Los contenedores son uno de los componentes de la infraestructura más comentados de la última década. Los contenedores no son una tecnología nueva; han estado ahí desde hace tiempo. Han estado presentes en el mundo de Linux durante más de dos décadas. Los contenedores no eran muy conocidos en la comunidad de desarrolladores debido a su complejidad y al hecho de que no había mucha documentación sobre ellos. Sin embargo, a principios de esta década, en 2013, se lanzó una empresa conocida como Docker que cambió la percepción y adopción de contenedores en el mundo de los desarrolladores.
Docker escribió un contenedor de API robusto sobre los contenedores LXC de Linux existentes y facilitó a los desarrolladores la creación, administración y destrucción de contenedores desde la interfaz de la línea de comandos. Al crear contenedores en aplicaciones, el número de contenedores que tenemos puede aumentar drásticamente con el tiempo y podemos llegar a un punto donde necesitamos administrar cientos o incluso miles de contenedores. Aquí es donde los orquestadores de contenedores entran en juego y Kubernetes es uno de ellos. Con Kubernetes, podemos automatizar la implementación, el escalado, las redes y la administración de contenedores.
En este capítulo, veremos:
- Conceptos introductorios de los contenedores
- Conceptos de Kubernetes
- Elementos importantes que hacen que Kubernetes funcione
- Arquitectura de soluciones con Azure Kubernetes Service
Ahora que ya sabes para qué se utiliza Kubernetes, empecemos de cero y hablemos de qué
son los contenedores, cómo se orquestan con Kubernetes y mucho más.
Introducción a los contenedores
Los contenedores se denominan sistemas de virtualización en el nivel del sistema
operativo. Se hospedan en un sistema operativo que se ejecuta en un servidor físico
o virtual. La naturaleza de la implementación depende del sistema operativo host.
Por ejemplo, los contenedores de Linux se inspiran en cgroups; por el contrario, los
contenedores de Windows son máquinas virtuales casi ligeras con un tamaño pequeño.
Los contenedores son verdaderamente multiplataforma. Las aplicaciones en contenedores
se pueden ejecutar en cualquier plataforma, como Linux, Windows o Mac, de manera
uniforme sin necesidad de realizar cambios, lo que las hace altamente portátiles. Esto los
convierte en una tecnología perfecta para que las organizaciones los adopten, ya que son
independientes de la plataforma.
Además, los contenedores pueden ejecutarse en cualquier entorno de cloud o entorno
on-premises sin necesidad de realizar cambios. Esto significa que las organizaciones
tampoco están vinculadas a un único proveedor de cloud si implementan contenedores
como su plataforma de hosting en el cloud. Pueden mover su entorno desde el entorno
on-premises y migrar mediante lift-and-shift al cloud.
Los contenedores proporcionan todas las ventajas que suelen estar disponibles con las
máquinas virtuales. Tienen sus propias direcciones IP, nombres DNS, identidades, pilas
de red, sistemas de archivos y otros componentes que dan a los usuarios la impresión de
utilizar un entorno de sistema operativo totalmente nuevo. En segundo plano, el entorno
de ejecución de Docker virtualiza varios componentes del nivel del kernel del sistema
operativo para proporcionar esa impresión.
Todas estas ventajas proporcionan inmensos beneficios a las organizaciones que adoptan
la tecnología de contenedores, y Docker es uno de los precursores en este sentido. Hay
otras opciones de entorno de ejecución de contenedores disponibles, como CoreOS rkt
(se pronuncia como «rocket», retirado de producción), Mesos Containerizer y contenedores
LXC. Las organizaciones pueden adoptar la tecnología con la que se sientan cómodas.
Antes los contenedores no estaban disponibles en el mundo de Windows; solo estuvieron
disponibles para Windows 10 y Windows Server 2016. Sin embargo, los contenedores son
ahora ciudadanos de primera clase en el mundo de Windows.
Como se ha mencionado en la introducción, los contenedores deben supervisarse, regularse
y administrarse bien, al igual que cualquier otro componente de la infraestructura dentro
de un ecosistema. Es necesario implementar un orquestador, como Kubernetes, que pueda
ayudarte a hacerlo fácilmente. En la siguiente sección, conocerás los fundamentos de
Kubernetes, incluidas sus ventajas.
Fundamentos de Kubernetes
Muchas organizaciones se siguen preguntando si necesitan Kubernetes o algún orquestador
de contenedores. Cuando pensamos en la administración de contenedores a gran escala,
tenemos que pensar en varios puntos, como el escalado, el equilibrio de carga, la
administración del ciclo de vida, la entrega continua, el registro y la supervisión, etc.
Puede que te preguntes: «¿No se supone que los contenedores deben hacer todo eso?».
La respuesta es que los contenedores son solo una pieza de bajo nivel del rompecabezas.
Las ventajas reales se obtienen a través de las herramientas que se encuentran encima de
los contenedores. Al final, necesitamos algo que nos ayude con la orquestación.
Kubernetes es una palabra griega, κυβερνήτης, que significa «timonel» o «capitán del barco».
Al hilo del tema marítimo de los contenedores de Docker, Kubernetes es el capitán del
barco. Kubernetes a menudo se denota como K8s, donde 8 representa las ocho letras entre
«K» y «s» en la palabra «Kubernetes».
Como se ha mencionado anteriormente, los contenedores son más ágiles que las máquinas
virtuales. Pueden crearse en cuestión de segundos y destruirse con la misma rapidez.
Tienen un ciclo de vida similar a las máquinas virtuales; sin embargo, deben supervisarse,
controlarse y administrarse activamente dentro de un entorno.
Es posible administrarlos usando tu conjunto de herramientas existente. Aun así, las
herramientas especializadas, como Kubernetes, pueden proporcionar ventajas valiosas:
- Kubernetes es una recuperación automática por naturaleza. Cuando un pod
(entendido como «contenedor» por ahora) cae dentro de un entorno de Kubernetes,
Kubernetes se asegurará de que se cree un nuevo pod en otro lugar, ya sea
en el mismo nodo o en otro nodo, para responder a las solicitudes en nombre
de la aplicación. - Kubernetes también facilita el proceso de actualización de una aplicación. Proporciona
características «out of the box» que te ayudan a realizar varios tipos de actualizaciones
con la configuración original. - Ayuda a habilitar implementaciones blue-green. En este tipo de implementación,
Kubernetes implementará la nueva versión de la aplicación junto con la antigua y,
una vez que se haya confirmado que la nueva aplicación funciona como se esperaba,
se realizará un cambio de DNS para cambiar a la nueva versión de la aplicación.
La implementación de la aplicación antigua puede seguir existiendo con fines de
reversión. - Kubernetes también ayuda a implementar una estrategia de implementación
de actualización gradual. En este contexto, Kubernetes implementará la nueva
versión de la aplicación servidor por servidor y desmontará la implementación
anterior también servidor por servidor. Seguirá con esta actividad hasta que no
queden más servidores de la antigua implementación. - Kubernetes se puede implementar en un centro de datos on-premises o en el cloud
mediante el paradigma de la infraestructura como servicio (IaaS). Esto significa que
los desarrolladores primero crean un grupo de máquinas virtuales e implementan
Kubernetes sobre él. También existe el enfoque alternativo al uso de Kubernetes
como oferta de plataforma como servicio (PaaS). Azure proporciona un servicio
PaaS conocido como Azure Kubernetes Service (AKS), que proporciona un entorno
de Kubernetes «out of the box» a los desarrolladores.
En lo que respecta a la implementación, Kubernetes se puede implementar de dos maneras:
- Clústeres no administrados: los clústeres no administrados se pueden crear
instalando Kubernetes y cualquier otro paquete relevante en una máquina sin sistema
operativo o una máquina virtual. En un clúster no administrado, habrá nodos maestros
y de trabajo, anteriormente conocidos como esbirros. Los nodos maestros y de trabajo
trabajan mano a mano para orquestar los contenedores. Si te preguntas cómo se
consigue esto, más adelante en este capítulo exploraremos la arquitectura completa
de Kubernetes. Ahora mismo, sabemos que hay nodos maestros y de trabajo.
- Clústeres administrados: normalmente el proveedor de cloud proporciona los
clústeres administrados; el proveedor de cloud administra la infraestructura por ti.
En Azure, este servicio se llama AKS. Azure proporcionará soporte activo con respecto
a la aplicación de revisiones y la administración de la infraestructura. Con IaaS, las
organizaciones tienen que garantizar la disponibilidad y escalabilidad de los nodos
y la infraestructura por su cuenta. En el caso de AKS, el componente maestro no será
visible porque lo administra Azure. Sin embargo, los nodos de trabajo (esbirros) serán
visibles y se implementarán en un grupo de recursos independiente para que puedas
acceder a los nodos si es necesario.
Algunas de las principales ventajas de usar AKS en clústeres no administrados son:
- Si utilizas clústeres no administrados, debes trabajar para conseguir una solución
altamente disponible y escalable. Además de eso, debes tener una administración
adecuada de las actualizaciones para instalar actualizaciones y revisiones. Por otro
lado, en AKS, Azure lo administra completamente, lo que permite a los desarrolladores
ahorrar tiempo y ser más productivos. - Integración nativa con otros servicios, como Azure Container Registry para
almacenar las imágenes de contenedor de forma segura, Azure DevOps para integrar
canalizaciones de CI/CD, Azure Monitor para el registro y Azure Active Directory para
la seguridad. - Escalabilidad y velocidad de startup más rápida.
- Compatibilidad con los conjuntos de escalado de máquinas virtuales.
Aunque no hay diferencia en términos de la funcionalidad básica de estas dos
implementaciones, la forma de implementación de IaaS proporciona la flexibilidad de
añadir nuevos complementos y configuración inmediatamente, algo que el equipo de Azure
podría tardar un tiempo en poner a disposición con AKS. Además, las nuevas versiones de
Kubernetes están disponibles en AKS bastante rápido, sin demasiado retraso.
Hemos abarcado los conceptos básicos de Kubernetes. En este punto, tal vez te preguntes
cómo Kubernetes consigue todo esto. En la siguiente sección vamos a ver los componentes
de Kubernetes y cómo trabajan juntos.
Arquitectura de Kubernetes
El primer paso para entender Kubernetes es entender su arquitectura. En la siguiente
sección vamos a ver los detalles de cada componente, pero obtener información general
de la arquitectura te ayudará a comprender la interacción entre los componentes.
Clústeres de Kubernetes
Kubernetes necesita nodos físicos o virtuales para instalar dos tipos de componentes:
- Componentes de plano de control de Kubernetes o componentes maestros
- Nodos de trabajo (esbirros) de Kubernetes o componentes no maestros
En la Figura 14.1 se muestra un diagrama que ofrece información general de la arquitectura
de Kubernetes. Más adelante, veremos los componentes con más detalle:
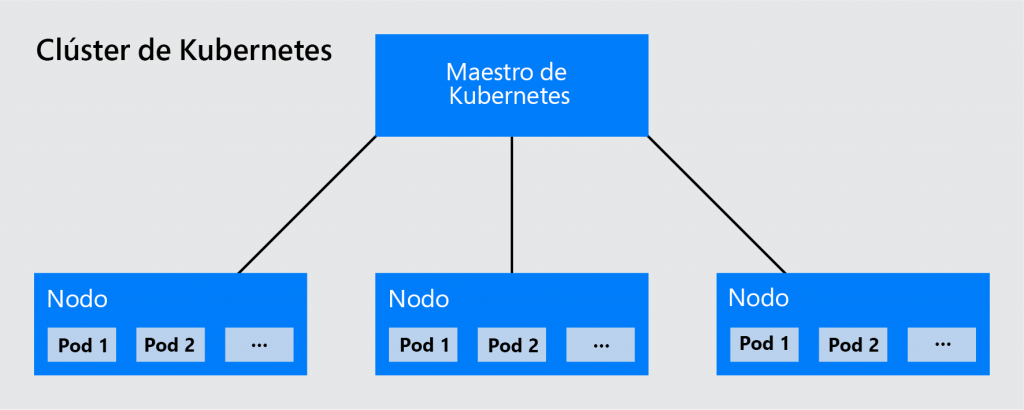
Los componentes del plano de control son responsables de administrar y controlar el
entorno de Kubernetes y los esbirros de Kubernetes.
Todos los nodos juntos, tanto el maestro como los esbirros, forman el clúster. En otras
palabras, un clúster es una colección de nodos. Son virtuales o físicos, están conectados
entre sí y son accesibles mediante la pila de red del TCP. El mundo exterior no tendrá ni
idea del tamaño o la capacidad de tu clúster, ni siquiera de los nombres de los nodos de
trabajo. Lo único que conocen los nodos es la dirección del servidor de API a través del
cual interactúan con el clúster. Para ellos, el clúster es un equipo grande que ejecuta sus
aplicaciones.
Es Kubernetes quien decide internamente una estrategia adecuada, utilizando controladores,
para elegir un nodo válido y en buen estado que pueda ejecutar la aplicación sin problemas.
Los componentes del plano de control se pueden instalar en una configuración de alta
disponibilidad. Hasta ahora, hemos hablado de los clústeres y de cómo funcionan. En la
siguiente sección vamos a ver los componentes de un clúster.
Componentes de Kubernetes
Los componentes de Kubernetes se dividen en dos categorías: componentes maestros y
componentes de nodo. Los componentes maestros también se conocen como el plano de
control del clúster. El plano de control es responsable de administrar los nodos de trabajo y
los pods del clúster. La autoridad de toma de decisiones de un clúster es el plano de control
y también se encarga de la detección y las respuestas relacionadas con los eventos del
clúster. En la Figura 14.2 se describe la arquitectura completa de un clúster de Kubernetes:
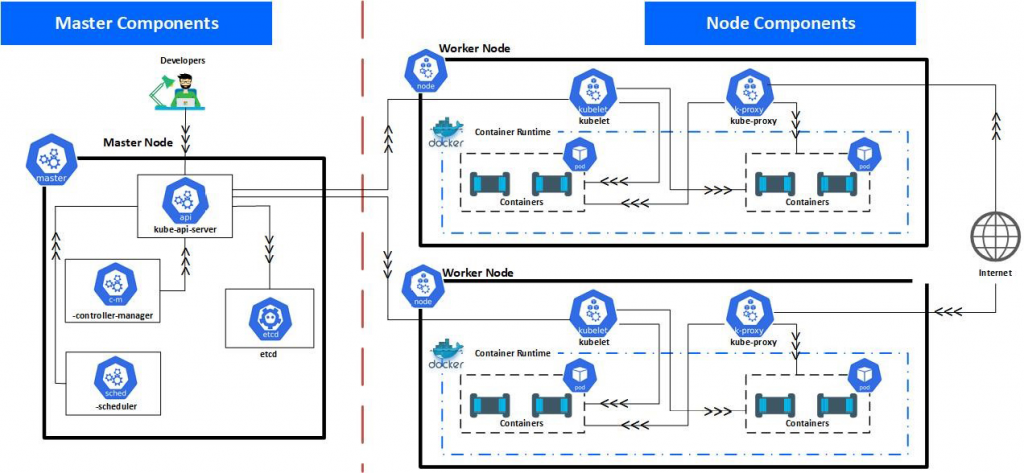
Es necesario comprender cada uno de estos componentes para administrar un clúster
correctamente. Sigamos adelante y analicemos cuáles son los componentes maestros:
- Servidor de API: el servidor de API es, sin duda, el cerebro de Kubernetes. Es el
componente central que permite todas las actividades dentro de Kubernetes.
Cada solicitud del cliente, con algunas excepciones, termina con el servidor de
API, que decide el flujo de la solicitud. Es el único responsable de interactuar con
el servidor etcd. - etcd: etcd es el almacén de datos de Kubernetes. Solo el servidor de API puede
comunicarse con etcd y, además, puede realizar las actividades Crear, Leer,
Actualizar y Eliminar (CRUD) en etcd. Cuando una solicitud termina con el servidor
de API, después de la validación, el servidor de API puede realizar cualquier operación
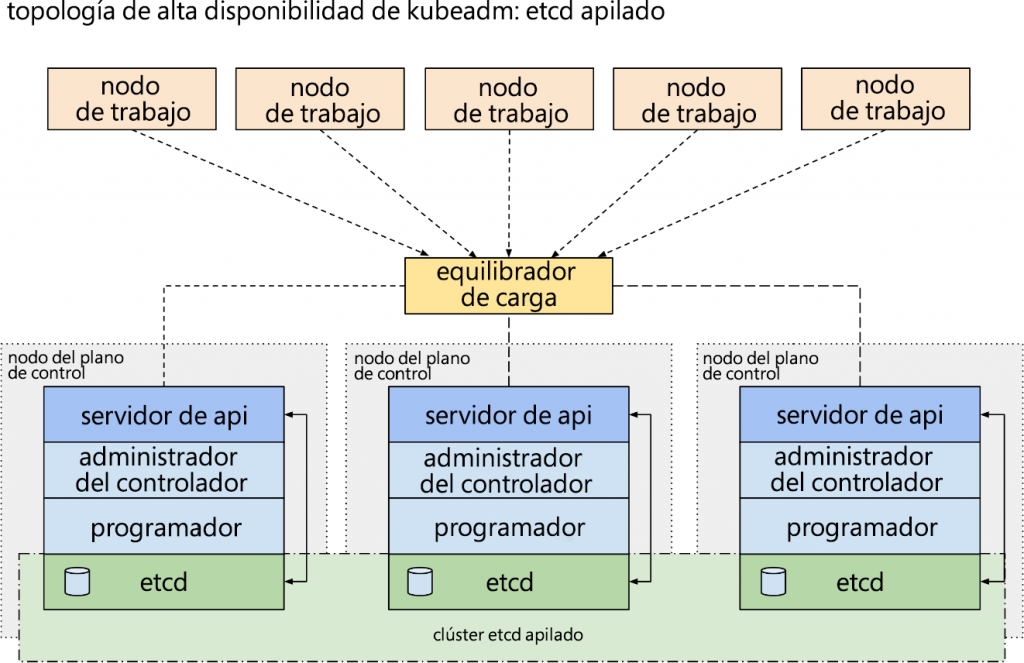
CRUD, en función de la solicitud etcd. etcd es un almacén de datos distribuido y de
alta disponibilidad. Puede haber varias instalaciones de etcd, cada una con una copia
de los datos, y cualquiera de ellas puede atender las solicitudes del servidor de API.
En la Figura 14.3 puedes ver que hay varias instancias ejecutándose en el plano de
control para proporcionar alta disponibilidad:
- Administrador del controlador: el administrador del controlador es el caballo
de batalla de Kubernetes. Mientras el servidor de API recibe las solicitudes,
el administrador del controlador realiza el trabajo real en Kubernetes. El administrador
del controlador, como su nombre indica, es el administrador de los controladores.
Hay varios controladores en un nodo maestro de Kubernetes y cada uno es responsable
de administrar un único controlador.
La principal responsabilidad de un controlador es administrar un único recurso
en un entorno de Kubernetes. Por ejemplo, hay un administrador del controlador
de replicación para administrar los recursos del controlador de replicación y un
controlador ReplicaSet para administrar ReplicaSets en un entorno de Kubernetes.
El controlador mantiene un control en el servidor de API y, cuando recibe una
solicitud de un recurso administrado por él, el controlador realiza su trabajo.
Una de las principales responsabilidades de los controladores es seguir funcionando
en un bucle y garantizar que Kubernetes esté en el estado deseado. Si hay alguna
desviación del estado deseado, los controladores deben devolverlo al estado deseado.
Un controlador de implementación busca nuevos recursos de implementación
creados por el servidor de API. Si se encuentra un nuevo recurso de implementación,
el controlador de implementación crea un nuevo recurso ReplicaSet y garantiza que
el ReplicaSet siempre esté en el estado deseado. Un controlador de replicación sigue
ejecutándose en un bucle y comprueba si el número real de pods del entorno coincide
con el número deseado de pods. Si un pod muere por cualquier motivo, el controlador
de replicación encontrará que el recuento real se ha reducido en uno y programará un
nuevo pod en el mismo u otro nodo.
- Programador: el trabajo de un programador es programar los pods en nodos esbirro
de Kubernetes. No es responsable de crear pods. Es únicamente responsable de
asignar pods a los nodos esbirro de Kubernetes. Para ello, tiene en cuenta el estado
actual de los nodos, su disponibilidad, sus recursos disponibles y la definición del
pod. Un pod podría tener una preferencia con respecto a un nodo específico y el
programador tendrá en cuenta estas solicitudes mientras programa pods para nodos.
Ahora exploraremos los componentes del nodo que se implementan en cada uno de los
nodos de trabajo del clúster:
- Kubelet: mientras el servidor de API, el programador, los controladores y etcd se
implementan en nodos maestros, los kubelets se implementan en nodos esbirro.
Actúan como agentes para los componentes maestros de Kubernetes y son
responsables de administrar los pods localmente en los nodos. Cada nodo tiene
un kubelet. Un kubelet recibe comandos de los componentes maestros y también
proporciona información de estado, supervisión y actualización sobre los nodos
y los pods a los componentes maestros, como el servidor de API y el administrador
del controlador. Son el conducto de comunicación administrativa entre los nodos
maestro y esbirro. - Proxy de Kube: el proxy de Kube, al igual que los kubelets, se implementa en nodos
esbirro. Es responsable de supervisar pods y servicios, así como de actualizar
las reglas de firewall de iptables y netfilter locales con cualquier cambio en la
disponibilidad de pods y servicios. Esto garantiza que la información de enrutamiento
de los nodos se actualice cuando se crean pods y servicios nuevos o se eliminan los
pods y servicios existentes.
- Entorno de ejecución de contenedor: actualmente hay muchos proveedores de
contenedores en el ecosistema. Docker es el más famoso de todos ellos, aunque
otros también están ganando popularidad. Por ello, en nuestra arquitectura,
indicamos el entorno de ejecución de contenedor con el logotipo de Docker.
Kubernetes es un orquestador de contenedores genérico. No se puede asociar
estrechamente con ningún proveedor de contenedor único, como Docker.
Debe ser posible utilizar cualquier entorno de ejecución de contenedor en los
nodos esbirro para administrar el ciclo de vida de los contenedores.
Para ejecutar contenedores en pods, se ha desarrollado un estándar basado en el sector
conocido como interfaz de entorno de ejecución de contenedor (CRI) que las empresas
líderes utilizan. El estándar proporciona reglas que se deben seguir para lograr la
interoperabilidad con orquestadores como Kubernetes. Los kubelets no saben qué binarios
de contenedor están instalados en los nodos. Pueden ser binarios de Docker o cualquier
otro binario.
A medida que estos entornos de ejecución de contenedor se desarrollan con un estándar
común basado en el sector, independientemente del entorno de ejecución que utilices, los
kubelets podrán comunicarse con el entorno de ejecución de contenedor. Esto desvincula
la administración de contenedores de la administración de clústeres de Kubernetes.
Las responsabilidades del entorno de ejecución de contenedor incluyen la creación de
contenedores, la administración de la pila de red de los contenedores y la administración
de la red de puente. Dado que la administración de contenedores es independiente de la
administración del clúster, Kubernetes no interferirá en las responsabilidades del entorno
de ejecución de contenedor.
Los componentes que hemos comentado son aplicables tanto a clústeres de AKS
administrados como no administrados. Sin embargo, los componentes maestros no se
exponen al usuario final, ya que Azure lo administra todo en el caso de AKS. Más adelante
en este capítulo abarcaremos la arquitectura de AKS. Aprenderás acerca de los clústeres
no administrados y entenderás mejor las diferencias entre estos sistemas.
A continuación, conocerás algunos de los recursos de Kubernetes más importantes, también
conocidos como los primitivos, que son conocimientos que se aplican tanto a los clústeres
no administrados como a los clústeres de AKS.
Primitivos de Kubernetes
Has aprendido que Kubernetes es un sistema de orquestación utilizado para implementar
y administrar contenedores. Kubernetes define un conjunto de componentes principales,
que también se conocen como primitivos. Estos primitivos juntos pueden ayudarnos
a implementar, mantener y escalar aplicaciones en contenedores. Vamos a echar un
vistazo a cada uno de los primitivos y a entender sus roles.
Pod
Los pods son las unidades más básicas de implementación en Kubernetes. La pregunta
inmediata que surge a una mente curiosa es en qué se diferencia un pod de un
contenedor. Los pods son contenedores encima de los contenedores. En otras palabras,
los contenedores están dentro de los pods. Puede haber varios contenedores dentro de un
pod; sin embargo, la práctica recomendada es tener una relación entre un solo pod y un
solo contenedor. Esto no significa que no podamos tener más de un contenedor en un pod.
Varios contenedores en un pod también está bien, siempre y cuando haya un contenedor
principal y el resto sean contenedores complementarios. También hay patrones, como los
patrones de sidecar, que se pueden implementar con pods de varios contenedores.
Cada pod tiene su propia dirección IP y pila de red. Todos los contenedores comparten la
interfaz de red y la pila. Todos los contenedores de un pod se pueden alcanzar localmente
utilizando el nombre de host.
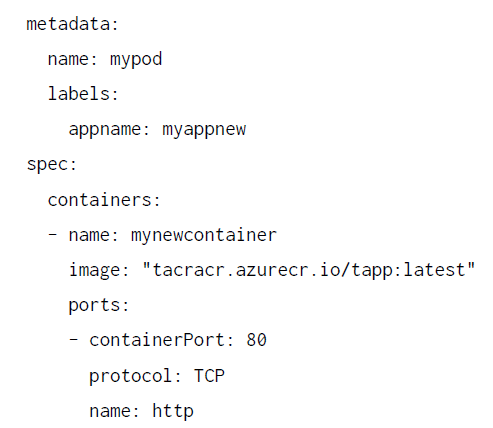
En las siguientes líneas de código se muestra una definición simple de pod en formato YAML:

La definición de pod que se muestra tiene un nombre y define algunas etiquetas, que puede
usar el recurso de servicio para exponerse a otros pods, nodos y recursos personalizados
externos. También define un solo contenedor en función de una imagen personalizada
almacenada en Azure Container Registry y abre el puerto 80 para el contenedor.
Servicios
Kubernetes permite crear pods con varias instancias. Estos pods deben ser accesibles
desde cualquier pod o nodo dentro de un clúster. Es posible utilizar la dirección IP
de un pod directamente y acceder al pod. Sin embargo, esto no es lo ideal. Los pods
son efímeros y pueden obtener una nueva dirección IP si el pod anterior ha fallado.
En tales casos, la aplicación se dividirá fácilmente. Kubernetes proporciona servicios,
que desvinculan las instancias de pods de sus clientes. Los pods pueden crearse
y destruirse, pero la dirección IP de un servicio de Kubernetes permanece constante
y estable. Los clientes pueden conectarse a la dirección IP del servicio, que a su vez
tiene un punto de conexión para cada pod al que puede enviar solicitudes. Si hay varias
instancias de pods, cada una de sus direcciones IP estará disponible para el servicio como
objeto de punto de conexión. Cuando un pod falla, los puntos de conexión se actualizan
para reflejar las instancias de pods actuales junto con sus direcciones IP.
Los servicios están muy desacoplados con los pods. La intención principal de los servicios
es poner en cola los pods que tienen etiquetas en sus definiciones de selector de servicio.
Un servicio define selectores de etiquetas y, en función de los selectores de etiquetas,
se agregan direcciones IP de pods al recurso de servicio. Los pods y los servicios pueden
administrarse de forma independiente entre sí.
Un servicio proporciona varios tipos de esquemas de dirección IP. Hay cuatro tipos de
servicios: ClusterIP, NodePort, LoadBalancer y controlador de entrada mediante Application
Gateway.
El esquema más fundamental se conoce como ClusterIP y es una dirección IP interna a la
que solo se puede acceder desde dentro del clúster. El esquema de ClusterIP se muestra
en la Figura 14.4:
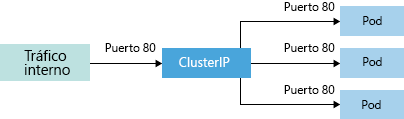
ClusterIP también permite la creación de NodePort, mediante el cual obtiene un ClusterIP.
Sin embargo, también puede abrir un puerto en cada uno de los nodos de un clúster.
Se puede acceder a los pods mediante direcciones ClusterIP y utilizando una combinación
de la IP del nodo y el puerto del nodo:
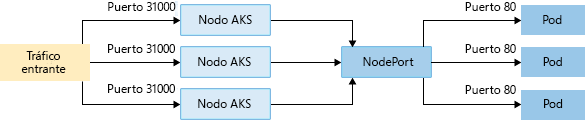
Los servicios pueden hacer referencia no solo a pods, sino también a puntos de conexión
externos. Por último, los servicios también permiten la creación de un servicio basado en
equilibrador de carga que sea capaz de recibir solicitudes externamente y redirigirlas a una
instancia de pod mediante ClusterIP y NodePort internamente:
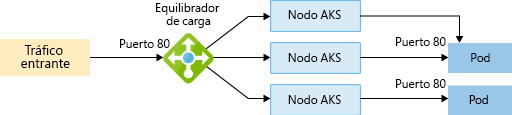
Hay un tipo final de servicio conocido como controlador de entrada, que proporciona
funcionalidades avanzadas como el enrutamiento basado en URL, como se muestra en
la Figura 14.7:
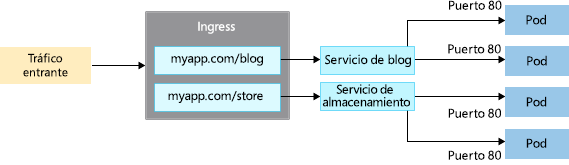
A continuación, se muestra una definición de servicio en formato YAML:

Esta definición de servicio crea un servicio basado en equilibrador de carga utilizando
selectores de etiquetas.
Implementaciones
Las implementaciones de Kubernetes son recursos de nivel superior en comparación con
los ReplicaSets y los pods. Las implementaciones proporcionan funcionalidad relacionada
con la actualización y el lanzamiento de una aplicación. Los recursos de implementación
crean un ReplicaSet y el ReplicaSet administra el pod. Es importante comprender la
necesidad de recursos de implementación cuando ya existen ReplicaSets.
Las implementaciones desempeñan un papel importante en la actualización de las
aplicaciones. Si una aplicación ya está en producción y es necesario implementar una
nueva versión de la aplicación, tienes algunas opciones:
- Eliminación de los pods existentes y creación de nuevos pods: en este método hay
tiempo de inactividad para la aplicación, por lo que solo debe usarse si el tiempo de
inactividad es aceptable. Existe el riesgo de un aumento del tiempo de inactividad si
la implementación contiene errores y tienes que volver a una versión anterior.
- Implementación blue-green: en este método, los pods existentes siguen funcionando
y se crea un nuevo conjunto de pods con la nueva versión de la aplicación. Los nuevos
pods no son accesibles externamente. Una vez que las pruebas se han completado
correctamente, Kubernetes comienza a apuntar al nuevo conjunto de pods. Los pods
antiguos pueden permanecer tal como están o se pueden eliminar posteriormente. - Actualizaciones graduales: en este método, los pods existentes se eliminan de uno en
uno mientras que los nuevos pods para la nueva versión de la aplicación se crean de
uno en uno. Los nuevos pods se implementan paulatinamente, mientras que los pods
antiguos se reducen progresivamente, hasta que alcanzan un recuento de cero.
Todos estos enfoques tendrían que llevarse a cabo manualmente sin un recurso de
implementación. Un recurso de implementación automatiza todo el proceso de lanzamiento
y actualización. También puede ayudar a volver automáticamente a una versión anterior si
hay algún problema con la implementación actual.
En la siguiente lista de código se muestra una definición de implementación:

Es importante tener en cuenta que una implementación tiene una propiedad strategy,
que determina si se utiliza la estrategia recreate o RollingUpdate. recreate borrará
todos los pods existentes y creará nuevos pods. También contiene detalles de
configuración relacionados con RollingUpdate que proporcionan el número máximo
de pods que se pueden crear y destruir en una sola ejecución.
Controlador de replicación y ReplicaSet
El recurso de controlador de replicación de Kubernetes garantiza que un número deseado
especificado de instancias de pods siempre se ejecuten dentro de un clúster. El controlador
de replicación observa cualquier desviación del estado deseado y crea nuevas instancias de
pods para satisfacer el estado deseado.
Los ReplicaSets son la nueva versión del controlador de replicación. Los ReplicaSets
proporcionan la misma funcionalidad que los controladores de replicación, con algunas
funcionalidades avanzadas. La principal de ellas es la gran capacidad para definir los
selectores asociados con los pods. Con los ReplicaSets, es posible definir las expresiones
dinámicas que faltaban con los controladores de replicación.
Se recomienda utilizar ReplicaSets en lugar de controladores de replicación.
En la siguiente lista de código se muestra un ejemplo de definición de un recurso ReplicaSet:

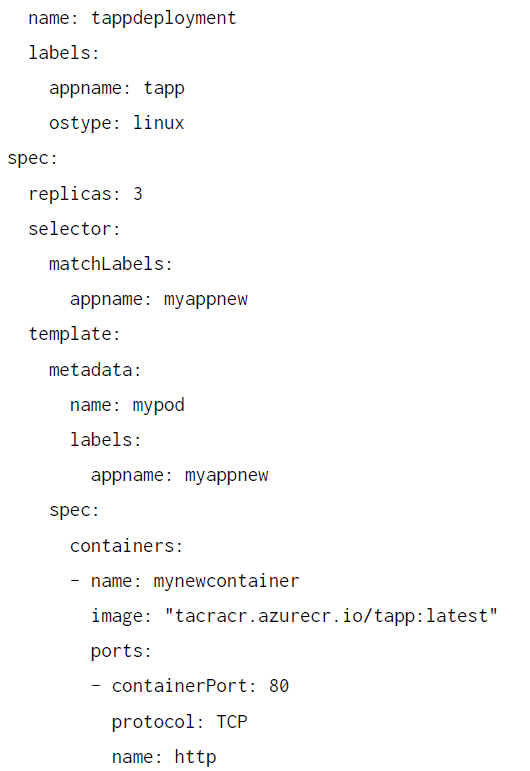
Es importante tener en cuenta que los ReplicaSets tienen una propiedad replicas,
que determina el recuento de instancias de pods, una propiedad selector, que define
los pods que debe administrar ReplicaSet y, por último, la propiedad template, que
define el propio pod.
ConfigMaps y secretos
Kubernetes proporciona dos recursos importantes para almacenar datos de configuración.
ConfigMaps se utiliza para almacenar datos de configuración general que no son sensibles
a la seguridad. Los datos genéricos de configuración de la aplicación, como los nombres
de carpetas, los nombres de volúmenes y los nombres de DNS, se pueden almacenar
en ConfigMaps. Por otro lado, los datos confidenciales, como credenciales, certificados
y secretos, deben almacenarse en recursos de secretos. Estos datos de secretos se cifran
y almacenan en el almacén de datos de etcd de Kubernetes.
Tanto los datos de ConfigMaps como los de secretos pueden estar disponibles como
variables de entorno o volúmenes dentro de pods.
La definición del pod que quiere consumir estos recursos debe incluir una referencia
a ellos. Ahora hemos tratado los primitivos de Kubernetes y los roles de cada uno de
los componentes principales. A continuación, vas a descubrir la arquitectura de AKS.
Arquitectura de AKS
En la sección anterior, hemos explicado la arquitectura de un clúster no administrado.
Ahora, vamos a explorar la arquitectura de AKS. Cuando leas esta sección, podrás señalar
las principales diferencias entre la arquitectura de los clústeres no administrados
y administrados (AKS, en este caso).
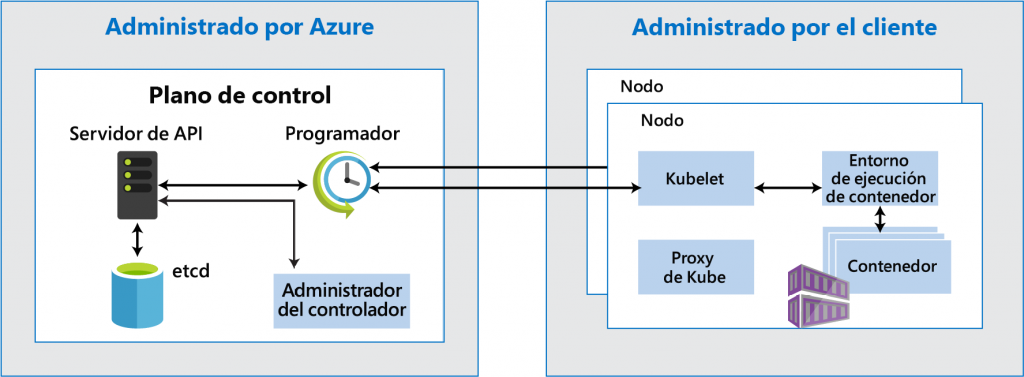
Cuando se crea una instancia de AKS, solo se crean los nodos de trabajo. Azure administra los
componentes maestros. Los componentes maestros son el servidor de API, el programador,
etcd y el administrador del controlador, que hemos comentado anteriormente. Los kubelets
y el proxy de Kube se implementan en los nodos de trabajo. La comunicación entre los nodos
y los componentes maestros se produce mediante kubelets, que actúan como agentes para
los clústeres de Kubernetes para el nodo:
Cuando un usuario solicita una instancia de pod, el usuario solicita el terreno con el servidor
de API. El servidor de API comprueba y valida los detalles de la solicitud y los almacena
en etcd (el almacén de datos del clúster) y también crea el recurso de implementación
(si la solicitud de pod se ajusta alrededor de un recurso de implementación). El controlador
de implementación está atento a la creación de nuevos recursos de implementación.
Si ve uno, crea un recurso ReplicaSet basado en la definición proporcionada en la
solicitud del usuario.
El controlador ReplicaSet mantiene un control en la creación de nuevos recursos
ReplicaSet y, tras ver cómo se crea un recurso, pide al programador que programe
los pods. El programador tiene su propio procedimiento y reglas para encontrar un
nodo adecuado para hospedar los pods. El programador informa al kubelet del nodo
y, a continuación, el kubelet recupera la definición del pod y crea los pods usando el
entorno de ejecución de contenedor instalado en los nodos. Por último, el pod crea
los contenedores dentro de su definición.
El proxy de Kube ayuda a mantener la lista de direcciones IP de información de pods
y servicios en nodos locales, así como a actualizar el firewall local y las reglas de
enrutamiento. Para hacer un resumen rápido de lo que hemos hablado hasta ahora,
empezamos con la arquitectura de Kubernetes y después pasamos a los primitivos,
seguidos de la arquitectura de AKS. Como tienes claros los conceptos, vamos a
continuar y a crear un clúster de AKS en la siguiente sección.
Implementar un clúster de AKS
AKS se puede aprovisionar mediante Azure Portal, la CLI (interfaz de línea de comandos)
de Azure, los cmdlets de Azure PowerShell, las plantillas de ARM, los SDK (kits de desarrollo
de software) para lenguajes compatibles e incluso las API de REST de ARM.
Azure Portal es la forma más sencilla de crear una instancia de AKS; sin embargo, para
habilitar DevOps, es mejor crear una instancia de AKS utilizando plantillas de ARM, la CLI
o PowerShell.
Crear un clúster de AKS
Vamos a crear un grupo de recursos para implementar nuestro clúster de AKS. En la CLI de
Azure, utiliza el comando az group create:
az group create -n AzureForArchitects -l southeastasia
Aquí, -n indica el nombre del grupo de recursos y -l indica la ubicación. Si la solicitud se ha
realizado correctamente, verás una respuesta similar a esta:

Ahora que ya tenemos el grupo de recursos listo, continuaremos y crearemos el clúster
de AKS con el comando az aks create. El siguiente comando creará un clúster denominado
AzureForArchitects-AKS en el grupo de recursos AzureForArchitects con un recuento
de nodos de 2. El parámetro –generate-ssh-keys permitirá la creación de pares de claves
RSA (Rivest–Shamir–Adleman), un sistema de criptografía de claves pública:
az aks create –resource-group AzureForArchitects \
–name AzureForArchitects-AKS \
–node-count 2 \
–generate-ssh-keys
Si el comando se ha generado correctamente, podrás ver un resultado similar a este:
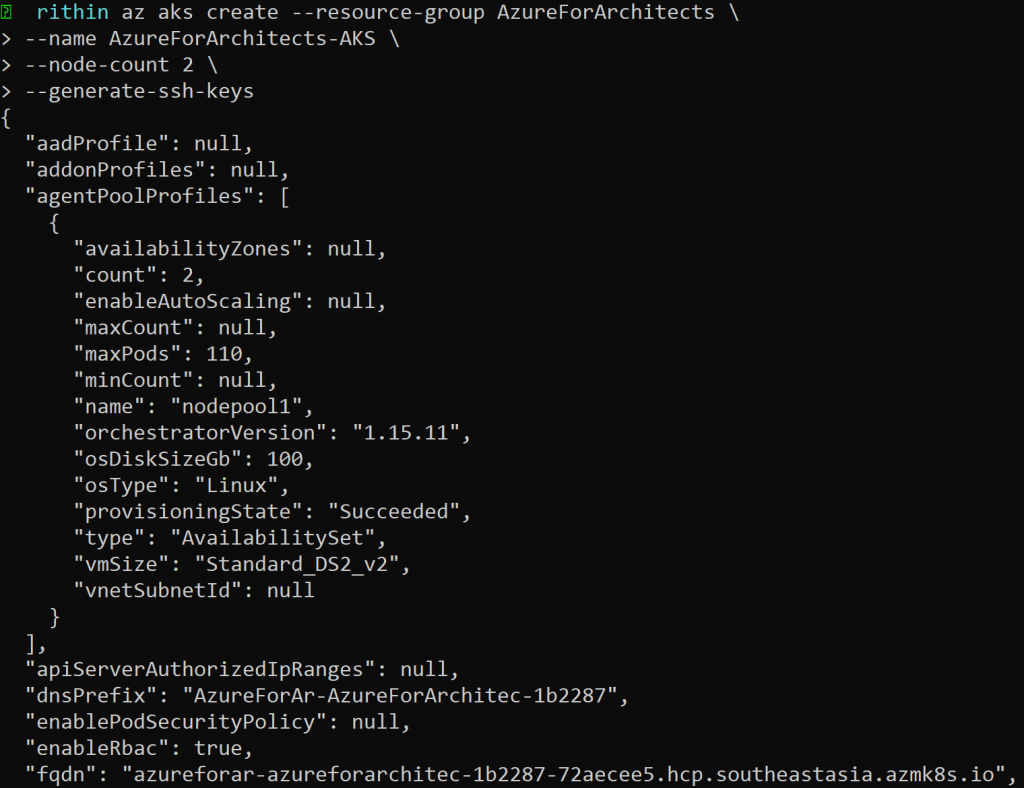
Si pasas por el clúster, verás un elemento de línea que dice «nodeResourceGroup»: «MC_
AzureForArchitects_AzureForArchitects-AKS_southeastasia». Al crear un clúster de AKS,
se crea automáticamente un segundo recurso para almacenar los recursos del nodo.
Nuestro clúster está aprovisionado. Ahora tenemos que conectarnos al clúster e interactuar
con él. Para controlar el administrador de clústeres de Kubernetes, vamos a usar kubectl.
En la siguiente sección, echaremos un vistazo rápido a kubectl.
Kubectl
Kubectl es el componente principal a través del cual los desarrolladores y consultores de
infraestructura pueden interactuar con AKS. Kubectl ayuda a crear una solicitud de REST
que contiene el cuerpo y el encabezado HTTP y la envía al servidor de API. El encabezado
contiene los detalles de autenticación, como una combinación de token o nombre de
usuario/contraseña. El cuerpo contiene la carga real en formato JSON.
El comando kubectl proporciona información detallada del registro cuando se utiliza junto
con el modificador detallado. El modificador toma una entrada entera que puede variar de
0 a 9, que se puede ver en los registros de detalles.
Conectarse al clúster
Para conectarnos al clúster localmente, necesitamos instalar kubectl. Azure Cloud Shell ya
tiene kubectl instalado. Si quieres conectarte localmente, utiliza az aks install-cli para
instalar kubectl.
Para configurar kubectl para conectarnos a nuestro clúster de Kubernetes, tenemos que
descargar las credenciales y configurar la CLI con ellas. Esto se puede hacer usando el
comando az aks get-credentials. Utiliza el comando como se muestra a continuación:
az aks get-credentials \
–resource-group AzureForArchitects \
–name AzureForArchitects-AKS
Ahora, tenemos que verificar si estamos conectados al clúster. Como hemos mencionado
anteriormente, usaremos kubectl para comunicarnos con el clúster y kubectl get nodes
mostrará una lista de nodos del clúster. Durante la creación, hemos establecido el
recuento de nodos en 2, por lo que el resultado debe tener dos nodos. Además, tenemos
que asegurarnos de que el estado del nodo es Ready. El resultado debe ser algo similar a la
Figura 14.11:

Puesto que nuestro nodo está en el estado Ready, vamos a continuar y a crear un pod.
Hay dos maneras de crear recursos en Kubernetes. Son los siguientes:
- Imperativo: en este método, usamos los comandos kubectl run y kubectl expose
para crear los recursos. - Declarativo: describimos el estado del recurso a través de JSON o un archivo YAML.
Mientras hablamos de los primitivos de Kubernetes, viste muchos archivos YAML para
cada uno de los componentes principales. Pasaremos el archivo al comando kubectl
apply para crear los recursos y se crearán los recursos declarados en el archivo.
Vamos a adoptar el enfoque imperativo en primer lugar para crear un pod con el nombre
webserver, ejecutando un contenedor de NGINX con el puerto 80 expuesto:
kubectl run webserver –restart=Never –image nginx –port 80
Una vez finalizado correctamente el comando, la CLI te permitirá conocer el estado:

Ahora que hemos probado el método imperativo, sigamos el método declarativo. Puedes
utilizar la estructura del archivo YAML que hemos comentado en la subsección Pod de la
sección Primitivos de Kubernetes y modificarlo según tus requisitos.
Vamos a utilizar la imagen de NGINX y el pod se denominará webserver-2.
Puedes utilizar cualquier editor de texto y crear el archivo. El archivo final tendrá un
aspecto similar a este:

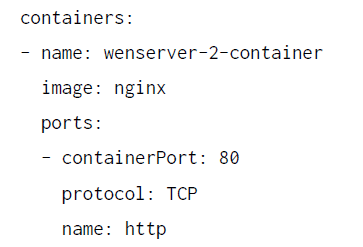
En el comando kubectl apply, pasaremos el nombre de archivo al parámetro -f, como se
muestra en la Figura 14.13, y puedes ver que se ha creado el pod:

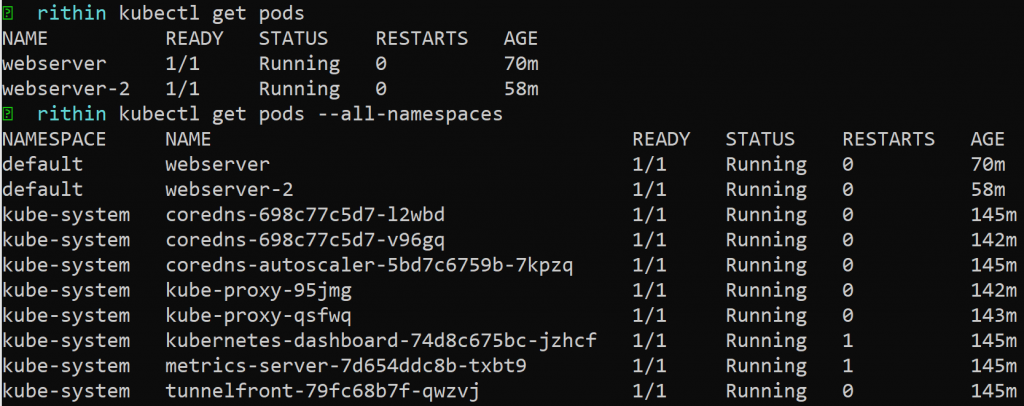
Puesto que hemos creado los pods, podemos usar el comando kubectl get pods para
enumerar todos los pods. Kubernetes utiliza el concepto de espacios de nombres para
el aislamiento lógico de los recursos. De forma predeterminada, todos los comandos apuntan
al espacio de nombres default. Si deseas realizar una acción en un espacio de nombres
específico, puedes pasar el nombre del espacio de nombres a través del parámetro -n. En la
Figura 14.14, puedes ver que kubectl get pods devuelve los pods que creamos en el ejemplo
anterior, que residen en el espacio de nombres predeterminado. Además, cuando usamos
–all-namespaces, el resultado devuelve pods en todos los espacios de nombres:
Ahora vamos a crear una implementación sencilla que ejecute NGINX y con un equilibrador
de carga que lo expone a Internet. El archivo YAML tendrá el siguiente aspecto:
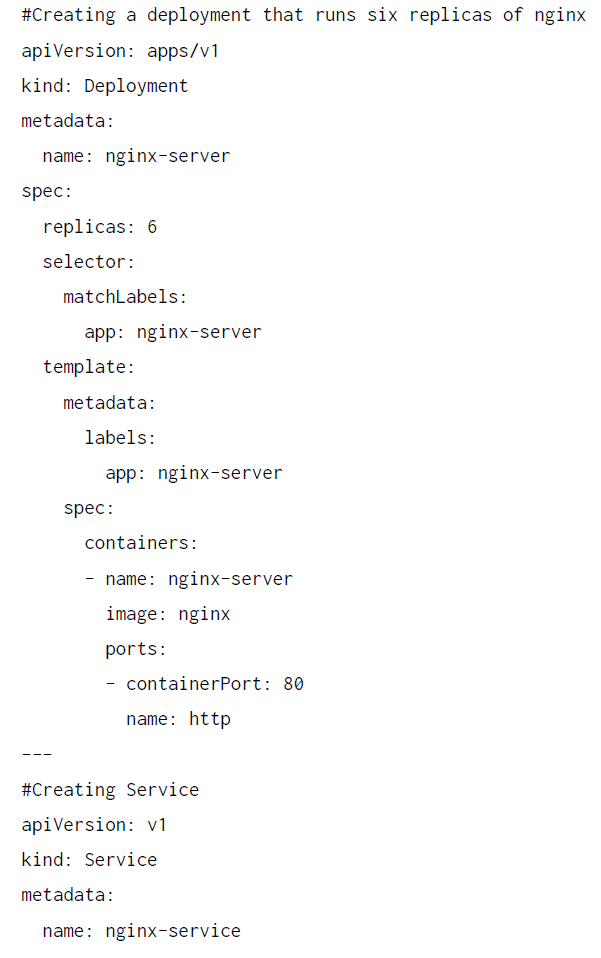

Usaremos el comando kubectl apply y pasaremos el archivo YAML al parámetro -f.
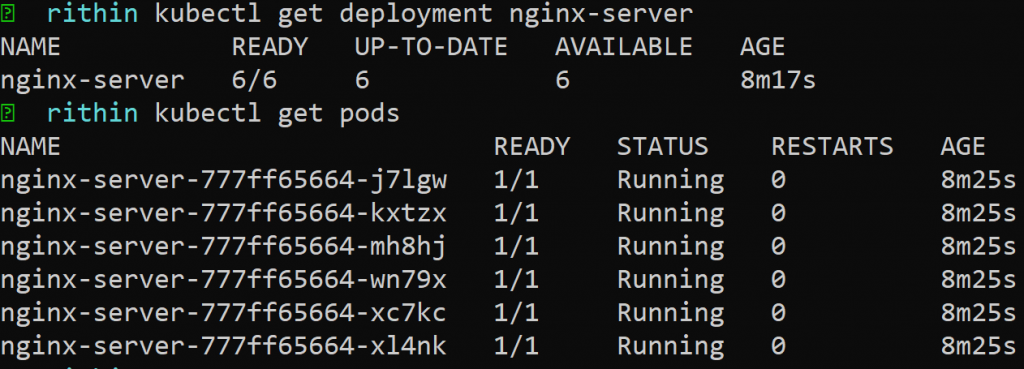
Tras hacerlo correctamente, se crearán los tres servicios y, si ejecutas el comando kubectl
get deployment nginx-server, verás seis réplicas ejecutándose, como se muestra en la
Figura 14.15, para que el servicio sea de alta disponibilidad:
Puesto que nuestra implementación está aprovisionada, tenemos que comprobar cuál es la
IP pública del equilibrador de carga que hemos creado. Podemos usar el comando kubectl
get service nginx-lb –watch. Cuando el equilibrador de carga se está inicializando,
EXTERNAL-IP se mostrará como , el parámetro –wait permitirá que el comando
se ejecute en primer plano y, cuando se asigne la IP pública, podremos ver una nueva línea,
como se muestra aquí:

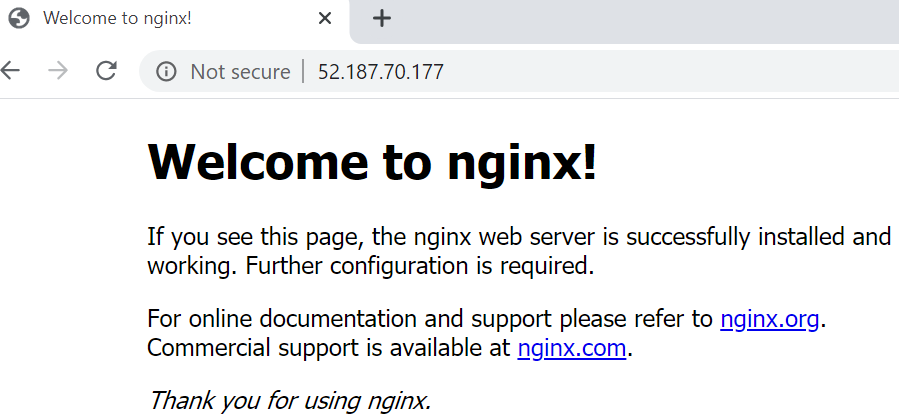
Ahora que tenemos la IP pública, podemos ir al navegador y deberíamos ver la página de
destino de NGINX, como se muestra en la Figura 14.17:
Del mismo modo, puedes utilizar los archivos YAML que hemos comentado en la sección
Primitivos de Kubernetes para crear diferentes tipos de recursos.
Hay una gran cantidad de comandos, como logs, describe, exec y delete, que los
administradores necesitan usar con el comando kubectl. El objetivo de esta sección era
que pudieras crear un clúster de AKS, conectarte al clúster e implementar una aplicación
web sencilla.
En la siguiente sección hablaremos de las redes de AKS.
Redes de AKS
Las redes son un componente fundamental dentro de un clúster de Kubernetes. Los
componentes maestros deben ser capaces de llegar a los nodos esbirro y los pods que se
ejecutan sobre ellos, mientras que los nodos de trabajo deben ser capaces de comunicarse
entre sí, así como con los componentes maestros.
Puede parecer una sorpresa que los componentes principales de Kubernetes no administren
la pila de red. Es el trabajo del entorno de ejecución de contenedor en los nodos.
Kubernetes ha prescrito tres principios importantes que debe cumplir cualquier entorno de
ejecución de contenedor. Son los siguientes:
- Los pods deben ser capaces de comunicarse con otros pods sin ninguna transformación
en sus direcciones de origen o destino, algo que se realiza mediante la traducción
de direcciones de red (NAT). - Los agentes como los kubelets deben poder comunicarse con los pods directamente
en los nodos. - Los pods que se hospedan directamente en la red del host deben poder comunicarse
con todos los pods del clúster.
Cada pod obtiene una dirección IP única dentro del clúster de Kubernetes, junto con
una pila de red completa, similar a las máquinas virtuales. Todos están conectados a la
red de puente local creada por el componente Container Networking Interface (CNI).
El componente CNI también crea la pila de red del pod. A continuación, la red de puente
habla con la red del host y se convierte en el conducto para el flujo del tráfico desde los
pods a la red y viceversa.
CNI es un estándar administrado y mantenido por la Cloud Native Computing Foundation
(CNCF), y hay muchos proveedores que proporcionan su propia implementación de la
interfaz. Docker es uno de estos proveedores. Hay otros, como rkt (que se lee como
«rocket»), weave, calico y muchos más. Cada uno de ellos tiene sus propias capacidades
y decide de forma independiente las capacidades de red, a la vez que garantiza que
se sigan completamente los principios principales de las redes de Kubernetes.
AKS proporciona dos modelos de red distintos:
- Kubenet
- Azure CNI
Kubenet
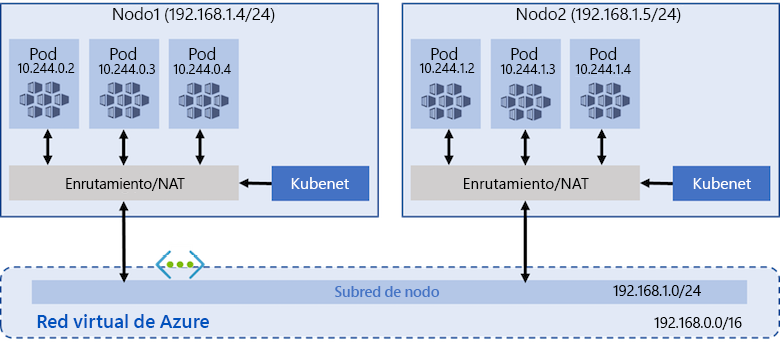
Kubenet es el marco de red predeterminado en AKS. En Kubenet, cada nodo obtiene
una dirección IP de la subred de la red virtual con la que están conectados. Los pods no
obtienen direcciones IP de la subred. En su lugar, se utiliza un esquema de direcciones
independiente para proporcionar direcciones IP a los pods y los servicios de Kubernetes.
Al crear una instancia de AKS, es importante establecer el intervalo de direcciones IP para
pods y servicios. Dado que los pods no están en la misma red que los nodos, las solicitudes
de pods y a pods siempre se traducen/enrutan para reemplazar la IP del pod de origen por
la dirección IP del nodo y viceversa.
En el enrutamiento definido por el usuario, Azure puede admitir hasta 400 rutas y no
puedes tener un clúster de más de 400 nodos. En la Figura 14.18 se muestra cómo el nodo
de AKS recibe una dirección IP de la red virtual, pero no los pods creados en el nodo:
De forma predeterminada, este Kubenet está configurado con 110 pods por nodo. Esto
significa que, de forma predeterminada, puede haber un máximo de 110 * 400 pods en
un clúster de Kubernetes. El número máximo de pods por nodo es de 250.
Este esquema debe utilizarse cuando la disponibilidad de direcciones IP y el enrutamiento
definido por el usuario no sean una restricción.
En la CLI de Azure, puedes ejecutar el siguiente comando para crear una instancia de AKS
utilizando esta pila de red:
az aks create \
–resource-group myResourceGroup \
–name myAKSCluster \
–node-count 3 \
–network-plugin kubenet \
–service-cidr 10.0.0.0/16 \
–dns-service-ip 10.0.0.10 \
–pod-cidr 10.244.0.0/16 \
–docker-bridge-address 172.17.0.1/16 \
–vnet-subnet-id $SUBNET_ID \
–service-principal \
–client-secret
Observa cómo se proporcionan explícitamente todas las direcciones IP para los recursos
de servicio, pods, nodos y puentes de Docker. Se trata de intervalos de direcciones IP no
solapados. Observa también que Kubenet se utiliza como un complemento de red.
Azure CNI (redes avanzadas)
Con Azure CNI, cada nodo y pod obtienen directamente una dirección IP asignada desde
la subred de red. Esto significa que puede haber tantos pods como direcciones IP únicas
disponibles en una subred. Esto hace que la planificación del intervalo de direcciones IP
sea mucho más importante en esta estrategia de redes.
Es importante tener en cuenta que el hosting de Windows solo es posible mediante la pila
de red de Azure CNI. Además, algunos de los componentes de AKS, como los nodos virtuales
y los kubelets virtuales, también dependen de la pila de Azure CNI. Es necesario reservar
direcciones IP por adelantado, en función del número de pods que se crearán. Siempre debe
haber direcciones IP adicionales disponibles en la subred para evitar el agotamiento de las
direcciones IP o la necesidad de reconstruir el clúster para una subred más grande debido
a la demanda de la aplicación.
De forma predeterminada, esta pila de red está configurada para 30 pods por nodo y se
puede configurar con 250 pods como el número máximo de pods por nodo.
A continuación, se muestra el comando para crear una instancia de AKS utilizando esta
pila de red:
az aks create \
–resource-group myResourceGroup \
–name myAKSCluster \
–network-plugin azure \
–vnet-subnet-id \
–docker-bridge-address 172.17.0.1/16 \
–dns-service-ip 10.2.0.10 \
–service-cidr 10.2.0.0/24 \
–generate-ssh-keys
Observa cómo se proporcionan explícitamente todas las direcciones IP para los recursos
de servicio, pods, nodos y puentes de Docker. Se trata de intervalos de direcciones IP no
solapados. Observa también que Azure se utiliza como un complemento de red.
Hasta ahora, has aprendido a implementar una solución y administrar las redes de un
clúster de AKS. La seguridad es otro factor importante que debe abordarse. En la siguiente
sección, nos centraremos en las opciones de acceso e identidad de AKS.
Acceso e identidad de AKS
Los clústeres de Kubernetes se pueden proteger de varias maneras.
La cuenta de servicio es uno de los tipos de usuario principales de Kubernetes. La API de
Kubernetes administra la cuenta de servicio. Los pods autorizados pueden comunicarse con
el servidor de API utilizando las credenciales de las cuentas de servicio, que se almacenan
como secretos de Kubernetes. Kubernetes no tiene ningún almacén de datos ni proveedor
de identidades propios. Delega la responsabilidad de la autenticación al software externo.
Proporciona un complemento de autenticación que comprueba las credenciales dadas y
las asigna a los grupos disponibles. Si la autenticación se realiza correctamente, la solicitud
pasa a otro conjunto de complementos de autorización para comprobar los niveles de
permiso del usuario en el clúster, así como los recursos del espacio de nombres.
Para Azure, la mejor integración de seguridad sería utilizar Azure AD. Con Azure AD también
puedes aportar tus identidades on-premises a AKS para proporcionar una administración
centralizada de las cuentas y la seguridad. El flujo de trabajo básico de la integración de
Azure AD se muestra en la Figura 14.19:
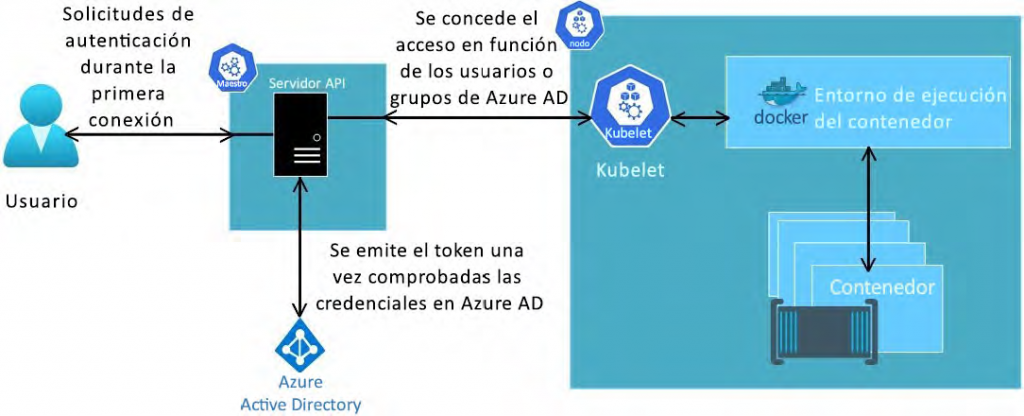
A los usuarios o grupos se les puede conceder acceso a los recursos dentro de un espacio
de nombres o a través de un clúster. En la sección anterior, utilizamos el comando az aks
get-credential para obtener las credenciales y el contexto de configuración de kubectl.
Cuando el usuario intenta interactuar con kubectl, se le pide que inicie sesión con sus
credenciales de Azure AD. Azure AD valida las credenciales y se emite un token para el
usuario. En función del nivel de acceso que tenga, puede acceder a los recursos del clúster
o el espacio de nombres.
Además, puedes utilizar el control de acceso basado en roles (RBAC) de Azure para limitar
el acceso a los recursos del grupo de recursos.
En la siguiente sección analizaremos el kubelet virtual, que es una de las formas más rápidas
de escalar un clúster.
Kubelet virtual
El kubelet virtual está actualmente en versión preview y está administrado por la
organización CNCF. Se trata de un enfoque muy innovador que AKS utiliza con fines
de escalabilidad. El kubelet virtual se implementa en el clúster de Kubernetes como
un pod. El contenedor que se ejecuta dentro del pod utiliza el SDK de Kubernetes para
crear un nuevo recurso de nodo y se representa a sí mismo para todo el clúster como
nodo. Los componentes del clúster, incluidos el servidor de API, el programador y los
controladores, lo consideran y lo tratan como un nodo y programan pods en él.
Sin embargo, cuando se programa un pod en este nodo que se hace pasar por un nodo,
se comunica con sus componentes de back-end, conocidos como proveedores, para crear,
eliminar y actualizar los pods. Uno de los principales proveedores de Azure es Azure
Container Instances. Azure Batch también se puede utilizar como proveedor. Esto significa
que los contenedores se crean realmente en Container Instances o Azure Batch en lugar
de en el propio clúster; sin embargo, los administra el clúster. La arquitectura del kubelet
virtual se muestra en la Figura 14.20:
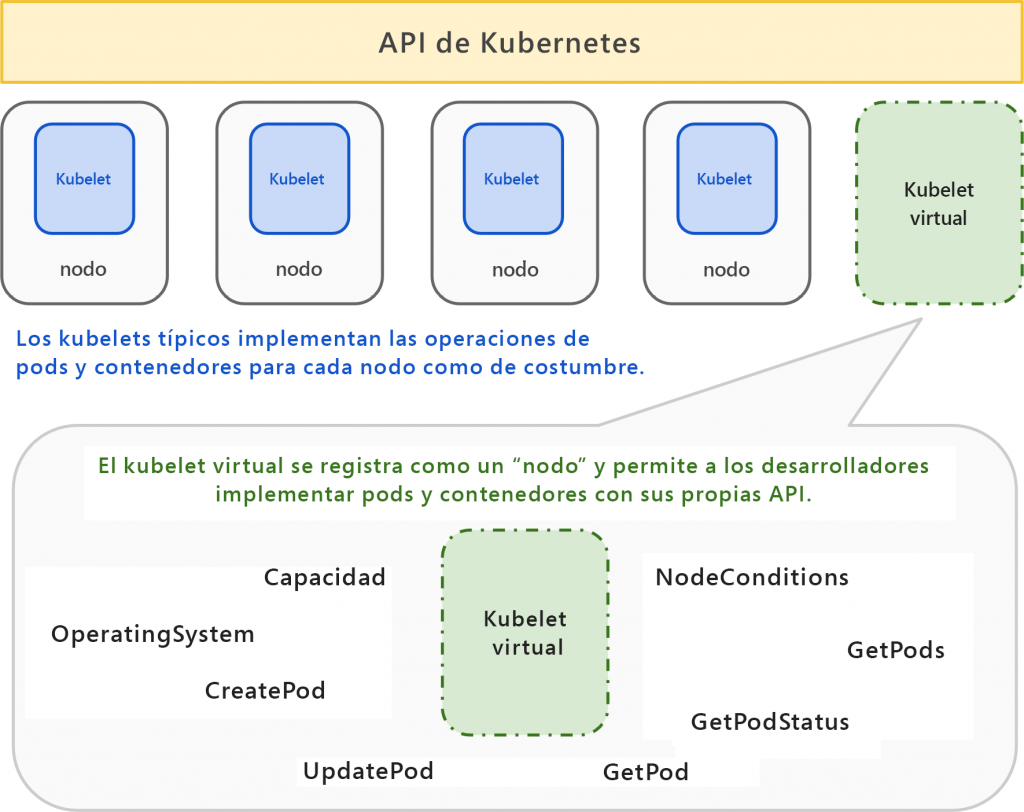
Observa que el kubelet virtual está representado como un nodo dentro del clúster y puede
ayudar a alojar y administrar pods, como lo haría un kubelet normal. Sin embargo, el kubelet
virtual tiene una limitación; esto es lo que vamos a tratar en la siguiente sección.
Nodos virtuales
Una de las limitaciones del kubelet virtual es que los pods implementados en proveedores
de kubelet virtual están aislados y no se comunican con otros pods del clúster. Si es
necesario que los pods de estos proveedores se comuniquen con otros pods y nodos del
clúster y viceversa, se deben crear nodos virtuales. Los nodos virtuales se crean en una
subred diferente en la misma red virtual que hospeda los nodos del clúster de Kubernetes,
lo que puede permitir la comunicación entre pods. En el momento de redactar este
documento, solo se admite el sistema operativo Linux para trabajar con nodos virtuales.
Los nodos virtuales dan una percepción de un nodo; sin embargo, el nodo no existe.
Cualquier cosa programada en un nodo de este tipo se crea realmente en Azure Container
Instances. Los nodos virtuales se basan en el kubelet virtual, pero tienen la funcionalidad
adicional de comunicación fluida entre el clúster y Azure Container Instances.
Al implementar pods en nodos virtuales, la definición de pod debe contener un selector
de nodos adecuado para hacer referencia a nodos virtuales y también tolerancias,
como se muestra en el siguiente fragmento de código:

Aquí, el selector de nodos está utilizando la propiedad type para hacer referencia al
kubelet virtual y la propiedad tolerations para informar a Kubernetes de que los nodos
contaminados, virtual-kubelet.io/provider, deben permitir la implementación de estos
pods en ellos.
Resumen
Kubernetes es el orquestador de contenedores más utilizado y funciona con diferentes
entornos de ejecución de contenedor y red. En este capítulo, has aprendido los conceptos
básicos de Kubernetes, su arquitectura y algunos de los componentes de la infraestructura
importantes, como etcd, el servidor de API, los administradores de controladores y el
programador, junto con su finalidad. Además, hemos visto recursos importantes que
se pueden implementar para administrar aplicaciones, como pods, controladores de
replicación, ReplicaSets, implementaciones y servicios.
AKS proporciona un par de pilas de red diferentes: Azure CNI y Kubenet. Proporcionan
diferentes estrategias para asignar direcciones IP a los pods. Mientras que Azure CNI
proporciona direcciones IP a los pods desde la subred subyacente, Kubenet solo utiliza
direcciones IP virtuales.
También hemos abordado algunas de las características que proporciona exclusivamente
Azure, como los nodos virtuales, y los conceptos relacionados con el kubelet virtual. En el
siguiente capítulo, conoceremos el aprovisionamiento y la configuración de recursos con
plantillas de ARM.
Samsung 2253BW
thanks