



En los últimos años, la popularidad de los contenedores ha aumentado. No solo ofrecen una menor sobrecarga, alta seguridad y alta portabilidad, sino que también siguen las prácticas recomendadas del cloud, como la inmutabilidad, la efimeridad y el escalado automático.
En este capítulo, explicaremos qué son los contenedores y describiremos las plataformas de contenedores más populares. Además, miraremos más allá del revuelo que ha causado esta tecnología en la industria en general y explicaremos por qué te conviene usar contenedores. También destacaremos algunos de sus beneficios, especialmente cuando se trata del cloud.
¿Por qué usar contenedores?
Los contenedores se ejecutan sobre el sistema operativo host y generalmente se orquestan mediante software como Docker (como veremos más adelante en este capítulo) o Kubernetes (véase la figura 3-1).
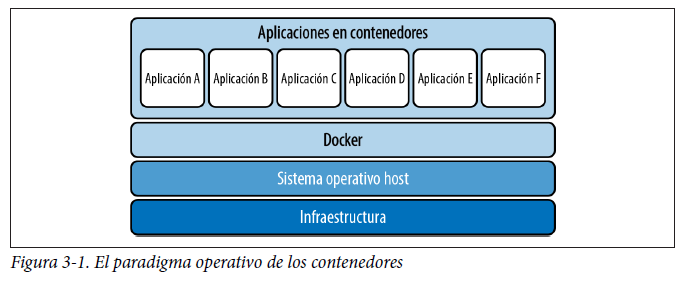
Una de las ventajas más importantes de los contenedores es que proporcionan aislamiento similar a una máquina virtual, pero sin la sobrecarga de ejecutar una instancia del sistema operativo host para cada contenedor. A gran escala, esto puede ahorrar una cantidad importante de recursos del sistema
Aislamiento
Los contenedores proporcionan aislamiento a través de una serie de métodos de una manera flexible configurada por el administrador. Los contenedores pueden aislarse de las siguientes maneras:
Recursos del sistema
El aislamiento se logra a través de los cgroups de CPU, memoria y disco.
Espacios de nombres
El aislamiento se consigue permitiendo espacios de nombres independientes para cada contenedor.
Límites POSIX
El aislamiento con este método te permite establecer rlimits en el contenedor.
Estos mecanismos te permiten ejecutar de forma segura numerosas cargas de trabajo conjuntamente sin que tengas que preocuparte de la contención de recursos y sin que los sistemas se estorben unos a otros. Si tienes un orquestador de contenedores que tenga conocimiento de las cargas de trabajo, puedes utilizar eficazmente todos los recursos de una máquina host sin degradación del rendimiento (lo que se conoce como compactación [bin packing]). Si se hace bien a escala, esto puede suponer un ahorro económico importante al aumentar la eficiencia de la infraestructura.
Seguridad
En línea con las características de aislamiento de los contenedores, la especificación del entorno de ejecución de contenedores OCI (que explicaremos más adelante en este capítulo) proporciona una serie de características relacionadas con la seguridad del entorno de ejecución que garantizan que, si una aplicación dentro de un contenedor resulta atacada, se reduzca considerablemente el riesgo de movimiento lateral por toda la red.
Algunas de estas características son las siguientes:
Funcionalidades Linux
Reducen el acceso del contenedor a las API del kernel.
Atributos de usuario/grupo
Establecen los atributos de usuario y grupo del contenedor, que pueden limitar el acceso a los recursos del sistema de archivos.
Dispositivos
Controlan a qué dispositivos tiene acceso un contenedor.
Etiquetas SELinux
Al igual que otros componentes de un sistema Linux (archivos, procesos, canalizaciones), se pueden aplicar etiquetas SELinux a los contenedores.
Sysctl
Añade controles adicionales (limitados) al contenedor.
Estas capas de características de seguridad del entorno de ejecución proporcionan una forma determinista y administrada de implementar aplicaciones con un riesgo considerablemente menor para la infraestructura de host y las aplicaciones vecinas. Dentro del ecosistema de contenedores también hay un conjunto de paradigmas de seguridad de artefactos, que trataremos más adelante en este capítulo.
Ten en cuenta que si deseas aplicar una política del sistema mediante un mecanismo de orquestación (Puppet/Chef, etc.), es mucho más trabajoso implementarla por aplicación de lo que sería simplemente utilizar las características que proporciona el contenedor.
Empaquetado e implementación
Como comentaremos más adelante en este libro, la estandarización de las imágenes de contenedor y la portabilidad de esas imágenes es extremadamente útil. Es relativamente sencillo coger un contenedor que se ejecuta en tu escritorio e implementarlo en producción sin una sobrecarga operativa significativa y sin tener que realizar pasos adicionales de configuración y administración. El mantra de Docker es «Crear, enviar y ejecutar», lo que pone de relieve la mentalidad «de escritorio a producción» que aporta el contenedor al ciclo de vida de desarrollo de software.
Asimismo, dada la especificación de imágenes de OCI, que explicaremos más adelante en este capítulo, puedes estar seguro de que el sistema de implementación funcionará sin problemas siempre y cuando el registro de contenedores esté disponible.
Primitivos de contenedores básicos
Puede que te sorprenda saber que los contenedores no son un concepto propio de Linux. De hecho, no había una definición formal de un contenedor hasta la creación de la especificación OCI en 2017 (hablaremos con más detalle de las especificaciones más adelante en este capítulo). Un contenedor básico suele constar de los siguientes elementos primitivos:
- Cgroups
- Espacios de nombres
- Copy on write (CoW)
- Seccomp-BPF
Los contenedores de Linux son una evolución natural de tecnologías similares como las jaulas FreeBSD, las zonas Solaris y las máquinas virtuales. En muchos sentidos, los contenedores reúnen lo mejor de estas tecnologías.
Dado que los contenedores no son un concepto primitivo, hay disponibles varias plataformas de software de contenedores. Las explicaremos más adelante en este capítulo. De momento, vamos a describir cada uno de los elementos primitivos básicos del contenedor.
Cgroups
Un grupo de control (cgroup) es un primitivo de Linux que proporciona la capacidad de limitar los recursos a los que puede acceder/asignar un grupo de programas dentro de un cgroup. Esto proporciona protección contra el problema del «vecino ruidoso». A continuación, se muestra una lista de controles que proporcionan los cgroups:
CPU
El control del subsistema de CPU te permite asignar una determinada cantidad de tiempo de CPU (cpuacct) o un determinado número de núcleos (cpuset) a un cgroup, con lo que te aseguras de que un proceso no agote todos los recursos de CPU de una máquina física.
Memoria
El subsistema de memoria te permite registrar y establecer límites para el uso de memoria en un cgroup. Esto funciona tanto para la memoria del usuario como para la memoria de intercambio.
Blkio
El subsistema controlador blkio (que se pronuncia «block-i-o») proporciona un mecanismo para limitar las operaciones de entrada/salida por segundo (IOPS) o ancho de banda (bps) de un cgroup a un dispositivo de bloque.
PID
El controlador PID (identificador de proceso) establece el número máximo de procesos que se pueden ejecutar en el cgroup.
Dispositivos
Este control, que solo se aplica a cgroups v1, permite al administrador establecer listas de permisos y denegaciones para los dispositivos a los que puede acceder un cgroup en el equipo host.
Red
El cgroup de clasificador de red (net_cls) proporciona una interfaz para etiquetar paquetes de red con un identificador de clase (classid).
El cgroup de prioridad de red (net_prio) proporciona una interfaz para establecer dinámicamente la prioridad del tráfico de red generado por varias aplicaciones.
En su mayor parte, la funcionalidad de control de red se proporciona mejor mediante eBPF en las últimas versiones del kernel de Linux.
Espacios de nombres
Los espacios de nombres son una característica de Linux que te permite limitar los recursos que no son de computación, de modo que un grupo de procesos verá un conjunto de recursos y un segundo grupo de procesos verá un conjunto de recursos diferente. En el momento de escribir este libro, Linux contiene los siguientes tipos de espacios de nombres:
Montaje (mnt)
Controla los montajes del sistema de archivos que están disponibles para el contenedor. Esto significa que los procesos de diferentes espacios de nombres de montaje obtienen diferentes vistas de una jerarquía de directorios.
PID (pid)
Proporciona al contenedor un conjunto de PID con números independientes. Esto significa que el primer proceso dentro de un contenedor con su propio espacio de nombres PID tendrá un PID de 1. Cualquier descendiente de PID 1 actuará como un sistema Unix normal.
Red (net)
Una característica excepcionalmente útil que te permite virtualizar tu infraestructura de red. Cada espacio de nombres tendrá un conjunto privado de direcciones IP y su propia tabla de enrutamiento, socket listado, tabla de seguimiento de conexiones, firewall y otros recursos relacionados con la red.
Comunicación entre procesos (ipc)
Aísla los procesos de la comunicación entre procesos de Linux (IPC). Algunos ejemplos son las canalizaciones y las señales.
Unix Time Sharing (uts)
Permite que un único sistema parezca tener diferentes nombres de host y de dominio para diferentes procesos.
Id. de usuario (user)
Similar al espacio de nombres de PID; permite tener privilegios elevados dentro del contenedor, pero no en el sistema general. El espacio de nombres user proporciona segregación de identificación de usuario entre espacios de nombres. El espacio de nombres user contiene una tabla de correspondencias que convierte los identificadores de usuario del punto de vista del contenedor al punto de vista del sistema. Esto permite, por ejemplo, que el usuario raíz tenga el id. de usuario 0 en el contenedor, pero que el sistema lo trate como el id. de usuario 1 400 000 para las comprobaciones de propiedad.
Grupo de control (cgroup)
Oculta la identidad del grupo de control del que es miembro el proceso (esto es independiente del primitivo cgroup).
Hora (time)
Permite que los procesos vean diferentes horas del sistema de forma similar al espacio de nombres UTS.
Copy on Write
Copy on write (CoW) es una técnica de administración de memoria que solo copia la memoria cuando se modifica un recurso o se escribe en él. Esta técnica reduce la cantidad de memoria necesaria.
Funcionalidades
Las funcionalidades de Linux permiten al administrador controlar de forma más estricta qué funciones tiene el proceso o cgroup en el sistema host. Puedes encontrar una lista de funcionalidades en capabilities(7) manpage. Por ejemplo, si quisieras ejecutar un servidor web en el puerto 80, solo tendrías que proporcionar al cgroup/proceso la función CAP_NET_BIND_SERVICE. Si el servidor web resulta atacado, las acciones del atacante estarán limitadas, ya que el proceso no tiene permisos del sistema para ejecutar otros comandos administrativos.
Seccomp-BPF
Seccomp (SECure COMPuting) es útil para crear restricciones absolutas en todos los sistemas. Seccomp-BPF permite un control detallado por aplicación. Seccomp-BPF ofrece granularidad por subproceso (en modo estricto). Se añadió al kernel en la versión 3.5 (2012).
Seccomp-BPF permite a los programas de filtro de paquetes de Berkeley (BPF) —programas que se ejecutan en el espacio del kernel— filtrar syscalls (y sus argumentos) y devolver un valor sobre lo que debería suceder una vez que termine de ejecutarse el programa Seccomp-BPF.
Componentes de ejecución de un contenedor
Como ya comentamos anteriormente en este capítulo, los contenedores no son un concepto propio de Linux (no hay un primitivo de contenedor en Linux), lo que los hace un poco difíciles de definir y, por ese motivo, en el pasado era difícil hacer que los contenedores fueran portátiles. Sin embargo, para ejecutar un contenedor, debe haber algún tipo de interfaz definida entre la estructura del contenedor y el software del sistema operativo (o el software del host).
En esta sección, analizaremos los detalles del software de contenedores, incluidos los entornos de ejecución de contenedores (el software que ejecuta el contenedor), las plataformas de contenedores y los orquestadores de contenedores.
En primer lugar, echemos un vistazo rápido a las capas de abstracción en el ecosistema de contenedores (figura 3-2).

En esta sección, vamos a recorrer estas capas de abstracción de arriba abajo para ver cómo se trabaja con contenedores perfectamente orquestados y analizar conceptos de Linux de bajo nivel que permiten el funcionamiento de los contenedores.
Orquestadores de contenedores
En la capa superior están los orquestadores de contenedores que realizan la magia de administrar el escalado automático, la sustitución de instancias y la supervisión de un ecosistema de contenedores que convierte los contenedores en un concepto tan atractivo. Como comentaremos en el capítulo 4 y en el capítulo 5, Kubernetes es la plataforma de programación y orquestación acreditada de la Cloud Native Computing Foundation (CNCF).
Los orquestadores de contenedores proporcionan por lo general la siguiente funcionalidad:
- Escalado automático de instancias de clúster en función de la carga de la instancia
- Aprovisionamiento e implementación de instancias
- Funcionalidad de supervisión básica
- Detección de servicios
Otros orquestadores de contenedores CNCF son los siguientes:
- Azure Kubernetes Service (AKS)
- Azure Service Fabric
- Amazon Elastic Container Service (ECS)
- Docker Swarm
- Apache Mesos
- HashiCorp Nomad
Los buenos orquestadores de contenedores permiten crear y mantener fácilmente clústeres de computación. En el momento de escribir este libro, no hay ninguna configuración estándar para los orquestadores de contenedores.
Software de contenedores
Los daemons de contenedor, situados justo debajo de los orquestadores, proporcionan el software para ejecutar un daemon. Dependiendo del orquestador que utilices, esto puede ser transparente para ti. Esencialmente, los daemons de contenedor administran el ciclo de vida del entorno de ejecución del contenedor. En muchos casos, esto será tan sencillo como iniciar o detener el contenedor o tan complicado como interactuar con complementos como Cilium.
Entre las plataformas de software de contenedores comunes se incluyen:
- Docker
- Agente Mesos (Mesos)
- Kubelet (Kubernetes)
- LXD (LXC)
- Rkt
Como comentaremos más adelante en este capítulo, Docker te permite realizar una imagen y luego crear instancias de contenedor de esta imagen, proporcionando esencialmente la interfaz de usuario como una acción no orquestada. Los agentes Mesos o los kubelets son ligeramente diferentes, ya que se basan en CLI o API REST.
Entornos de ejecución de contenedores
Los entornos de ejecución de contenedores proporcionan una interfaz para ejecutar instancias de contenedor. En todo el sector, hay dos categorías estándar de interfaces:
- Entorno de ejecución de contenedor (runtime-spec)
- Especificación de la imagen (image-spec)
El entorno de ejecución de contenedor especifica la configuración del contenedor (por ejemplo, funcionalidad, montajes y configuración de red). La especificación de la imagen contiene información sobre el diseño del sistema de archivos y el contenido de la imagen.
Aunque cada daemon u orquestador del contenedor tiene su propia especificación de configuración, el entorno de ejecución de contenedor es un área que ofrece estandarización de toda la imagen.
Tres de los entornos de ejecución de contenedores más destacados son:
- Containerd
- CRI-O
- Docker (hasta Kubernetes v1.2)
Containerd
Containerd es un entorno de ejecución de contenedor compatible con OCI que se utiliza en Docker. Containerd actúa como una capa de abstracción entre todos los sistemas Linux que hacen que funcione un contenedor y la configuración OCI estándar que configura un contenedor. Containerd tiene un subsistema de eventos que permite a otros sistemas como admite formatos de imagen OCI y Docker. «What is containerd?» es una excelente entrada de blog con información adicional.
CRI-O
CRI-O es una implementación de la interfaz de runtime de contenedor (CRI) de Kubernetes que habilita runtimes compatibles con OCI. Se considera una alternativa ligera al uso de Docker y containerd. CRI-O también admite la ejecución de contenedores Kata (un contenedor tipo máquina virtual creado por VMware) y es extensible a cualquier otro runtime compatible con OCI. Esto lo convierte en un runtime atractivo para usarlo en varios casos prácticos.
Docker
No debe confundirse con la plataforma Docker completa. Docker realmente contiene un motor de tiempo de ejecución que paradójicamente es, en esencia «containerd». Kubernetes admite Docker como runtime de contenedor hasta la versión v1.20 de Kubernetes.
Contenedores
La instancia del contenedor es la implementación y el funcionamiento del software, según se define en una especificación del contenedor. El contenedor ejecuta el software definido (normalmente proporcionado por una imagen) contenido en una serie de configuraciones y límites.
Sistema operativo
El sistema operativo es la base de las construcciones, que es en lo que se ejecutan nuestros contenedores. En la mayoría de los entornos de ejecución de contenedores, el kernel se comparte entre todas las instancias de contenedor.
Especificación de Open Container Initiative (OCI)
Como se mencionó anteriormente, los contenedores no eran un concepto bien definido al principio. La Open Container Initiative (OCI) se estableció en 2015 para formalizar las especificaciones de tiempo de ejecución e imagen mencionadas anteriormente.
La configuración de runtime de un contenedor se especifica en un archivo config.json que utiliza el runtime de contenedor para configurar los parámetros operativos del contenedor. El uso de un contenedor compatible con OCI permite ejecutar la misma imagen o configuración del contenedor en varios orquestadores de contenedores (por ejemplo, Docker y RKT) sin necesidad de modificar nada.
Especificación de imagen de OCI
La especificación de imagen de OCI describe cómo se definen las capas del contenedor. Algunas de las propiedades de la imagen son:
- Autor
- Arquitectura y sistema operativo
- Usuario/grupo como el que se ejecuta el contenedor
- Puertos que se exponen fuera del contenedor
- Variables de entorno
- Puntos de entrada y comandos
- Directorio de trabajo
- Etiquetas de imágenes
A continuación, se muestra un ejemplo de imagen de contenedor:

Especificación de tiempo de ejecución de OCI
En un nivel alto, la especificación de configuración del tiempo de ejecución proporciona control de los siguientes atributos de contenedor:
- Sistemas de archivos predeterminados
- Espacios de nombres
- Asignaciones de id. de usuario y de grupo
- Dispositivos
- Configuración del grupo de control
- Sysctl
- Seccomp
- Montaje de rootfs
- Rutas enmascaradas y de solo lectura
- Montar etiquetas SELinux
- Comandos de enlace
- Otros atributos especializados (por ejemplo, personalidad, unificados e Intel RDT)
La especificación de OCI también abarca cómo se define el estado de un contenedor y el ciclo de vida del contenedor. El estado del contenedor se puede consultar mediante una función state (en containerd, in y runc) y devuelve los atributos siguientes:

ejecución, incluida la forma en que la especificación del tiempo de ejecución interactúa con la especificación de la imagen. Define cómo se inicia y configura el contenedor y cómo interactúa con los enlaces de inicio/detención de la imagen.
Docker
Docker proporciona una plataforma como servicio (PaaS) que permite a los usuarios ejecutar aplicaciones en contenedores en un escritorio de una manera simplificada y estandarizada. Docker ejecuta imágenes compatibles con OCI y suele ser un medio para probar una implementación de código antes de implementarla en un entorno de producción. Además, la disponibilidad general de software de escritorio de Docker proporciona a los desarrolladores un mecanismo sencillo para probar el empaquetado y la implementación de su código, lo que lo ha convertido en un sistema atractivo para los desarrolladores.
Creación de la primera imagen de Docker
Las imágenes de Docker por sí solas son imágenes no compatibles con OCI (su estructura es diferente de la especificación de OCI) que se ejecutan en Docker y en sistemas que admiten el runtime de Docker (containerd). La belleza de las imágenes de Docker está en su creación rápida y sencilla. Cada imagen de contenedor la define un Dockerfile. Este archivo consta de propiedades y comandos para compilar la imagen, ejecutar la aplicación, exponerla a la red y realizar comprobaciones de estado. Define qué dependencias y archivos se copian en la imagen del contenedor, así como qué comandos se ejecutan para iniciar las aplicaciones dentro del contenedor. Los desarrolladores que se ocupaban de la administración de paquetes o la agrupación de aplicaciones en RPM o DEB (o tarballs) prefirieron este enfoque de crear la imagen de Docker con un formato simple (imperativo) parecido al script de shell (ejecutar comando tras comando).
Docker proporciona una referencia de configuración completa que puede ayudarte a crear tu propio contenedor.
Creación de tu propio contenedor
Una forma excelente de entender cómo funcionan los contenedores es crear tu propio contenedor básico. Recomendamos probar el taller de rubber-docker, donde se recorren los componentes básicos de un contenedor y se muestra cómo se implementan.
Aunque el Dockerfile permite configuraciones complejas, es excepcionalmente fácil crear una imagen en solo unas pocas líneas. En el ejemplo siguiente, ejecutaremos una aplicación web Python Flask y expondremos el puerto 5000:

En su totalidad, esta imagen de contenedor se copia sobre nuestra aplicación y, a continuación, instala los requisitos de la aplicación, se inicia y permite conexiones de red en el puerto 5000 (el puerto Flask predeterminado).
Para permitir que los usuarios u otras aplicaciones accedan al contenedor, el Dockerfile contiene una directiva, EXPOSE, que permite a la pila de red del contenedor escuchar en el puerto especificado en tiempo de ejecución.
Un Dockerfile es técnicamente una combinación de un runtime de contenedor y una especificación de imagen, ya que proporciona semántica sobre el contenido de la imagen y cómo se ejecuta (es decir, limitaciones de la CPU o del cgroup de memoria).
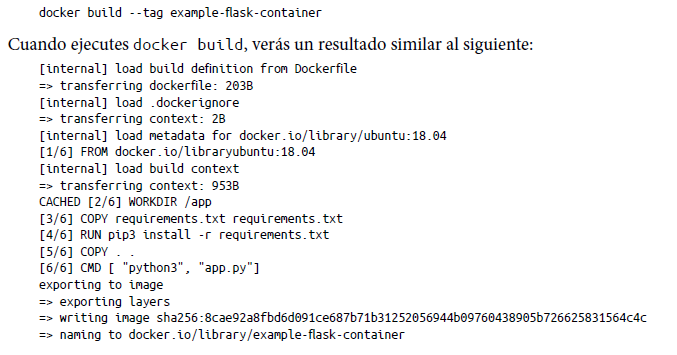
Una vez creado el Dockerfile, puedes crear la imagen de contenedor mediante el comando docker build. Esto se hace normalmente con la ruta de archivo actual (por ejemplo, docker build), pero también puedes usar una URL (por ejemplo, docker build https:// github.com/abcd/docker-example). Puedes encontrar una referencia completa sobre cómo usar docker build en la documentación.
Debes crear una etiqueta para tu imagen para poder hacer referencia a ella rápida y fácilmente en el futuro cuando crees la imagen. Para ello, agrega la opción –tag en la compilación:
Prácticas recomendadas al usar Docker
La aplicación de doce factores realiza un seguimiento de una serie de características de aplicaciones dockerizadas y basadas en el cloud. Esto significa que la aplicación debe poder implementarse, iniciarse, detenerse y destruirse sin provocar problemas. Aunque hablaremos sobre las soluciones de almacenamiento de contenedores más adelante en este libro, debes intentar evitar la persistencia de datos en la medida de lo posible, a menos que leas datos de un volumen persistente o utilices un servicio de datos nativo del cloud (consulta el capítulo 9 para obtener más información sobre esto).
Hay algunas prácticas recomendadas más que debes seguir:
- Utiliza las opciones de docker build. Estas opciones te permiten personalizar la imagen de Docker para añadir características como controles de cgroup, etiquetas, configuraciones de red y mucho más.
- Utiliza un archivo .dockerignore. Similar a .gitignore, .dockerignore garantizará que determinados archivos o carpetas no estén incluidos en la compilación de imágenes.
- Para reducir la complejidad, las dependencias, los tamaños de archivo y los tiempos de compilación, evita instalar paquetes adicionales o innecesarios.
- Usa compilaciones multietapa. Si necesitas instalar dependencias para compilar la aplicación, puedes hacerlo durante el proceso de compilación de tu imagen, pero solo copia la salida en la imagen del contenedor. Esto reduce el tamaño de la compilación de la imagen.
Puedes encontrar más información sobre las prácticas recomendadas de Dockerfile en el sitio web de Docker.
Otras plataformas de contenedores
Aunque las imágenes de la plataforma Docker y OCI siguen siendo líderes del sector, todavía hay otras ofertas de contenedores disponibles.
Kata Containers
Kata Containers son contenedores compatibles con OCI que tienen como objetivo mejorar la seguridad. Los Kata Containers tienen las siguientes características de contenedor ligero:
- Cgroups
- Espacios de nombres
- Filtros de capacidad
- Filtrado seccomp
- Control de acceso obligatorio
Los Kata Containers también poseen algunos conceptos de máquinas virtuales, particularmente un kernel de invitado independiente por contenedor y un mejor aislamiento del hardware. El proceso kata-runtime controla la creación de instancias del contenedor compatible con OCI. La mayor diferencia es que hay un kernel de invitado independiente por contenedor en lugar de un kernel compartido entre instancias de contenedor.
LXC y LXD
LXC (Linux Containers) es uno de los primeros mecanismos de contenedores que se han publicado. LXC utiliza principalmente las capacidades de cgroup y espacio de nombres del kernel, así como un conjunto estándar de API de biblioteca para controlar los contenedores.
LXD es el software de administración de contenedores y las herramientas que ayudan a organizar las API de LXC. El demonio LXD proporciona una API REST sobre un socket/red Unix que te permite utilizar las herramientas de línea de comandos proporcionadas o crear las tuyas propias.
El ecosistema de LXC y LXD está más orientado a la ejecución de la infraestructura que al desarrollo de aplicaciones debido a la falta de herramientas de desarrollo e implementación.
Registros de contenedores
Después de crear tus imágenes de contenedor, necesitarás lugares para almacenarlas y servirlas. Estos registros se conocen como registros de contenedores. La popularidad de los registros de contenedores ha aumentado debido a sus mecanismos de implementación sencillos y sus mecanismos de replicación integrados, que sustituyen a las complejas configuraciones asincrónicas necesarias para los repositorios de paquetes DEB y RPM.
Al implementar un contenedor, el sistema de implementación del contenedor descargará la imagen del registro en el equipo host. Esencialmente, un registro de contenedores actúa como un servidor de archivos de imagen de contenedor altamente disponible (con algunas protecciones). Todas las plataformas de contenedores comunes te permiten configurar un repositorio público o privado como origen para las imágenes del contenedor.
Aunque estas responsabilidades suenan a algo razonablemente trivial, hay muchas características ignoradas de los registros de contenedores que son partes importantes de las implementaciones de contenedores seguros.
Tales características incluyen:
Replicación de imágenes
Replicación de las imágenes en otros registros de contenedores (globalmente)
Autenticación
Solo los usuarios autorizados tienen acceso al registro y a su contenido
Control de acceso basado en roles
Restricción de quién puede modificar imágenes y datos dentro del registro
Análisis de vulnerabilidades
Comprobación de imágenes de vulnerabilidades conocidas
Recolección de elementos no utilizados
Eliminación periódica de imágenes antiguas
Auditorías
Suministro de información de confianza sobre los cambios en el registro de contenedores con fines de seguridad de la información
Entre los productos nativos del cloud actuales se incluyen (consulta el panorama de CNCF para obtener más información):
- Harbor
- Dragonfly
- Alibaba Container Registry
- Amazon Elastic Container Registry (Amazon ECR)
- Azure Registry
- Registro de Docker
- Google Container Registry
- IBM Cloud Container Registry
- JFrog Artifactory
- Kraken
- Portus
- Quay
Muchos de estos sistemas están vinculados a proveedores específicos. Sin embargo, Harbor es uno de los sistemas de registro de contenedores de código abierto más populares, por lo que profundizaremos más en él.
Almacenamiento seguro de imágenes con Harbor
Harbor es la mejor plataforma de registro de contenedores nativos de código abierto en el cloud. Harbor, que se creó en 2016, almacena imágenes de contenedores y proporciona funcionalidad de escaneo de firmas y seguridad. Además, Harbor admite funcionalidad de alta disponibilidad y replicación, así como una serie de funciones de seguridad, incluida la administración de usuarios, el control de acceso basado en roles y la auditoría de actividades. La belleza de Harbor es que ofrece características de primer nivel a pesar de ser de código abierto, lo que lo convierte en una excelente plataforma.
Instalación de Harbor
Cuando utilizas Harbor, esencialmente se convierte en un componente crítico de tus canalizaciones de compilación e implementación. Debes ejecutarlo en un host que cumpla las especificaciones recomendadas:
- CPU de cuatro núcleos
- 8 GB de memoria
- Disco de 160 GB como mínimo
- Ubuntu 18.04/CentOS7 o posterior
Querrás evaluar el rendimiento de la configuración o la SKU de disco para que coincida con el rendimiento que deseas. Harbor es esencialmente un servidor de archivos y el rendimiento del disco afectará significativamente a los tiempos de compilación e implementación.
Harbor es compatible con varios métodos de instalación, incluidos Kubernetes y Helm. Como aún no hemos explorado Kubernetes, vamos a instalar Harbor manualmente.
Harbor tiene dos versiones (o tipos de instalaciones): un instalador online y un instalador sin conexión. El instalador online tiene un tamaño más reducido y utiliza una conexión a Internet para descargar la imagen completa de Docker Hub (directamente fuera de Internet). El instalador sin conexión tiene un tamaño mayor y no requiere una conexión a Internet. Si tu postura de seguridad es restrictiva, el instalador sin conexión puede ser una mejor opción.
Las versiones de Harbor se enumeran en GitHub.

Configuración de Harbor para la instalación
Antes de configurar Harbor, debes habilitar HTTPS instalando un certificado de Capa de sockets seguros (SSL) a través de tu propia entidad de certificación (CA) o a través de una CA pública como Let’s Encrypt. Puedes encontrar más información sobre cómo hacerlo en la documentación de Harbor.
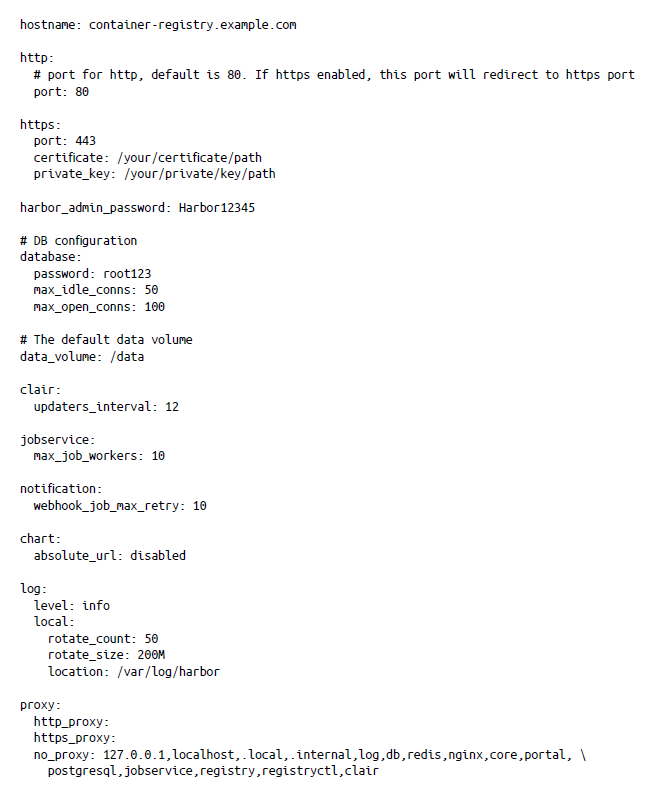
Todos los parámetros de instalación de Harbor se definen en un archivo llamado harbor.yml. Los parámetros definidos en este archivo configuran Harbor para su primer uso o cuando se está reconfigurando a través del archivo install.sh. Puedes encontrar detalles sobre todas las opciones de configuración en GitHub. Para empezar, utilizaremos los siguientes parámetros necesarios:
Creación de una imagen de Packer
Con los conocimientos del capítulo 2, vamos a crear una imagen de Packer para implementar Harbor. Puedes usar el siguiente archivo harbor.json:
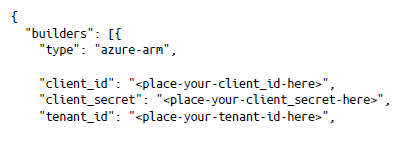

Cuando ejecutes packer build harbor.json, tu imagen se compilará con Harbor instalado y configurado. Si usas HTTPS (y deberías), tendrás que modificar el archivo de Packer para incluir la copia del certificado y los archivos de clave privada.
Almacenamiento seguro de imágenes con Azure Container Registry
Azure proporciona su propio registro de contenedores, conocido como Azure Container Registry. Dado que Azure proporciona el registro, la configuración inicial y los requisitos de mantenimiento continuos consumen mucho menos tiempo que cuando se ejecuta software como Harbor.
Instalación de Azure Container Registry
La implementación de una instancia de contenedor es excepcionalmente sencilla:
- Inicia sesión en Azure Portal y haz clic en «Crear un recurso», como se muestra en la Figura 3-3.
2. Busca «container registry» en la barra de búsqueda y haz clic en la oferta de Container Registry de Microsoft (consulta la Figura 3-4).
Verás un formulario para rellenarlo con la información básica sobre el registro que vas a crear (Figura 3-5).
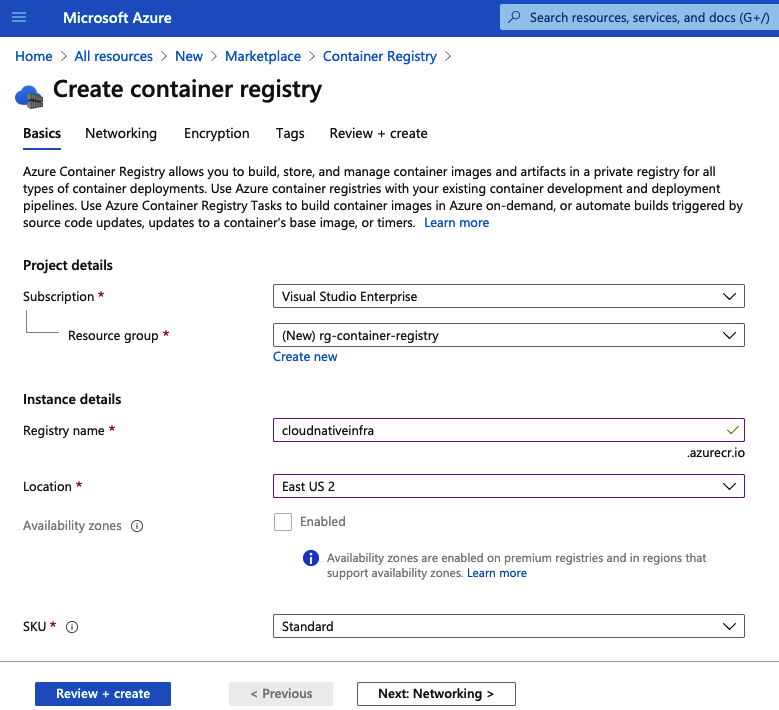
- Proporciona los siguientes detalles básicos del registro de contenedores:
Suscripción
Elige la suscripción en la que quieras realizar la implementación.
Grupo de recursos
Puedes usar un grupo de recursos existente o crear uno nuevo. En este caso, vamos a crear uno nuevo llamado rg-container-registry.
Nombre del registro
Esto configurará la dirección URL utilizada para acceder al registro. Vamos a usar cloudnativeinfra.azurecr.io. Es globalmente único, por lo que deberás elegir el tuyo propio y asegurarte de no recibir un mensaje de error que indique que ya está en uso.
Región
Elige tu región. Vamos a implementar en la región del este de EE. UU. 2.
SKU
Hay tres niveles disponibles. Puedes encontrar una comparación en la página de precios de Container Registry. Vamos a usar el nivel Estándar.
4. Elige tu configuración de red (Figura 3-6). Como estamos usando el nivel Estándar, no podemos realizar ningún cambio de configuración aquí. Por lo tanto, el registro de contenedores que se creará está disponible a través de Internet y no solo dentro de nuestra red de Azure.
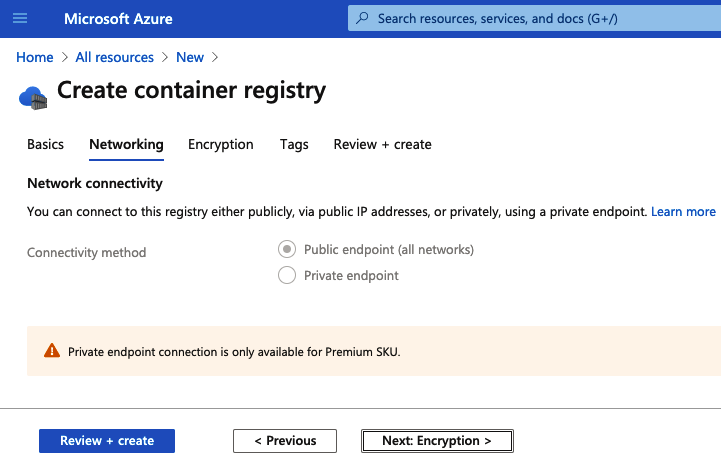
5. Elige tu configuración de cifrado (Figura 3-7). El nivel Estándar proporciona cifrado en reposo para los datos almacenados, mientras que el nivel Premium permite a los usuarios establecer sus propias claves de cifrado.
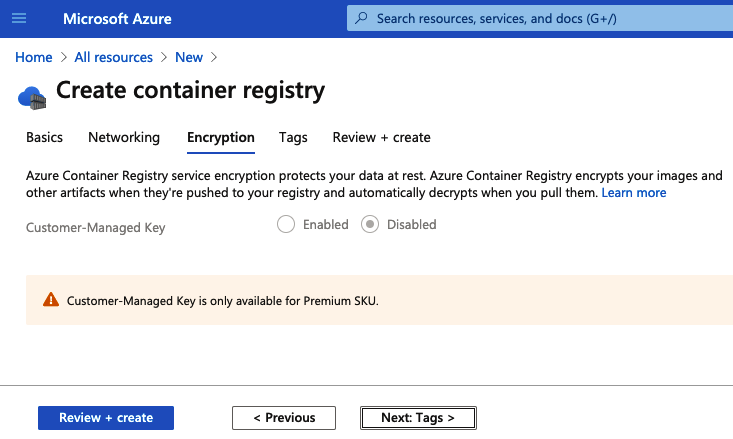
6. Haz clic en «Revisar y crear» para crear tu registro de contenedores. La implementación debería tardar menos de dos minutos.
Puntos de conexión privados
Los puntos de conexión privados son un concepto de Azure que permite que los recursos del cloud estén disponibles a través del espacio de direcciones RFC1918 en lugar de una IP pública. Esto significa que tu recurso solo está disponible a través de una red conectada localmente y no a través de Internet.
Si quieres implementar tu registro de contenedores a través de Terraform, el siguiente código te permitirá hacerlo:


Almacenamiento de imágenes de Docker en un registro
Como ya comentamos anteriormente, es necesario poder almacenar y servir imágenes de contenedor de forma fiable. Una vez que hayas creado tu imagen personalizada, debes insertarla en el registro. Además, y como ya comentamos anteriormente, hay numerosas opciones para almacenar imágenes, incluidos el Registro de Docker y los registros de contenedores de los distintos proveedores del cloud (por ejemplo, Azure Container Registry). En este caso, vamos a utilizar el registro de Harbor que creamos anteriormente en este capítulo.
Primero iniciaremos sesión en el registro:

Ejecución de Docker en Azure
En Azure, hay dos maneras de ejecutar la imagen de contenedor de Docker: usando Azure Container Instances o ejecutando tu propia máquina virtual con Docker instalado. En esta sección, mostraremos ambos métodos.
Azure Container Instances
Azure Container Instances (ACI) te permite utilizar rápidamente una instancia de contenedor en Azure sin tener que administrar la infraestructura subyacente. Esto proporciona un servicio tipo Docker, pero en el cloud público. ACI permite la implementación de imágenes de Azure Container Registry o imágenes de Docker desde repositorios privados o públicos.
ACI también permite colocar estas instancias en redes privadas o públicas, dependiendo del uso de las imágenes del contenedor.
Estas son algunas características adicionales de ACI:
- No es necesario configurar una especificación de tiempo de ejecución de OCI
- La capacidad de pasar variables de entorno al contenedor
- Administración básica del firewall
- Políticas administradas de reinicio de contenedores
En pocas palabras, ACI es la forma más fácil de empezar a ejecutar contenedores en Azure. ACI también te ofrece la capacidad de probar nuevas imágenes de contenedor sin crear un entorno totalmente independiente.
Hay algunas consideraciones importantes que cabe tener en cuenta al ejecutar ACI:
- Hay un límite de cuatro núcleos/16 GB para cualquier instancia de contenedor único.
- La configuración de ACI para la CPU y la memoria anulará cualquier configuración de tiempo de ejecución aplicada a la imagen del contenedor.
Implementación de una instancia de contenedor de Azure
La implementación de una instancia de contenedor de Azure es excepcionalmente sencilla. En primer lugar, inicia sesión en Azure Portal y luego haz clic en «Crear un recurso», como se muestra en la Figura 3-8.
Haz clic en Contenedores en el lado izquierdo y verás una oferta de productos relacionados con contenedores (consulta la Figura 3-9). Haz clic en el enlace de Container Instances.
Verás un formulario para rellenarlo con la información básica sobre la instancia de contendor que vas a crear (Figura 3-10).
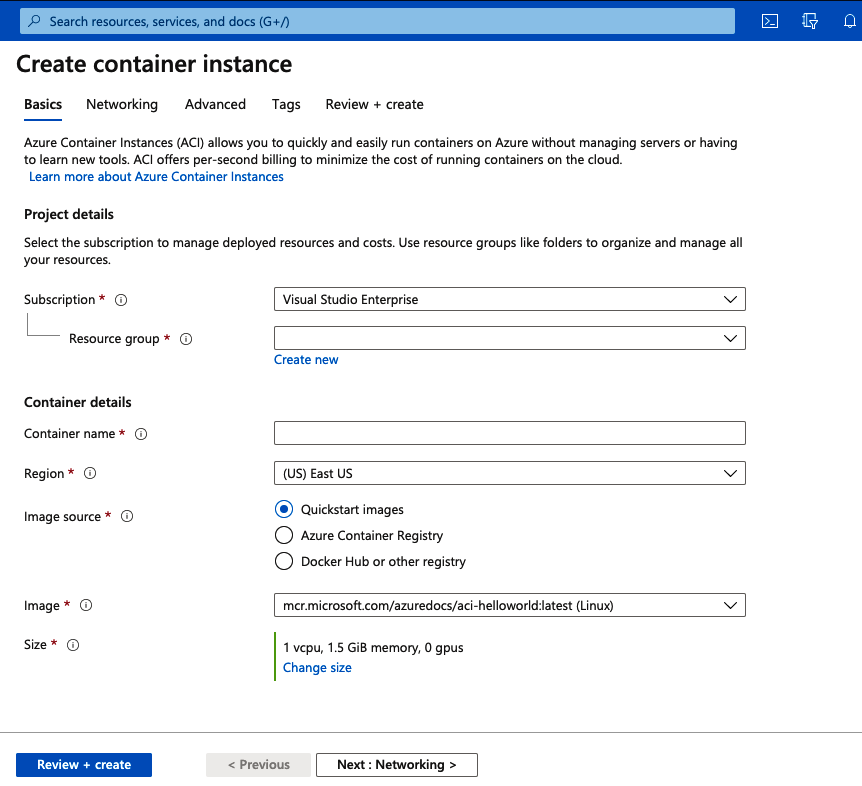
Rellena los campos siguientes:
Suscripción
Elige la suscripción en la que quieras realizar la implementación.
Grupo de recursos
Puedes usar un grupo de recursos existente o crear uno nuevo. En este caso, vamos a crear uno nuevo llamado rg-aci-test.
Nombre del contenedor
Da un nombre a tu instancia de contenedor. A la nuestra la llamaremos aci-demo.
Región
Elige tu región. Vamos a implementar en la región del este de EE. UU.
Origen de la imagen
Aquí es donde eliges la imagen del contenedor. Se te presentan tres opciones:
- Utilizar una imagen de inicio rápido de demostración que proporciona Azure.
- Utilizar una imagen que se haya cargado en Azure Container Registry.
- Utilizar una imagen cargada en Docker Hub u otro registro. Si has implementado Harbor, puedes configurarlo aquí. En este caso, vamos a elegir la imagen de inicio rápido de Nginx.
Tamaño
Aquí eliges el tipo de máquina virtual que quieres. Ten en cuenta que, cuanto mayor sea la máquina virtual, más pagarás para poder ejecutarla. En este caso, vamos a ejecutar una configuración de 1 vcpu, 1,5 GiB de memoria y 0 gpus. Esto significa que tenemos un núcleo virtual, 1 GB de memoria y ninguna tarjeta gráfica.
Cuando esté completa la configuración, haz clic en el botón Next: Networking (Siguiente: Redes) para configurar la conexión de red (Figura 3-11).
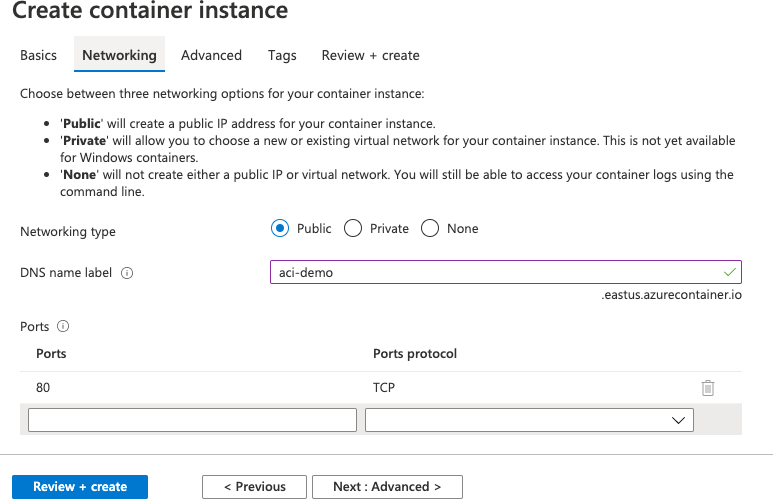
En esta demostración, vamos a asignar una IP pública a nuestra instancia de contenedor (para que podamos acceder a ella desde Internet) y luego asignaremos a la dirección IP un nombre DNS de aci-demo.eastus.azurecontainer.io (querrás usar un nombre único). A continuación, tenemos la opción de hacer que los puertos TCP o UDP estén disponibles desde fuera del contenedor.
Como estamos usando un contenedor Nginx, el puerto 80 se abre automáticamente. También puedes crear una red virtual (o una existente) y una subred si utilizas direcciones IP privadas.
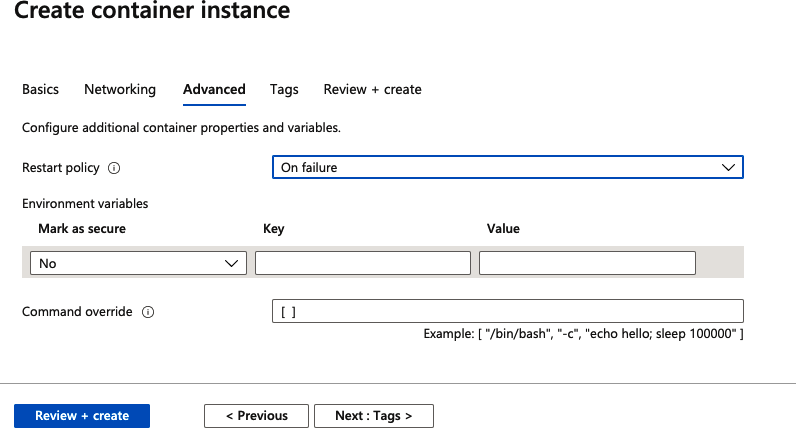
Si haces clic en el botón Next: Advanced (Siguiente: Avanzado), verás que hay otras configuraciones que puedes aplicar para lidiar con políticas de errores y variables de entorno. Para este ejemplo, no vamos a realizar ningún cambio (Figura 3-12).
Por último, haz clic en «Review + create» (Revisar + crear) y se creará la imagen del contenedor. La implementación de una imagen de inicio rápido llevará alrededor de dos minutos.
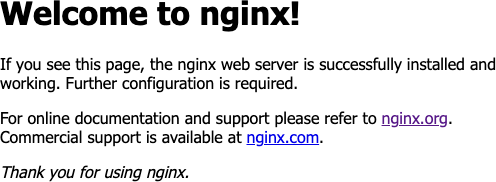
Una vez implementado el contenedor, podrás ir al nombre DNS del contenedor en un navegador de Internet y ver el banner de bienvenida «Welcome to nginx!» (consulta Figura 3-13). A través del portal de Azure, también puedes obtener una conexión de consola a la instancia.
Puedes encontrar más información sobre cómo implementar ACI en la documentación de Microsoft.
Ejecución de un motor de contenedor de Docker
Si deseas un control más preciso de tu entorno de contenedor, otra opción es ejecutar tu propio motor de contenedor de Docker (CE). La contrapartida es tener que administrar la máquina virtual subyacente en la que se ejecuta Docker.
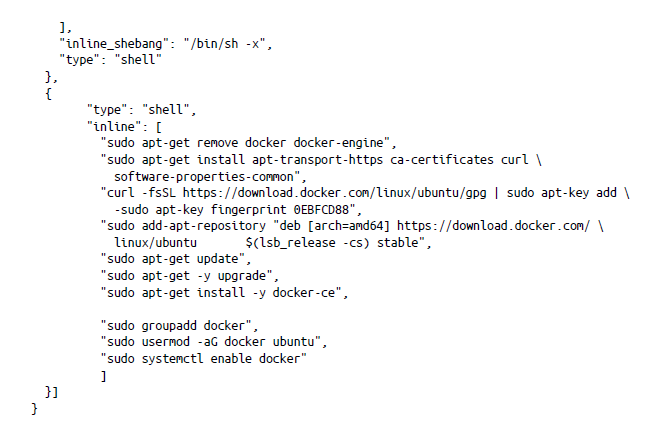
- Instala Docker CE en una máquina virtual de Azure:


Resumen
En este capítulo, hemos analizado brevemente las capas de abstracción que componen el ecosistema de contenedores. Ahora que el ecosistema de contenedores se centra firmemente en la especificación OCI y Kubernetes, está prosperando y observamos una proliferación de productos de seguridad y de red basados en el estándar OCI. En el capítulo 8, analizaremos otro estándar de contenedores, la interfaz de red de contenedores (CNI) y vamos a ver cómo aprovecharla para la configuración de red de tu contenedor