



Scikit-Learn (Part 1)
Estimators, Transformers, and Predictors: the backbone of classical Machine Learning
In the previous post we walked through the full history of NLP and how we ended up with today’s modern LLMs. It was a long ride, packed with architectures, papers, and plenty of «aha» moments.
But today, we’re coming back down to earth.
Because as powerful as Transformers and generative models are, 80% of real-world business problems are still solved with something far humbler, faster, and (above all) far more explainable: classical Machine Learning. And the tool that has dominated this space for over a decade has a name of its own.
Scikit-Learn.
The problem is that most people treat it like a black box. They copy three lines from Stack Overflow, call.fit(), and pray the model works. And when something breaks, they have no idea where to look.
This post is the cure for that.
Because before you can build a full pipeline, you need to understand the three core pieces the entire library is built on:
- Estimators
- Transformers
- Predictors
Understand these, and you understand Scikit-Learn.
Understand Scikit-Learn, and you understand 80% of classical ML.
Let’s take it step by step.
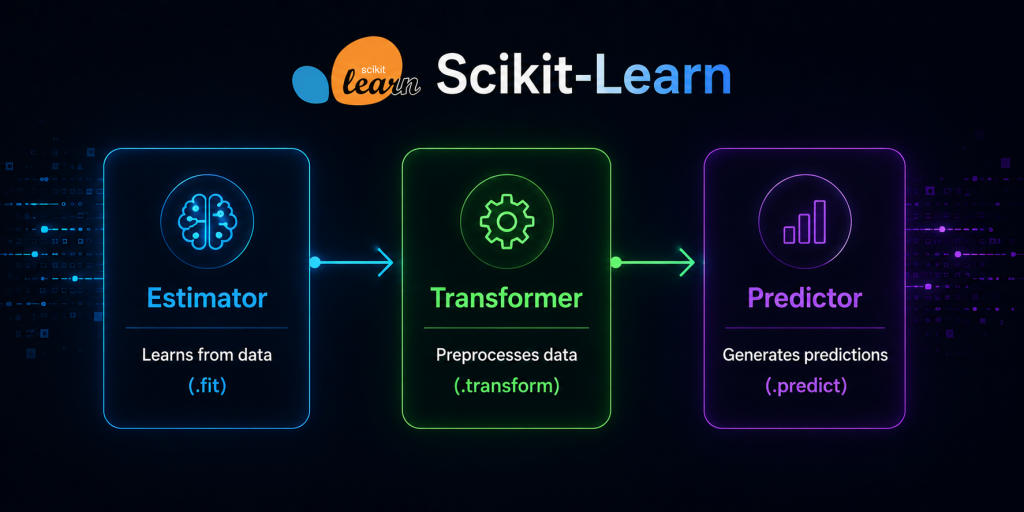
🟦 What is an Estimator? (The heart of Scikit-Learn)
In Scikit-Learn, everything is an Estimator. Literally everything.
An Estimator is any object that implements the method:
.fit(X, y)That’s it. If it has.fit(), it’s an Estimator. No magic, no complex inheritance, no hidden classes. It’s a simple contract: «give me data and I’ll learn something from it.»
Examples of Estimators
StandardScaler()PCA()LogisticRegression()RandomForestClassifier()KMeans()
As different as they may look, all of them learn something from the data:
- a model (the weights of a regression)
- a transformation (the mean and standard deviation of each column)
- a structure (the centroids of a clustering algorithm)
- a set of internal parameters that get stored for later use
The golden rule
If it learns something through
.fit(), it’s an Estimator.
And here’s the detail nobody tells you upfront: when you call.fit(), Scikit-Learn stores everything it learned as attributes ending with an underscore (scaler.mean_,model.coef_,pca.components_). That convention is your best friend when debugging: if an attribute ends in_, it was learned from the data.
What is a Transformer? (The one that reshapes your data)
A Transformer is an Estimator that, on top of.fit(), also implements:
.transform(X)In other words, it does two things:
- Learns something with
.fit() - Applies that transformation with
.transform()
Examples of Transformers
StandardScaler()→ normalizes (mean 0, std 1)MinMaxScaler()→ scales to a fixed rangeOneHotEncoder()→ encodes categorical variablesPCA()→ reduces dimensionalityTfidfVectorizer()→ vectorizes text
What does a Transformer actually do?
It takes your raw data and turns it into something the model can actually work with. Think of it as a translator: your original dataset speaks a language the model doesn’t fully understand (different scales, text-based categories, too many dimensions), and the Transformer translates it into the algorithm’s native language.
scaler = StandardScaler()
scaler.fit(X_train) # learns mean and std
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test) # SAME transformation, NOT refit⚠️ Critical detail:.fit()is called only on the training data. The test set is transformed using whatever was learned from train. If youfiton the test set, you’re leaking information from the future into your model. That’s called data leakage, and it’s one of the most expensive mistakes in all of ML.
For convenience, Scikit-Learn offers.fit_transform(), which does both steps in one go. Use it on train, never on test.
What is a Predictor? (The one that predicts)
A Predictor is an Estimator that implements:
.predict(X)That is:
- Learns patterns with
.fit(X, y) - Generates predictions with
.predict(X)
Examples of Predictors
LogisticRegression()RandomForestClassifier()SVC()KNeighborsClassifier()LinearRegression()
What does a Predictor return?
It depends on the problem, but always something actionable:
- a class (spam / not spam)
- a numeric value (estimated price)
- a probability (via
.predict_proba()when applicable)
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)Many predictors also implement.score()for a quick evaluation, plus.predict_proba()or.decision_function()whenever the notion of confidence makes sense. That consistent interface is exactly what makes swapping one model for another almost trivial.
How they fit together: the natural flow of classical ML
The full flow of any classical ML project boils down to three steps:
- Estimator → learns something from the data
- Transformer → preprocesses the data so the model can understand it
- Predictor → trains and predicts
A typical example, written by hand:
scaler = StandardScaler() # Transformer
model = LogisticRegression() # Predictor
# Preprocessing
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Model
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)It works. But it has problems:
- It’s fragile: add one new step and you have to remember to apply it on both train and test.
- It’s leakage-prone: one misplaced
fit_transformand your validation is ruined. - It’s hard to validate with cross-validation without rewriting half the script.
- It’s impossible to maintain once your pipeline grows to 8 or 10 steps.
That’s why Scikit-Learn offers a much better way to do this. And we’ll cover it in the next post.
Why do these three categories exist?
It’s not a design quirk. This separation is exactly what has made Scikit-Learn an industrial-grade library for over 15 years.
The API is built to be:
- modular → each step does one thing only
- consistent → every object speaks the same «language» (
fit,transform,predict) - swappable → replacing
LogisticRegressionwithRandomForestis a one-line change - scalable → same methods whether you have 100 rows or 10 million
- easy to automate → tools like
GridSearchCVwork out of the box with any object that respects the contract
Thanks to this structure, you can:
- swap a model without touching the rest of your code
- chain steps inside a
Pipeline - validate everything honestly with
cross_val_score - automate hyperparameter search with
GridSearchCV - build clean, production-ready pipelines
And that’s exactly what we’ll get into next.
What’s coming next? (Part 2)
The full Pipeline flow in Scikit-Learn.
In the next article we’ll cover:
- how to combine Transformers + Predictors into a single object
- how to build real pipelines with
PipelineandColumnTransformer - how to systematically prevent data leakage
- how to validate properly with cross-validation
- how to get a pipeline ready for production
- how to plug all of this into your AI Class project
That’s the post where your project stops looking like a messy notebook and starts looking like a proper, professional system.
TL;DR
- In Scikit-Learn, everything is an Estimator.
- A Transformer =
.fit()+.transform(). - A Predictor =
.fit()+.predict(). - Learned attributes always end with an underscore (
mean_,coef_). - This structure is what makes pipelines clean, modular, and scalable.
- Understanding it is the mandatory prerequisite before building a full pipeline.