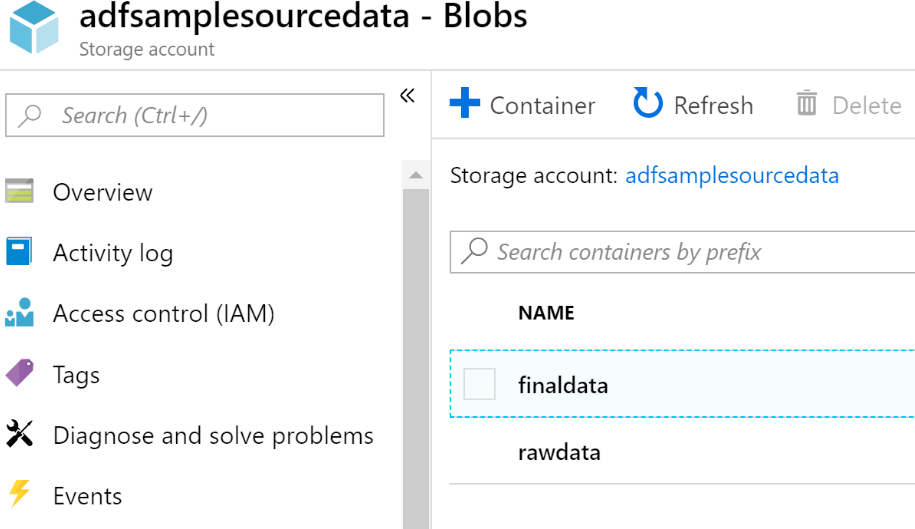
- Crea un par de contenedores dentro de la cuenta de almacenamiento. El contenedor
rawdata contiene los archivos que extraerá la canalización de Data Factory y actuará
como conjunto de datos de origen, mientras que finaldata contiene los archivos
en los que las canalizaciones de Data Factory escribirán los datos y actúa como
el conjunto de datos de destino:
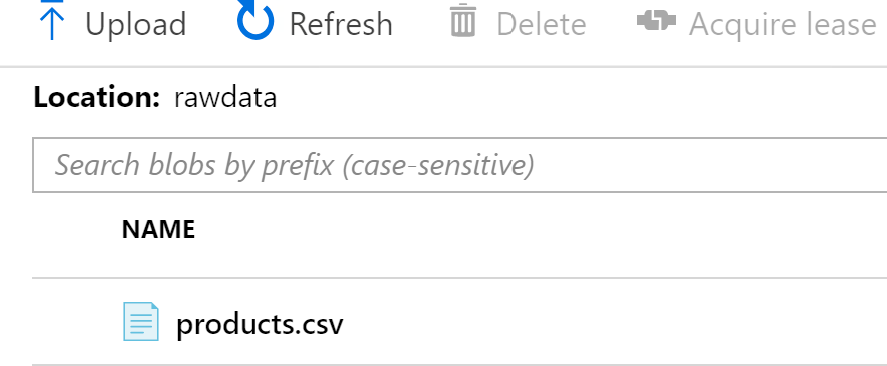
- Carga un archivo de datos (disponible con el código fuente) en el contenedor rawdata,
tal como se muestra en la Figura 9.4:
Después de completar estos pasos, se completan las actividades de preparación de los datos
de origen. Ahora podemos centrarnos en crear una instancia de Data Lake.
Aprovisionar el servicio Data Lake Gen2
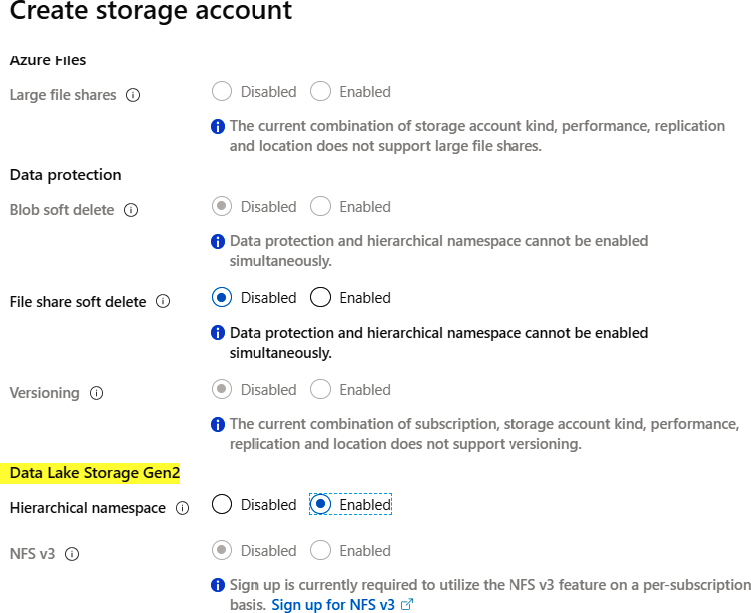
Como ya sabemos, el servicio Data Lake Gen2 se basa en la cuenta de Azure Storage.
Por ello, vamos a crear una nueva cuenta de almacenamiento de la misma manera que
lo hicimos antes. La única diferencia es la selección de Habilitado en Espacio de nombres
jerárquico en la pestaña Opciones avanzadas de la nueva cuenta de Azure Storage. De esta
forma se creará el nuevo servicio de Data Lake Gen2:
Después de la creación del data lake, nos centraremos en crear una nueva canalización
de Data Factory.
Aprovisionar Azure Data Factory
Ya hemos aprovisionado el grupo de recursos y la cuenta de Azure Storage. Ahora vamos
a crear un nuevo recurso de Data Factory:
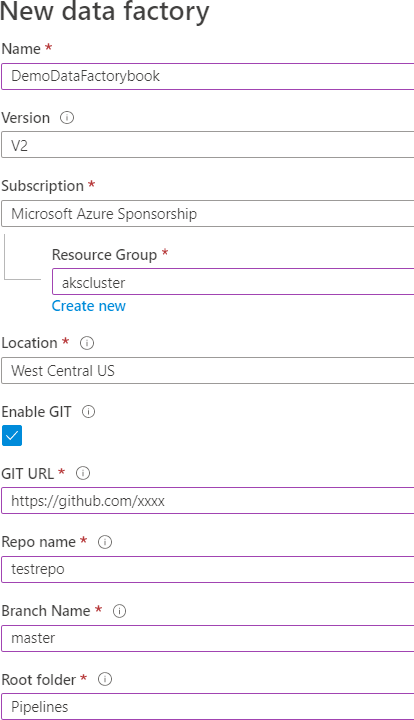
- Para crear una nueva canalización de Data Factory, selecciona V2 y proporciona un
nombre y una ubicación junto con un grupo de recursos y una selección de suscripción.
Data Factory tiene tres versiones diferentes, como se muestra en la Figura 9.6.
Ya hemos hablado de V1 y V2:
- Cuando el recurso de Data Factory se haya creado, haz clic en el enlace Autor
y supervisión del panel central.
Se abrirá otra ventana con el diseñador de Data Factory para las canalizaciones.
El código de las canalizaciones se puede almacenar en repositorios de control de versiones
para que se pueda realizar un seguimiento de los cambios en el código y fomentar la
colaboración entre los desarrolladores. Si te has olvidado de configurar el repositorio
en estos pasos, puedes hacerlo más adelante.
La siguiente sección se centrará en la configuración relacionada con la configuración del
repositorio de control de versiones si el recurso de Data Factory se creó sin configurar
ninguna configuración del repositorio.
Configuración del repositorio
Antes de crear los artefactos de Data Factory, como los conjuntos de datos y las
canalizaciones, conviene configurar el repositorio de códigos para hospedar archivos
relacionados con Data Factory:
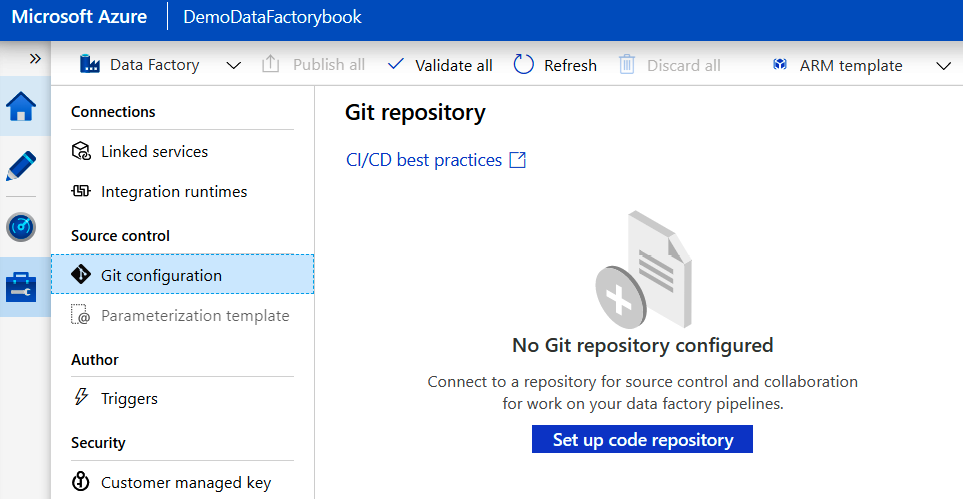
- En la página Creación, haz clic en el botón Administrar y, a continuación, en
Configuración de Git (Git Configuration) en el menú izquierdo. Esto abrirá otro
panel; haz clic en el botón Configurar repositorio de código (Set up code repository)
en este panel:
- En la hoja resultante, selecciona uno de los tipos de repositorios en los que desees
almacenar los archivos de código de Data Factory. En este caso, vamos a seleccionar
Azure DevOps Git:
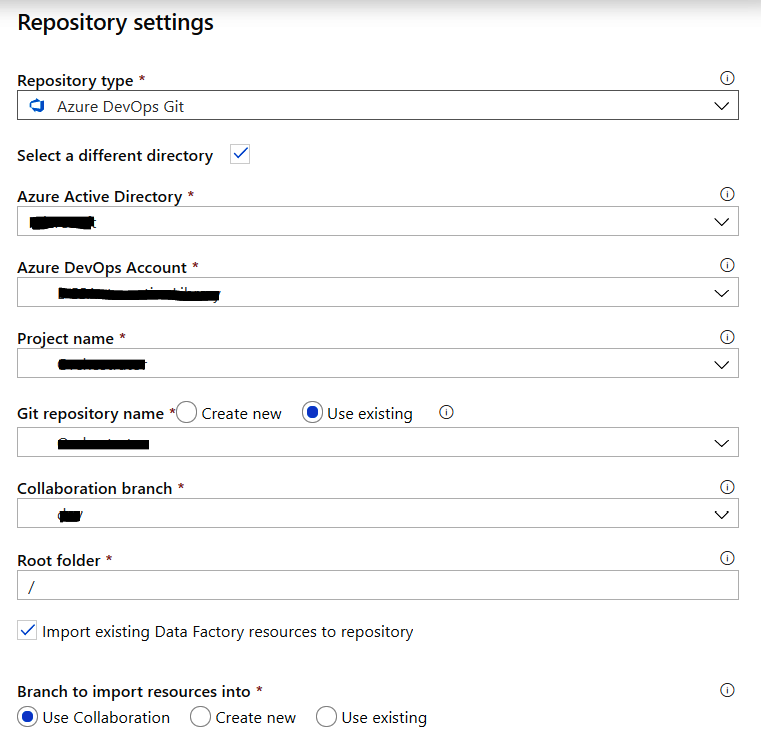
- Crea un nuevo repositorio o vuelve a utilizar uno existente de Azure DevOps. Ya deberías
tener una cuenta en Azure DevOps. Si no es así, visita https://dev.azure.com y usa la
misma cuenta utilizada con Azure Portal para iniciar sesión y crea una nueva organización
y proyecto dentro de ella. Consulta el capítulo 13, Integrar Azure DevOps, para obtener
más información sobre la creación de organizaciones y proyectos en Azure DevOps.
Ahora, podemos volver a la ventana de creación de Data Factory y empezar a crear
artefactos para nuestra nueva canalización.
En la siguiente sección, prepararemos los conjuntos de datos que se utilizarán en nuestras
canalizaciones de Data Factory.
Conjuntos de datos de Data Factory
Ahora podemos volver a la canalización de Data Factory. En primer lugar, crea un nuevo
conjunto de datos que actuará como el conjunto de datos de origen. Será la primera cuenta
de almacenamiento que crearemos y en la que cargaremos el archivo de ejemplo product.csv:
- Haz clic en + Conjuntos de datos -> Nuevo conjunto de datos en el menú de la
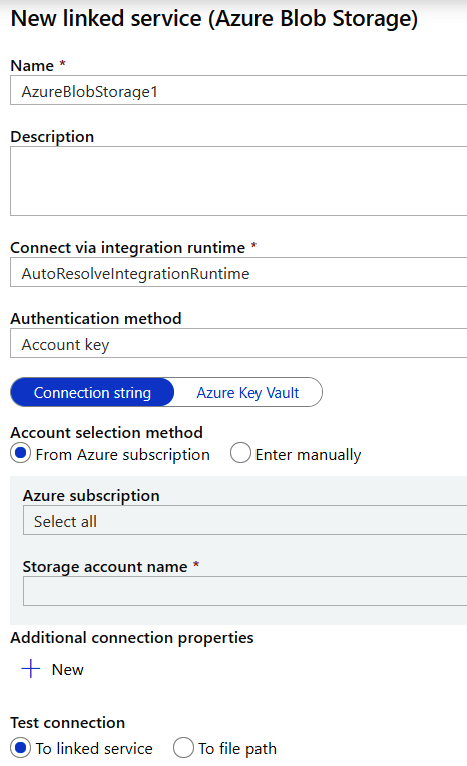
izquierda y selecciona Azure Blob Storage como almacén de datos y delimitedText
como formato para el archivo de origen. Para crear un nuevo servicio vinculado, facilita
un nombre y selecciona una suscripción de Azure y una cuenta de almacenamiento.
De forma predeterminada, AutoResolveIntegrationRuntime se utiliza para el entorno
de tiempo de ejecución, lo que significa que Azure proporcionará el entorno de
tiempo de ejecución en el proceso administrado por Azure. Los servicios vinculados
proporcionan distintos métodos de autenticación. Nosotros vamos a utilizar el
método localizador uniforme de recursos (URI) de firma de acceso compartido (SAS).
También es posible utilizar una clave de cuenta, una entidad principal del servicio
y una identidad gestionada como métodos de autenticación:
- A continuación, en el panel inferior resultante de la pestaña General, haz clic
en el enlace Abrir propiedades y proporciona un nombre al conjunto de datos:
- En la pestaña Conexión, proporciona detalles sobre el contenedor, el nombre del archivo
blob en la cuenta de almacenamiento, el delimitador de fila, el delimitador de columna y
otra información que ayudará a Data Factory a leer los datos de origen adecuadamente.
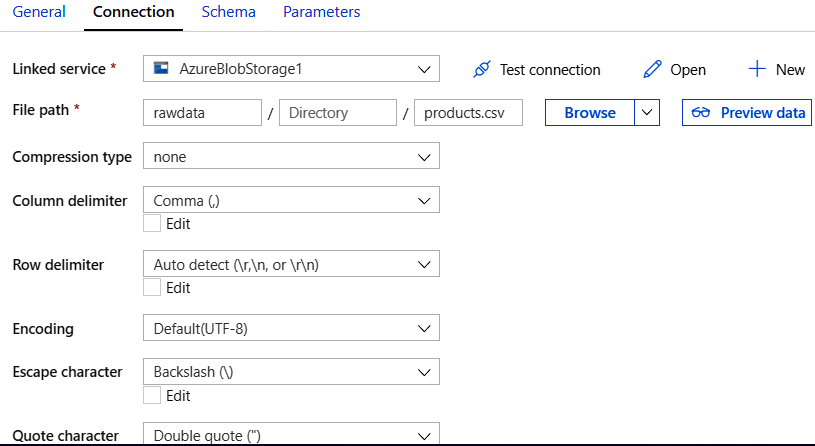
La pestaña Conexión, después de la configuración, debe tener un aspecto similar
al de la Figura 9.11. Ten en cuenta que la ruta incluye el nombre del contenedor
y el nombre del archivo:
- Llegados a este punto, si haces clic en el botón Vista previa de los datos, se mostrará
una vista previa de los datos del archivo product.csv. En la pestaña Esquema,
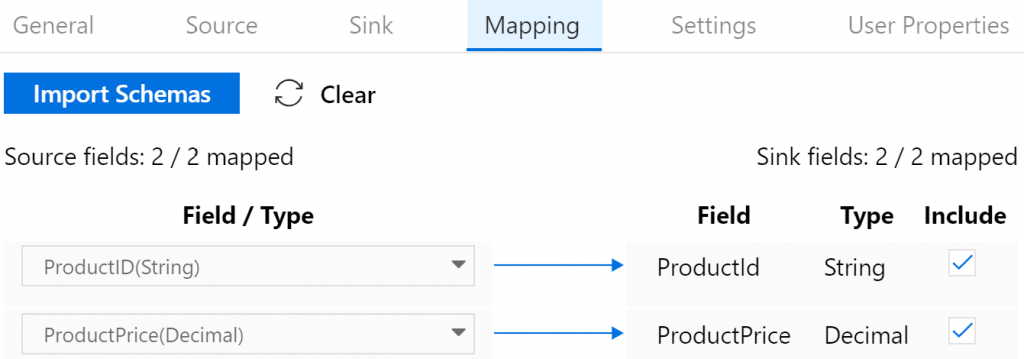
agrega dos columnas y denomínalas ProductID y ProductPrice. El esquema ayuda
a proporcionar un identificador a las columnas y también a asignar las columnas de
origen del conjunto de datos de origen a las columnas de destino del conjunto de datos
de destino cuando los nombres no coinciden.
Ahora que se ha creado el primer conjunto de datos, vamos a crear el segundo.
Crear el segundo conjunto de datos
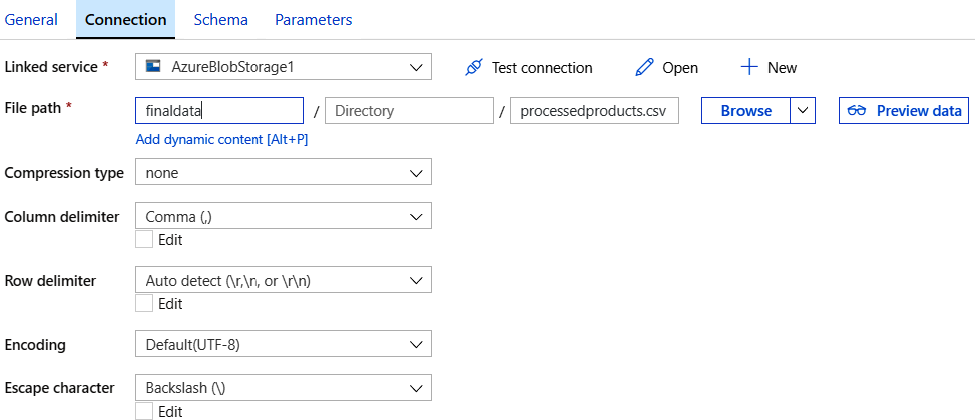
Como has hecho anteriormente, crea un nuevo conjunto de datos y un servicio vinculado
para la cuenta de almacenamiento de blob de destino. Ten en cuenta que la cuenta de
almacenamiento es la misma que el origen, pero el contenedor es diferente. Asegúrate
de que los datos entrantes también tengan información de esquema asociada, tal como
se muestra en la Figura 9.12:
A continuación, vamos a crear un tercer conjunto de datos.
Crear un tercer conjunto de datos
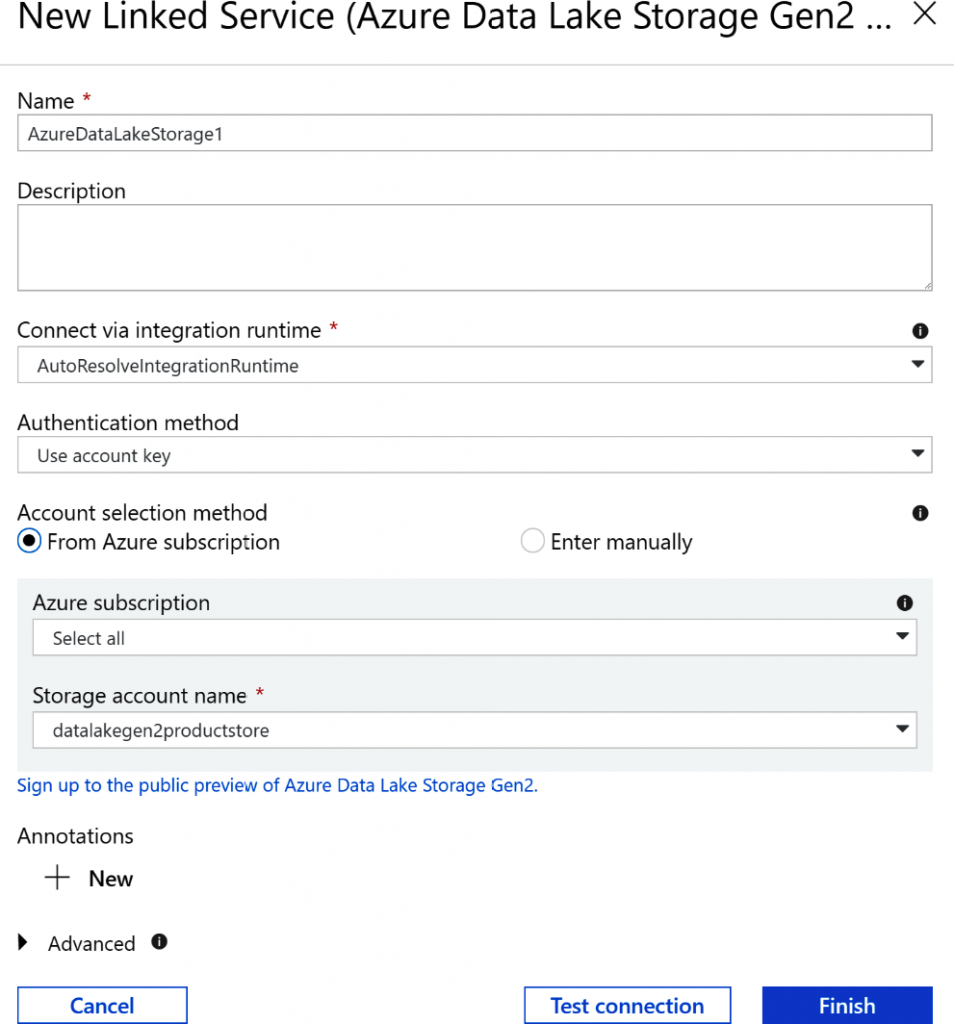
Crea un nuevo conjunto de datos para la instancia de almacenamiento de Data Lake Gen2
como conjunto de datos de destino. Para ello, selecciona el nuevo conjunto de datos y,
a continuación, Azure Data Lake Storage Gen2 (preview).
Proporciona un nombre al nuevo conjunto de datos y crea un nuevo servicio vinculado en
la pestaña Conexión. Selecciona Usar clave de cuenta como método de autenticación y el
resto de la configuración se rellenará automáticamente después de seleccionar el nombre
de la cuenta de almacenamiento. A continuación, prueba la conexión. Para ello, haz clic en
el botón Probar conexión. Mantén la configuración predeterminada para el resto de las
pestañas, tal como se muestra en la Figura 9.13:
Ahora que tenemos la conexión con los datos de origen y también las conexiones con
los almacenes de datos de origen y destino, es el momento de crear las canalizaciones
que contendrán la lógica de la transformación de datos.
Crear una canalización
Cuando se hayan creado los conjuntos de datos, podemos crear una canalización que
consuma estos conjuntos de datos. A continuación, se indican los pasos necesarios para
crear una canalización:
- Haz clic en el menú + Canalizaciones => Nueva canalización del menú izquierdo para
crear una nueva canalización. A continuación, arrastra y suelta la actividad Copiar datos
del menú Mover y transformar, tal como se indica en la Figura 9.14:
- La pestaña General resultante puede dejarse tal cual, pero la pestaña Origen debe
configurarse para usar el conjunto de datos de origen que hemos configurado
anteriormente:

- La pestaña Receptor se utiliza para configurar el conjunto de datos y el almacén
de datos de destino y debe configurarse para usar el conjunto de datos de destino
que hemos configurado anteriormente:

- En la pestaña Asignación, asigna las columnas del origen a las columnas del conjunto
de datos de destino, tal como se muestra en la Figura 9.17:
Agregar una actividad Copiar datos más
En nuestra canalización podemos agregar varias actividades, cada una de ellas encargada
de una tarea de transformación determinada. La tarea analizada en esta sección se encarga
de copiar los datos de la cuenta de Azure Storage a Azure Data Lake Storage:
- Agrega otra actividad Copiar datos desde el menú de actividad de la izquierda para
migrar datos a Data Lake Storage. Ambas tareas de copia se ejecutarán en paralelo:
La configuración del origen es la cuenta de Azure Blob Storage que contiene el archivo
product.csv.
La configuración del receptor se dirigirá a la cuenta de almacenamiento de Data
Lake Gen2.
- Para la segunda actividad Copiar datos se puede dejar la configuración predeterminada.
Una vez completada la creación de la canalización, se puede publicar en un repositorio
de control de versiones como GitHub.
A continuación, analizaremos la creación de una solución con Databricks y Spark.
Crear una solución mediante Databricks
Databricks es una plataforma para el uso de Spark como servicio. No necesitamos aprovisionar
nodos maestros y de trabajo en máquinas virtuales. En su lugar, Databricks nos proporciona
un entorno administrado que consta de nodos maestros y de trabajo y también los administra.
Tenemos que proporcionar los pasos y la lógica para el procesamiento de datos, y del resto se
encarga la plataforma Databricks.
En esta sección, vamos a seguir los pasos necesarios para crear una solución mediante
Databricks. Vamos a descargar datos de ejemplo para analizarlos.
Se ha descargado el archivo CSV de ejemplo de https://ourworldindata.org/coronavirussource-
data, aunque también se proporciona con el código de este libro. La dirección URL
mencionada anteriormente tendrá datos más actualizados; sin embargo, el formato podría
haber cambiado, por lo que se recomienda utilizar el archivo disponible con los ejemplos
de código de este libro:
- El primer paso en la creación de una solución Databricks es aprovisionar desde
Azure Portal. Hay una SKU de evaluación de 14 días disponible junto con otras
dos SKU: estándar y premium. La SKU premium tiene el control de acceso basado
en roles de Azure en el nivel de blocs de notas, clústeres, trabajos y tablas:
- Después de aprovisionar el área de trabajo de Data Bricks, haz clic en el botón Iniciar
área de trabajo (Launch workspace) del panel Información general. Esto abrirá una
nueva ventana del navegador y, finalmente, te conectará al portal de Databricks. - En el portal de Databricks, selecciona Clústeres en el menú de la izquierda y crea
un nuevo clúster, como se muestra en la Figura 9.20:
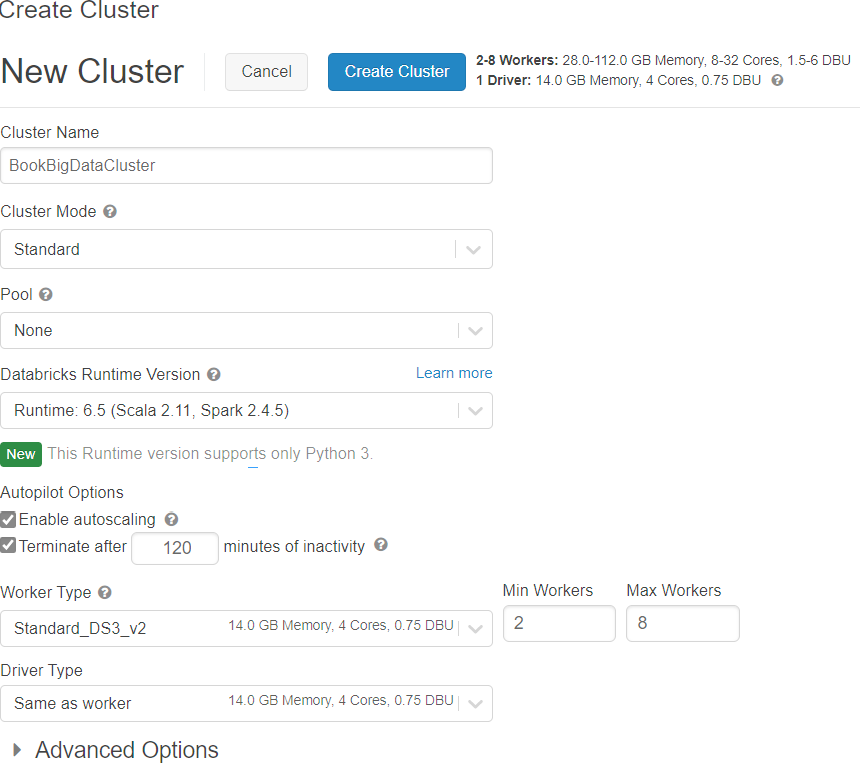
- Proporciona el nombre, la versión del entorno de ejecución de Databricks, el número
de tipos de trabajo, la configuración del tamaño de la máquina virtual y la configuración
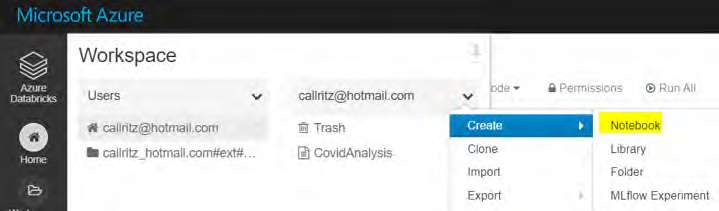
del servidor del tipo de controlador. - La creación del clúster puede tardar unos minutos. Después de crear el clúster, haz clic
en Inicio, selecciona un usuario en su menú contextual y crea un nuevo bloc de notas:
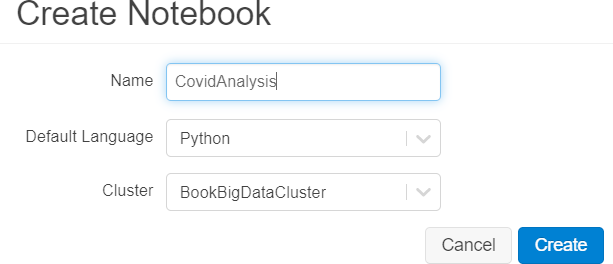
6. Proporciona un nombre al bloc de notas, como se muestra a continuación:
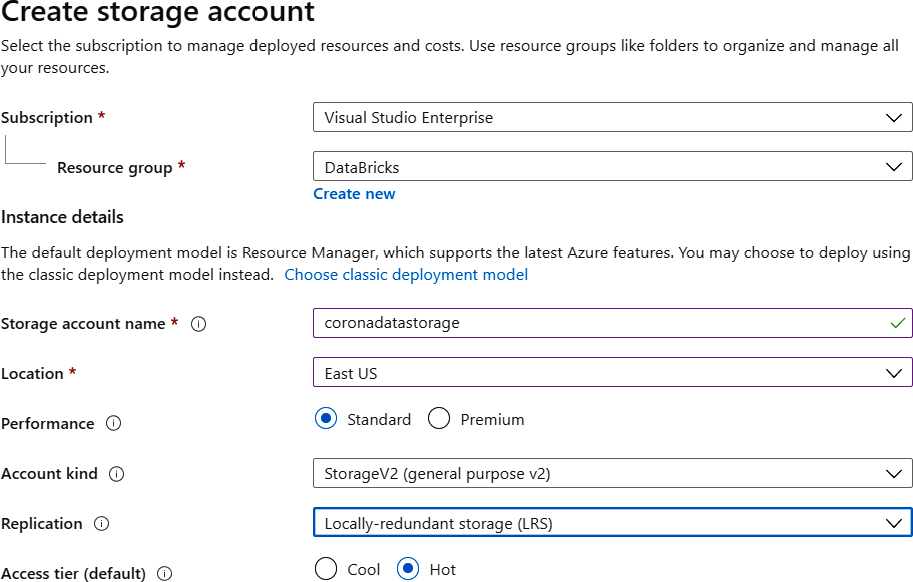
- Crea una nueva cuenta de almacenamiento, como se muestra a continuación. Esta
se utilizará como almacenamiento para los datos COVID sin procesar en formato CSV:
8. Crea un contenedor para almacenar el archivo CSV, como se muestra a continuación:
- Carga el archivo owid-covid-data.csv en este contenedor.
Una vez que hayas completado los pasos anteriores, la siguiente tarea es cargar los datos.
Cargar los datos
El segundo paso importante es cargar los datos de COVID dentro del espacio de trabajo
de Databricks. Esto se puede hacer de dos formas principales:
- Montar el contenedor de Azure Storage en Databricks y, a continuación, cargar los
archivos disponibles en el montaje. - Cargar los datos directamente desde la cuenta de almacenamiento. Este enfoque
se ha utilizado en el ejemplo siguiente.
Se deben realizar los siguientes pasos para cargar y analizar datos mediante Databricks:
- El primer paso es conectar y acceder a la cuenta de almacenamiento. Es necesaria la
clave de la cuenta de almacenamiento, que se almacena en la configuración de Spark.
Ten en cuenta que la clave aquí es «fs.azure.account.key.coronadatastorage.blob.
core.windows.net» y que el valor es la clave asociada:
spark.conf.set(«fs.azure.account.key.coronadatastorage.blob.core.windows.
net»,»xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx==») - La clave de la cuenta de Azure Storage se puede recuperar. Para hacerlo, navega hasta
la configuración y la propiedad Claves de acceso de la cuenta de almacenamiento en
el portal.
El siguiente paso es cargar el archivo y leer los datos dentro del archivo CSV. El esquema
debe deducirse del propio archivo en lugar de proporcionarse explícitamente. También
hay una fila de encabezado que se representa mediante la opción del comando siguiente.
A este archivo se hace referencia con el siguiente formato: wasbs://{{contenedor}}@
{{nombre de cuenta de almacenamiento}}.blob.core.windows.net/{{nombre
de archivo}}.
- El método read del objeto SparkSession proporciona métodos para leer archivos. Para
leer archivos CSV, se debe utilizar el método csv junto con los parámetros requeridos,
como la ruta al archivo CSV. Hay parámetros opcionales adicionales que se pueden
suministrar para personalizar el proceso de lectura de los archivos de datos. Hay
numerosos tipos de formatos de archivo, como JSON, Optimized Row Columnar
(ORC) y Parquet, y bases de datos relacionales como SQL Server y MySQL, almacenes
de datos NoSQL como Cassandra y MongoDB, y plataformas de Big Data como Apache
Hive que pueden utilizarse en Spark. Examinemos el siguiente comando para entender
la implementación de DataFrames de Spark:
coviddata = spark.read.format(«csv»).option(«inferSchema», «true»).
option(«header», «true»).load(«wasbs://coviddata@coronadatastorage.blob.
core.windows.net/owid-covid-data.csv»)
El uso de este comando crea un nuevo objeto del tipo DataFrame en Spark. Spark
proporciona objetos Resilient Distributed Dataset o conjuntos de datos distribuidos
resistentes (RDD) para manipular y trabajar con datos. Los RDD son objetos de
bajo nivel y cualquier código escrito para trabajar con ellos no puede optimizarse.
Los DataFrames son construcciones de nivel superior sobre RDD y proporcionan
optimización para acceder a los RDD y trabajar con ellos. Es mejor trabajar con
DataFrames que con RDD.
DataFrames proporciona datos en formato de filas y columnas, lo que facilita la
visualización y el trabajo con datos. Los DataFrames de Spark son similares a los
DataFrames de pandas, con la diferencia de que son diferentes implementaciones. - El siguiente comando muestra los datos en un DataFrame. Muestra todas las filas
y columnas disponibles en el DataFrame:
coviddata.show()
Deberías obtener un resultado similar al que se puede ver en la Figura 9.25:
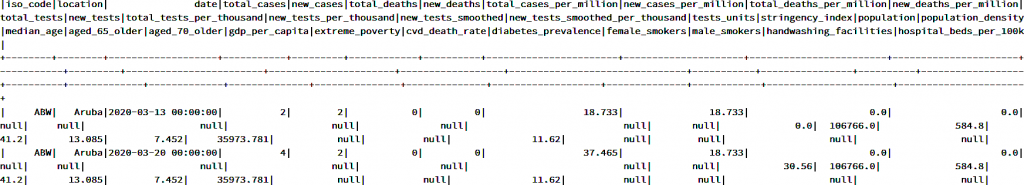
- Spark infiere el esquema de los datos cargados y este se puede comprobar mediante
el siguiente comando:
coviddata.printSchema()
Esto debería proporcionarte un resultado similar al siguiente:

- Para contar el número de filas dentro del archivo CSV, se puede utilizar el siguiente
comando y su resultado muestra que hay 19 288 filas en el archivo:
coviddata.count()
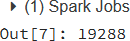
- El DataFrame original tiene más de 30 columnas. También podemos seleccionar un
subconjunto de las columnas disponibles y trabajar directamente con ellas, como se
muestra a continuación:
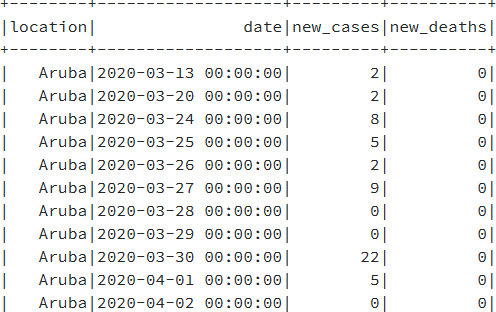
CovidDataSmallSet = coviddata.select(«location»,»date», «new_cases», «new_
deaths»)
CovidDataSmallSet.show()
El resultado del código será el que se muestra en la Figura 9.28:
- También es posible filtrar datos mediante el método filter, como se muestra
a continuación:
CovidDataSmallSet.filter(» location == ‘United States’ «).show() - También es posible agregar varias condiciones juntas utilizando los operadores AND
(&) u OR (|):
CovidDataSmallSet.filter((CovidDataSmallSet.location == ‘United States’) |
(CovidDataSmallSet.location == ‘Aruba’)).show() - Para averiguar el número de filas y otros detalles estadísticos, como el valor medio,
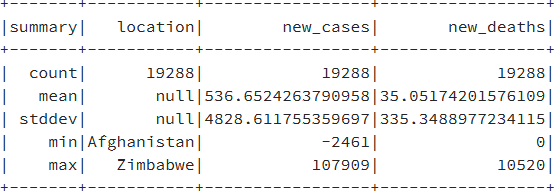
máximo, mínimo y la desviación estándar, se puede utilizar el método describe:
CovidDataSmallSet.describe().show()
Tras utilizar el comando anterior, obtendrás un resultado similar al siguiente:
- También es posible averiguar el porcentaje de datos nulos o vacíos dentro de las
columnas especificadas. A continuación se muestran un par de ejemplos:
from pyspark.sql.functions import col
(coviddata.where(col(«diabetes_prevalence»).isNull()).count() * 100)/
coviddata.count()
El resultado muestra 5.998548320199087, lo que significa que el 95 % de los datos
son nulos. Debemos eliminar estas columnas del análisis de datos. Del mismo modo,
la ejecución del mismo comando en la columna total_tests_per_thousand devuelve
73.62090418913314, lo que es mucho mejor que la columna anterior. - Para quitar algunas de las columnas del DataFrame, se puede utilizar el siguiente comando:
coviddatanew=coviddata.drop(«iso_code»).drop(«total_tests»).drop(«total_
tests»).drop(«new_tests»).drop(«total_tests_per_thousand»).drop(«new_
tests_per_thousand»).drop(«new_tests_smoothed»).drop(«new_tests_smoothed_
per_thousand «)
- A veces, necesitarás tener una agregación de datos. En estos escenarios, puedes
realizar la agrupación de datos, como se muestra a continuación:
coviddatanew = coviddata.groupBy(‘location’).agg({‘date’: ‘max’})
Esto mostrará los datos de la instrucción groupBy:
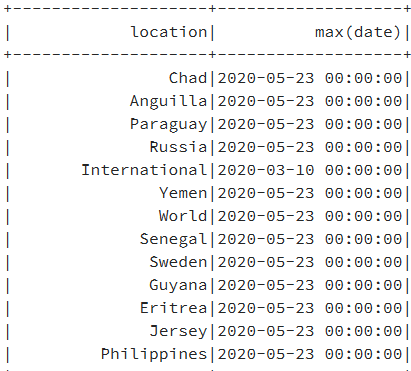
- Como puedes ver en la columna max (date), las fechas son principalmente las mismas
para todos los países, por lo que podemos usar este valor para filtrar los registros
y obtener una sola fila para cada país que represente la fecha máxima:
coviddatauniquecountry = coviddata.filter(«date=’2020-05-23 00:00:00′»)
coviddatauniquecountry.show() - Si realizamos un recuento de registros para el nuevo DataFrame, obtenemos 209.
Podemos guardar el nuevo DataFrame en otro archivo CSV, que pueden necesitar
otros procesadores de datos:
coviddatauniquecountry.rdd.saveAsTextFile(«dbfs:/mnt/coronadatastorage/
uniquecountry.csv»)
Podemos comprobar el archivo recién creado con el siguiente comando:
%fs ls /mnt/coronadatastorage/
La ruta montada se visualizará como se muestra en la Figura 9.31:

- También es posible agregar los datos al catálogo de Databricks mediante el método
createTempView o createOrReplaceTempView dentro del catálogo de Databricks. Al colocar
los datos en el catálogo, estos están disponibles en un contexto determinado. Para agregar
datos al catálogo, se puede utilizar el método createTempView o createOrReplaceTempView
del DataFrame, lo que proporciona una nueva vista para la tabla dentro del catálogo:
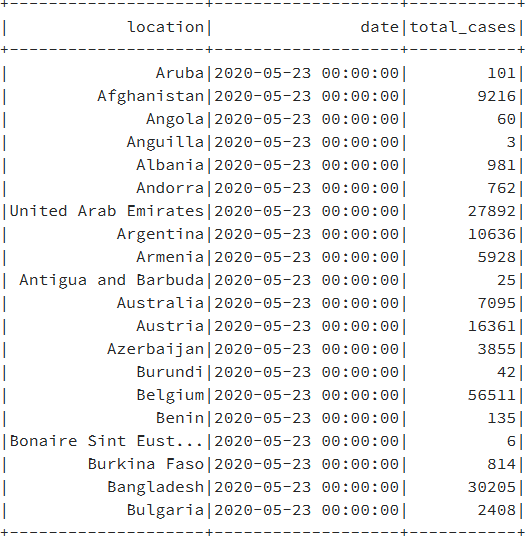
coviddatauniquecountry.createOrReplaceTempView(«corona») - Una vez que la tabla está en el catálogo, se puede acceder a ella desde la sesión SQL,
como se muestra a continuación:
spark.sql(«select * from corona»).show()
Los datos de la instrucción SQL aparecerán como se muestra la Figura 9.32:
- Es posible realizar una consulta SQL adicional en la tabla, como se muestra a continuación:
spark.sql(«select * from corona where location in (‘India’,’Angola’) order
by location»).show()
Esta ha sido una pequeña muestra de las posibilidades de Databricks. Hay muchas más
características y servicios dentro de él que no se podrían abarcar en un solo capítulo. Puedes
leer más información sobre este tema en https://azure.microsoft.com/services/databricks.
Resumen
Se ha analizado el servicio de Azure Data Factory, encargado de proporcionar los servicios
de ETL en Azure. Dado que se trata de una plataforma como servicio, proporciona escalabilidad
ilimitada, alta disponibilidad y unas canalizaciones fáciles de configurar. Su integración con
Azure DevOps y GitHub también es fluida. También hemos explorado las funciones y ventajas
del uso de Azure Data Lake Storage Gen2 para almacenar cualquier tipo de Big Data. Es un
almacén de datos jerárquico, rentable y altamente escalable para el procesamiento de Big Data
y es compatible con Azure HDInsight, Databricks y el ecosistema Hadoop.
En absoluto hemos realizado un análisis completo de todos los temas mencionados en este
capítulo. El objetivo era describir las posibilidades de Azure, especialmente de Databricks y
Spark. Existen varias tecnologías de Azure relacionadas con Big Data, incluidas HDInsight,
Hadoop, Spark y su ecosistema relacionado, y Databricks, que es un entorno de plataforma
como servicio para Spark con funcionalidad añadida. En el siguiente capítulo, descubrirás
las capacidades de computación sin servidor de Azure.