



Las plantillas de Azure Resource Manager (ARM) son el mecanismo de preferencia para el aprovisionamiento de recursos y la configuración de estos en Azure.
Las plantillas de ARM ayudan a implementar un paradigma relativamente nuevo conocido como infraestructura como código (IaC). Las plantillas de ARM convierten la infraestructura y su configuración en código, lo cual presenta diversas ventajas. IaC aporta un alto nivel de coherencia y previsibilidad a las implementaciones en diversos entornos. También garantiza que los entornos se pueden probar antes de pasar a producción y, por último, proporciona un alto nivel de confianza en el proceso de implementación, el mantenimiento y la gestión.
En este capítulo, abordaremos los siguientes temas:
- Plantillas de ARM
- Implementar grupos de recursos con plantillas de ARM
- Implementar recursos en suscripciones y grupos de recursos diversos
- Implementar implementaciones entre suscripciones y grupos de recursos mediante
plantillas vinculadas - Crear plantillas de ARM para soluciones PaaS, datos e IaaS
Plantillas de ARM
Una ventaja destacada de IaC es que puede controlarse por versión. También se puede
reutilizar en distintos entornos, lo que proporciona un alto grado de coherencia
y previsibilidad en las implementaciones y garantiza que el impacto y el resultado de
la implementación de una plantilla de ARM sean los mismos independientemente del
número de veces que se implemente la plantilla. Esta característica se conoce como
idempotencia.
Las plantillas de ARM nacieron con la introducción de la especificación ARM y, desde
entonces, han ido incorporando nuevas características y creciendo en madurez.
Es importante comprender que, normalmente, hay un desfase funcional —que oscila
entre algunas semanas y un par de meses— entre la configuración del recurso real
y la disponibilidad de la configuración en las plantillas de ARM.
Cada recurso tiene su propia configuración. Esta configuración puede verse afectada
por muchos factores, por ejemplo, el uso de Azure PowerShell, la CLI de Azure, los SDK
de Azure, las API de REST y las plantillas de ARM.
Cada una de estas técnicas tiene su propio desarrollo y ciclo de vida, que es diferente
del desarrollo del recurso real. Tratemos de entender esto con la ayuda de un ejemplo.
El recurso Azure Databricks tiene su propio ciclo de vida de desarrollo y cadencia.
Los clientes de este recurso tienen a su vez su propio ciclo de vida de desarrollo, que es
diferente del desarrollo del recurso real. Si la primera versión de Databricks se lanza el
31 de diciembre, podría suceder que los cmdlets de Azure PowerShell para este recurso
no estuvieran disponibles en la misma fecha y que no se lanzaran hasta el 31 de enero del
año siguiente; de forma similar, la disponibilidad de estas características en la API de REST
y las plantillas de ARM podría demorarse hasta el 15 de enero.
Las plantillas de ARM son documentos basados en JSON que, cuando se ejecutan, invocan la
API de REST en el plano de administración de Azure y le envían todo el documento. La API
de REST tiene su propio ciclo de vida de desarrollo, al igual que el esquema JSON para el
recurso, que también tiene el suyo propio.
Esto significa que el desarrollo de una característica dentro de un recurso tiene que
realizarse en al menos tres componentes diferentes para poder usarlos en las plantillas
de ARM. Son los siguientes:
- El propio recurso
- La API de REST del recurso
- El esquema de recursos de la plantilla de ARM
Cada recurso incluido en la plantilla de ARM tiene la propiedad apiVersion. Esta
propiedad ayuda a decidir la versión de la API de REST que se debe usar para aprovisionar
e implementar el recurso. En la Figura 15.1 se muestra el flujo de las solicitudes desde la
plantilla de ARM a las API de recursos que son responsables de la creación, la actualización
y la eliminación de los recursos:

La configuración de un recurso, como una cuenta de almacenamiento en una plantilla
de ARM, tiene el aspecto siguiente:
{
«type»: «Microsoft.Storage/storageAccounts»,
«apiVersion»: «2019-04-01»,
«name»: «[variables(‘storage2’)]»,
«location»: «[resourceGroup().location]»,
«kind»: «Storage»,
«sku»: {
«name»: «Standard_LRS»
}
}
En el código anterior, la disponibilidad de este esquema para definir sku depende del desarrollo
del esquema de la plantilla de ARM. La disponibilidad de la API de REST y su número de
versión está determinada por la propiedad apiVersion, que es 2019-04-01. El recurso real está
determinado por la propiedad type, que consta de las dos partes indicadas a continuación:
- Espacio de nombres del proveedor de recursos: en Azure, los recursos se hospedan
en espacios de nombres y los recursos relacionados se hospedan en el mismo espacio
de nombres. - Tipo de recurso: para hacer referencia a los recursos se utiliza el nombre de tipo de
recurso.
En este caso, el recurso se identifica por el nombre del proveedor y el tipo de recurso, y es
Microsoft. Storage/storageaccounts.
Anteriormente, las plantillas de ARM esperaban a que los grupos de recursos estuvieran
disponibles para poder implementarse. Otra limitación era que solo podían implementarse
en un único grupo de recursos de una sola suscripción.
Esto significaba que, hasta hace poco, una plantilla de ARM podía implementar todos los
recursos en un único grupo de recursos. Las plantillas de ARM de Azure ahora tienen
funcionalidad añadida de implementar recursos en varios grupos de recursos dentro de una
misma suscripción o en varias suscripciones simultáneamente. Es posible crear grupos de
recursos como parte de las plantillas de ARM, lo que significa que es posible implementar
recursos en varias regiones en diferentes grupos de recursos.
Pero ¿por qué querríamos crear grupos de recursos desde las plantillas de ARM? ¿Y por
qué necesitaríamos tener implementaciones entre suscripciones y grupos de recursos
simultáneamente?
Para apreciar realmente el valor de la creación de un grupo de recursos y las implementaciones
entre suscripciones, es fundamental comprender cómo se realizaban las implementaciones
antes de que estas características estuvieran disponibles.
Uno de los requisitos previos de la implementación de una plantilla de ARM es la creación de un
grupo de recursos. Los grupos de recursos deben crearse antes de la implementación de una
plantilla. Los programadores usan PowerShell, la CLI de Azure o la API de REST para crear grupos
de recursos y, a continuación, inician la implementación de las plantillas de ARM. Esto significa
que cualquier implementación completa consta de varios pasos. El primer paso es aprovisionar
el grupo de recursos y, el siguiente, la implementación de la plantilla de ARM en este grupo de
recursos recién creado. Estos pasos se pueden ejecutar mediante un único script de PowerShell
o mediante pasos individuales especificados en la línea de comandos de PowerShell. El script de
PowerShell debe completarse con respecto al código relacionado con el control de excepciones,
ocuparse de los casos perimetrales y garantizar que no haya errores en él antes de que se pueda
decir que está listo para la empresa. Cabe señalar que los grupos de recursos se pueden eliminar
de Azure; en tal caso, la siguiente vez que se ejecute el script, es posible que se espere que
dichos grupos estén disponibles. Se producirá un error, porque el script supone que el grupo de
recursos existe. En definitiva, la implementación de la plantilla de ARM en un grupo de recursos
debe ser un proceso de un solo paso, y no un proceso de varios pasos.
Compara esto con la capacidad de crear grupos de recursos y sus recursos constituyentes
juntos dentro de las mismas plantillas de ARM. Cada vez que implementes la plantilla, esta
se asegurará de que los grupos de recursos se crean, en caso de no existir, y continuará
implementando los recursos en los grupos una vez creados.
Veamos también cómo estas nuevas características pueden ayudar a eliminar algunas de las
limitaciones técnicas relacionadas con los sitios de recuperación ante desastres.
Antes de que existieran estas características, si tenías que implementar una solución
diseñada con la recuperación ante desastres en mente, disponías de dos implementaciones
independientes: una implementación para la región principal y otra para la región secundaria.
Por ejemplo, si estuvieras implementando una aplicación MVC ASP.NET mediante App Service,
tendrías que crear un servicio de aplicaciones y configurarlo para la región principal y,
a continuación, tendrías que llevar a cabo otra implementación con la misma plantilla en otra
región con un archivo parameters distinto. Al implementar otro conjunto de recursos en otra
región, como se ha mencionado anteriormente, los parámetros utilizados con la plantilla
deben ser diferentes para reflejar las diferencias entre los dos entornos. Los parámetros
incluirían cambios como una cadena de conexión SQL, direcciones IP y de dominio, y otros
elementos de configuración únicos de un entorno.
Con la disponibilidad de la implementación entre suscripciones y grupos de recursos,
es posible crear el sitio de recuperación ante desastres al mismo tiempo que el sitio
principal. Esto elimina la necesidad de realizar dos implementaciones y garantiza la
misma configuración se puede usar en varios sitios.
Implementar grupos de recursos con plantillas de ARM
En esta sección, vamos a crear e implementar una plantilla de ARM que creará un par de
grupos de recursos en una misma suscripción.
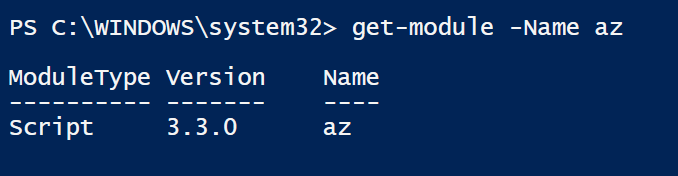
Para usar PowerShell para implementar plantillas que contengan grupos de recursos y
recursos entre suscripciones, es preciso usar la versión más reciente de PowerShell. En el
momento de redactar este documento, se ha usado la versión 3.3.0 del módulo de Azure:
Si el módulo de Azure más reciente no está instalado, se puede instalar mediante el
siguiente comando:
install-module -Name az -Force
Es el momento de crear una plantilla de ARM que creará varios grupos de recursos en una
misma suscripción. El código de la plantilla de ARM es el siguiente:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentTemplate.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«resourceGroupInfo»: {
«type»: «array» },
«multiLocation»: {
«type»: «array»
}
},
«resources»: [
{
«type»: «Microsoft.Resources/resourceGroups»,
«location»: «[parameters(‘multiLocation’)[copyIndex()]]»,
«name»: «[parameters(‘resourceGroupInfo’)[copyIndex()]]»,
«apiVersion»: «2019-10-01»,
«copy»: {
«name»: «allResourceGroups»,
«count»: «[length(parameters(‘resourceGroupInfo’))]»
},
«properties»: {}
}
],
«outputs»: {}
}
La primera sección del código corresponde a los parámetros que esperan las plantillas de
ARM. Se trata de parámetros obligatorios; cualquier persona que implemente estas plantillas
debe especificar valores para ellos. Para ambos parámetros es preciso especificar valores de
matriz.
La segunda sección principal corresponde a la matriz JSON resources, que puede
incluir varios recursos. En este ejemplo, estamos creando grupos de recursos y esto
es precisamente lo que se indica en la sección resources. Los grupos de recursos se
aprovisionan en un bucle debido al uso del elemento copy. El elemento copy garantiza
que el recurso se ejecuta el número especificado de veces y crea un nuevo recurso en
cada iteración. Si enviamos dos valores para el parámetro de matriz resourceGroupInfo,
la longitud de la matriz sería dos y el elemento copy garantizaría que el recurso
resourceGroup se ejecuta dos veces.
Todos los nombres de recursos dentro de una plantilla deben ser únicos para un tipo
de recurso. La función copyIndex se utiliza para asignar el número de iteración actual al
nombre general del recurso y hacerlo único. Además, como deseamos que los grupos de
recursos se creen en diferentes regiones, utilizamos nombres de regiones distintos y los
enviamos como parámetros. La asignación de un nombre y una ubicación a cada grupo de
recursos se realiza mediante la función copyIndex.
El código para el archivo parameters se muestra a continuación. Este código es bastante
sencillo y proporciona valores de matriz a los dos parámetros esperados por la plantilla
anterior. Los valores de este archivo deben cambiarse para todos los parámetros según
tu entorno:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentParameters.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«resourceGroupInfo»: {
«value»: [ «firstResourceGroup», «SeocndResourceGroup» ]
},
«multiLocation»: {
«value»: [
«West Europe»,
«East US»
]
}
}
}
Implementar plantillas de ARM
Para implementar esta plantilla con PowerShell, inicia sesión en Azure con credenciales
válidas mediante el siguiente comando:
Login-AzAccount
Las credenciales válidas pueden ser una cuenta de usuario o una entidad de
servicio. A continuación, usa un cmdlet New-AzDeployment recién publicado para
implementar la plantilla. El script de implementación está disponible en el archivo
multipleResourceGroups.ps1:
New-AzDeployment -Location «West Europe» -TemplateFile «c:\users\rites\
source\repos\CrossSubscription\CrossSubscription\multipleResourceGroups.
json» -TemplateParameterFile «c:\users\rites\source\repos\CrossSubscription\
CrossSubscription\multipleResourceGroups.parameters.json» -Verbose
Es importante comprender que el cmdlet New-AzResourceGroupDeployment no se
puede utilizar aquí porque el ámbito del cmdlet New-AzResourceGroupDeployment es un
grupo de recursos y espera que un grupo de recursos esté disponible como requisito
previo. Para implementar recursos en el nivel de suscripción, Azure había publicado
un nuevo cmdlet capaz de trabajar por encima del ámbito del grupo de recursos.
El nuevo cmdlet, new-AzDeployment, funciona en el nivel de suscripción. También es
posible tener una implementación en el nivel de grupo de administración. Los grupos
de administración tienen un nivel más alto que las suscripciones mediante el cmdlet
New-AzManagementGroupDeployment.
Implementación de plantillas mediante la CLI de Azure
La misma plantilla también se puede implementar mediante la CLI de Azure. Estos son los
pasos para implementarla mediante la CLI de Azure:
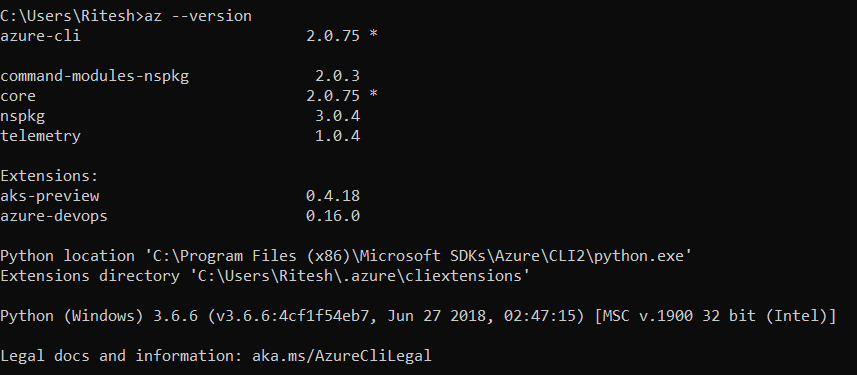
- Usa la versión más reciente de la CLI de Azure para crear grupos de recursos mediante
la plantilla de ARM. En el momento de redactar este documento, se usó la versión
2.0.75 para la implementación, como se muestra aquí:
- Utiliza el comando siguiente para iniciar sesión en Azure y selecciona la suscripción
correcta:
az login - Si el inicio de sesión tiene acceso a varias suscripciones, selecciona la suscripción
correspondiente mediante el comando siguiente:
az account set –subscription xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx - Ejecuta la implementación mediante el comando siguiente. El script de
implementación está disponible en el archivo multipleResourceGroupsCLI.txt:
C:\Users\Ritesh>az deployment create—location westus—template-file «C:\
users\rites\source\repos\CrossSubscription\CrossSubscription\azuredeploy.
json—parameters @»C:\users\rites\source\repos\CrossSubscription\
CrossSubscription\azuredeploy.parameters.json»—verbose
Una vez ejecutado el comando, los recursos definidos en la plantilla de ARM deben reflejarse
en Azure Portal.
Implementar recursos en suscripciones y grupos de
recursos diversos
En la última sección, se crearon grupos de recursos como parte de las plantillas
de ARM. Otra característica en Azure es el aprovisionamiento simultáneo de recursos
en varias suscripciones, desde una única implementación y mediante una sola plantilla
de ARM. En esta sección, proporcionaremos una nueva cuenta de almacenamiento
para dos suscripciones y grupos de recursos diferentes. La persona que está
implementando la plantilla de ARM debe seleccionar una de las suscripciones como
suscripción base, con la que debe iniciar la implementación y aprovisionar la cuenta
de almacenamiento en la suscripción actual y en otra suscripción. El requisito previo
para implementar esta plantilla es que la persona que la está implementando debe tener
acceso al menos a dos suscripciones, así como disponer de derechos de colaborador
en ambas. La lista de código se muestra a continuación y está disponible en el archivo
CrossSubscriptionStorageAccount.json, dentro del código que lo acompaña:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentTemplate.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«storagePrefix1»: {
«type»: «string»,
«defaultValue»: «st01»
…
«type»: «string»,
«defaultValue»: «rg01»
},
«remoteSub»: {
«type»: «string»,
«defaultValue»: «xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx»
}
…
}
}
],
«outputs»: {}
}
}
}
],
«outputs»: {}
}
Cabe señalar que los nombres de los grupos de recursos usados en el código deben
estar disponibles con anterioridad en las suscripciones correspondientes. El código
producirá un error si los grupos de recursos no están disponibles. Además, los
nombres de los grupos de recursos deben coincidir exactamente con los que figuran
en la plantilla de ARM.
A continuación, se muestra el código para implementar esta plantilla. En este caso,
hemos usado New-AzResourceGroupDeployment, porque el ámbito de implementación
es un grupo de recursos. El script de implementación está disponible en el archivo
CrossSubscriptionStorageAccount.ps1 dentro del paquete de código:
New-AzResourceGroupDeployment -TemplateFile «<< path to your CrossSubscriptionStorageAccount.json file >>» -ResourceGroupName «<>» -storagePrefix1 <> -storagePrefix2 <> -verbose
Una vez ejecutado el comando, los recursos definidos en la plantilla de ARM deben reflejarse
en Azure Portal.
Otro ejemplo de implementaciones entre suscripciones y grupos de recursos
En esta sección, vamos a crear dos cuentas de almacenamiento en dos suscripciones,
grupos de recursos y regiones diferentes a partir de una plantilla de ARM y una única
implementación. Utilizaremos el enfoque de plantillas anidadas junto con el elemento
copy para proporcionar distintos nombres y ubicaciones a estos grupos de recursos en
suscripciones diferentes.
Sin embargo, para poder ejecutar el siguiente conjunto de plantillas de ARM, antes, como
requisito previo, se debe aprovisionar una instancia de Azure Key Vault y agregar un secreto
a esta. El motivo es que los nombres de las cuentas de almacenamiento se recuperan de
Azure Key Vault y se transfieren como parámetros a las plantillas de ARM para aprovisionar
la cuenta de almacenamiento.
Para aprovisionar Azure Key Vault con Azure PowerShell, se puede ejecutar el conjunto de
comandos que figura a continuación. El código de los siguientes comandos está disponible
en el archivo CreateKeyVaultandSetSecret.ps1:
New-AzResourceGroup -Location <>
-Name <> -verbose
New-AzureRmKeyVault -Name <>
-ResourceGroupName <> -Location <>
-EnabledForDeployment -EnabledForTemplateDeployment -EnabledForDiskEncryption
-EnableSoftDelete -EnablePurgeProtection -Sku Standard -Verbose
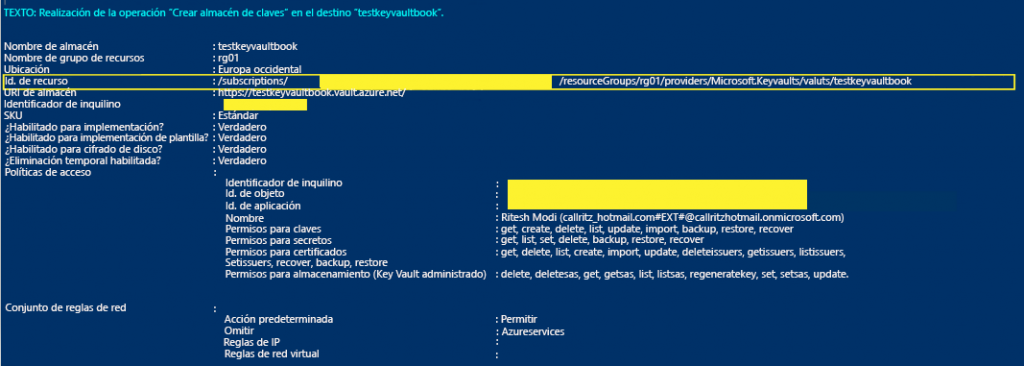
Observa que el valor de ResourceID debe tomarse del resultado del cmdlet New-AzKeyVault.
Este valor deberá reemplazarse en el archivo parameters. Consulta la Figura 15.4 para
obtener más información:
Ejecuta el comando siguiente para agregar un nuevo secreto a la instancia de Azure Key
Vault que acabas de crear:
Set-AzKeyVaultSecret -VaultName <> -Name
<> -SecretValue $(ConvertTo-SecureString
-String <> -AsPlainText -Force ) -Verbose
La lista de código está disponible en el archivo CrossSubscriptionNestedStorageAccount.
json, dentro del paquete de código:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentTemplate.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«hostingPlanNames»: {
«type»: «array»,
«minLength»: 1
},
…
«type»: «Microsoft.Resources/deployments»,
«name»: «deployment01»,
«apiVersion»: «2019-10-01»,
«subscriptionId»: «[parameters(‘subscriptions’)[copyIndex()]]»,
«resourceGroup»: «[parameters(‘resourceGroups’)[copyIndex()]]»,
«copy»: {
«count»: «[length(parameters(‘hostingPlanNames’))]»,
«name»: «mywebsites», «mode»: «Parallel»
},
…
«kind»: «Storage»,
«properties»: {
}
}
]
Este es el código para el archivo parameters. Está disponible en el archivo
CrossSubscriptionNestedStorageAccount.parameters.json:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentParameters.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«hostingPlanNames»: {
…
«storageKey»: {
«reference»: {
«keyVault»: { «id»: «<>» },
«secretName»: «<>»
}
}
}
}
Este es el código de PowerShell para implementar la plantilla anterior. El script de
implementación está disponible en el archivo CrossSubscriptionNestedStorageAccount.ps1:
New-AzResourceGroupDeployment -TemplateFile «c:\users\rites\source\repos\
CrossSubscription\CrossSubscription\CrossSubscriptionNestedStorageAccount.
json» -ResourceGroupName rg01 -TemplateParameterFile «c:\
users\rites\source\repos\CrossSubscription\CrossSubscription\
CrossSubscriptionNestedStorageAccount.parameters.json» -Verbose
Una vez ejecutado el comando, los recursos definidos en la plantilla de ARM deben reflejarse
en Azure Portal.
Realizar implementaciones entre suscripciones y grupos de
recursos mediante plantillas vinculadas
En el ejemplo anterior, usamos plantillas anidadas para la implementación en varias
suscripciones y grupos de recursos. En el siguiente ejemplo, implementaremos varios
planes de App Service en suscripciones y grupos de recursos distintos mediante
plantillas vinculadas. Las plantillas vinculadas se almacenan en Azure Blob Storage, que
se protege mediante políticas. Esto significa que solo el titular de la clave de la cuenta de
almacenamiento o de una firma de acceso compartido válida puede tener acceso a esta
plantilla. La clave de acceso se almacena en Azure Key Vault y se accede a ella desde
el archivo parameters, mediante las referencias del elemento storageKey. Debes cargar
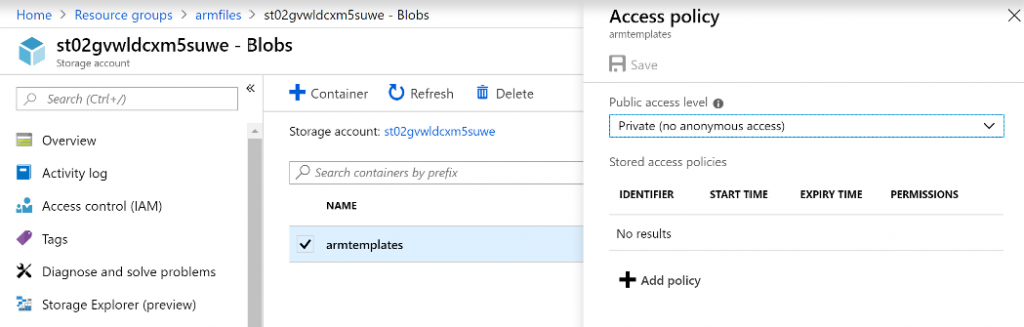
el archivo website.json en un contenedor en Azure Blob Storage. El archivo website.json
es una plantilla vinculada responsable de aprovisionar un plan de App Service y una instancia
de App Service. El archivo está protegido mediante la política Privado (sin acceso anónimo),
tal como se muestra en la Figura 15.5. Las políticas de acceso privado garantizan que el
acceso anónimo no está permitido. Para este ejemplo, hemos creado un contenedor llamado
armtemplates y le hemos asignado una política de acceso privado:
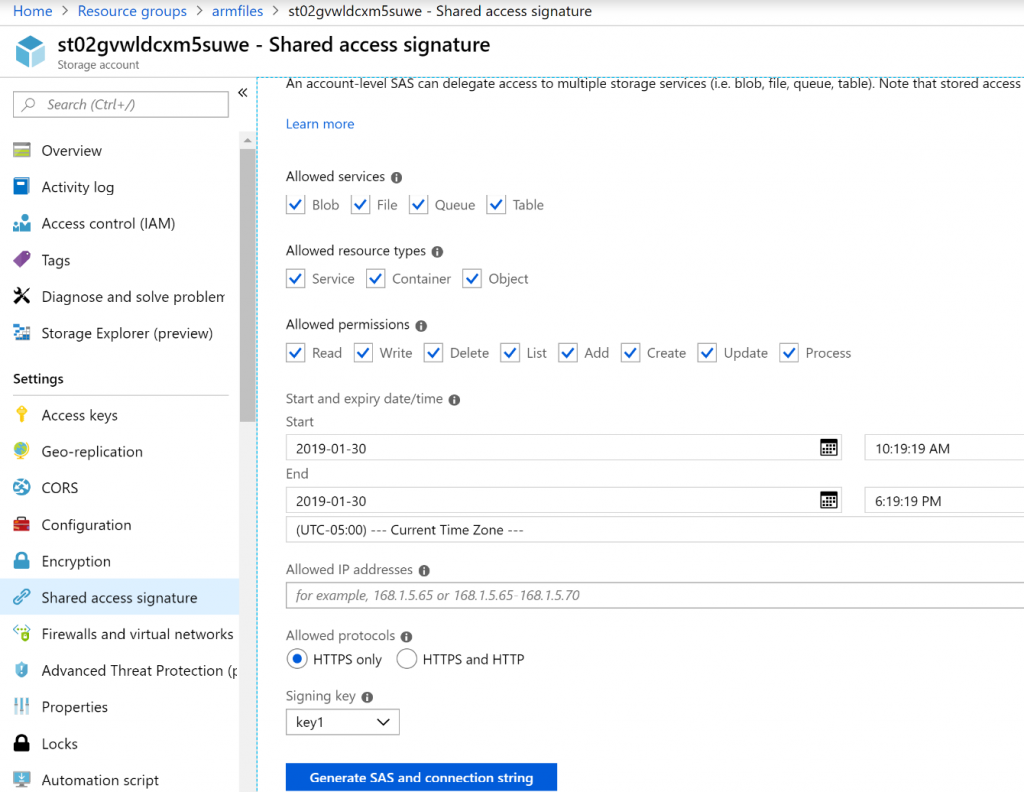
Solo se puede acceder a este archivo con las claves de Firma de acceso compartido (SAS).
Las claves SAS de una cuenta de almacenamiento se pueden generar desde Azure Portal,
mediante el elemento Firma de acceso compartido del menú de la izquierda que se
muestra en la Figura 15.6. Para generar el token SAS, debes hacer clic en el botón Generar
SAS y cadena de conexión. Cabe señalar que el token SAS se muestra una sola vez y no
se almacena en Azure. Por lo tanto, debes copiarlo y guardarlo en algún lugar para poder
cargarlo luego en Azure Key Vault. En la Figura 15.6 se muestra la generación del token SAS:
Usaremos la misma instancia de Key Vault que hemos creado en la sección anterior. Solo
tenemos que asegurarnos de que hay dos secretos disponibles en la instancia de Key Vault.
El primer secreto es StorageName y, el segundo, StorageKey. Los comandos para crear estos
secretos en la instancia de Key Vault son los siguientes:
Set-AzKeyVaultSecret -VaultName «testkeyvaultbook» -Name «storageName»
-SecretValue $(ConvertTo-SecureString -String «uniquename» -AsPlainText
-Force ) -Verbose
Set-AzKeyVaultSecret -VaultName «testkeyvaultbook» -Name «storageKey»
-SecretValue $(ConvertTo-SecureString -String «?sv=2020-03-28&ss=bfqt&srt=sc
o&sp=rwdlacup&se=2020-03-30T21:51:03Z&st=2020-03-30T14:51:03Z&spr=https&sig=
gTynGhj20er6pDl7Ab%2Bpc29WO3%2BJhvi%2BfF%2F6rHYWp4g%3D» -AsPlainText -Force
) -Verbose
Se recomienda que cambies el nombre de la instancia de Key Vault y el valor de la clave
secreta en función de tu cuenta de almacenamiento.
Una vez que te has asegurado de que la instancia de Key Vault contiene los secretos
necesarios, puedes usar el código de archivo de plantilla de ARM para implementar las
plantillas anidadas entre suscripciones y grupos de recursos.
El código de plantilla de ARM está disponible en el archivo
CrossSubscriptionLinkedStorageAccount.json y también se muestra a continuación.
Se recomienda que cambies el valor de la variable templateUrl en este archivo.
Es preciso actualizarla con una ubicación de archivo de Azure Blob Storage válida:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentTemplate.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«hostingPlanNames»: {
«type»: «array»,
«minLength»: 1
…
«type»: «Microsoft.Resources/deployments»,
«name»: «fsdfsdf»,
«apiVersion»: «2019-10-01»,
«subscriptionId»: «[parameters(‘subscriptions’)[copyIndex()]]»,
«resourceGroup»: «[parameters(‘resourceGroups’)[copyIndex()]]»,
«copy»: {
«count»: «[length(parameters(‘hostingPlanNames’))]»,
«name»: «mywebsites»,
«mode»: «Parallel»
…
]
}
El código para el archivo parameters se muestra a continuación. Se recomienda que cambies
los valores de los parámetros, incluidos el valor de resourceid de la instancia de Key Vault y
el nombre secreto. Los nombres de los servicios de aplicación deben ser únicos o la plantilla
no se implementará. El código del archivo parameters está disponible en el archivo de
código CrossSubscriptionLinkedStorageAccount.parameters.json:
{
«$schema»: «https://schema.management.azure.com/schemas/2015-01-01/
deploymentParameters.json#»,
«contentVersion»: «1.0.0.0»,
«parameters»: {
«hostingPlanNames»: {
«value»: [ «firstappservice», «secondappservice» ]
…
«storageKey»: {
«reference»: {
«keyVault»: { «id»: «/subscriptions/xxxxxxxx-xxxx-xxxx-xxxxxxxxxxxxxxxx/
resourceGroups/keyvaluedemo/providers/Microsoft.KeyVault/
vaults/forsqlvault1″ },
«secretName»: «storageKey»
}
}
}
}
Este es el comando para implementar la plantilla. El script de implementación está
disponible en el archivo CrossSubscriptionLinkedStorageAccount.ps1:
New-AzureRmResourceGroupDeployment -TemplateFile «c:\users\
rites\source\repos\CrossSubscription\CrossSubscription\
CrossSubscriptionLinkedStorageAccount.json» -ResourceGroupName <> -TemplateParameterFile
«c:\users\rites\source\repos\CrossSubscription\CrossSubscription\
CrossSubscriptionLinkedStorageAccount.parameters.json» -Verbose
Una vez ejecutado el comando, los recursos definidos en la plantilla de ARM deben reflejarse
en Azure Portal.
Ahora que ya sabes cómo aprovisionar recursos entre grupos de recursos y suscripciones,
vamos a ver algunas de las soluciones que se pueden crear utilizando plantillas de ARM.
Soluciones de máquinas virtuales que utilizan plantillas de ARM
Los recursos y soluciones de infraestructura como servicio (IaaS) se pueden implementar
y configurar mediante plantillas de ARM. Los principales recursos relacionados con IaaS son
los recursos de máquinas virtuales.
La creación de un recurso de máquina virtual depende de otros recursos en Azure. Algunos
de los recursos necesarios para crear una máquina virtual son:
- Una cuenta de almacenamiento o un disco administrado para hospedar el sistema
operativo y el disco de datos - Una red virtual con subredes
- Una tarjeta de interfaz de red
Hay otros recursos que son opcionales, como los siguientes:
- Azure Load Balancer
- Grupos de seguridad de red
- Dirección IP pública
- Tablas de rutas y mucho más
En esta sección abordaremos el proceso de creación de máquinas virtuales mediante
plantillas de ARM. Como se ha mencionado anteriormente en esta sección, tenemos que
crear algunos recursos, de los que dependerá el recurso de máquina virtual, antes de crear
el propio recurso de máquina virtual.
Es importante tener en cuenta que no siempre es necesario crear los recursos
dependientes. Deben crearse solo si aún no existen. Si ya están disponibles dentro de la
suscripción de Azure, el recurso de máquina virtual se puede aprovisionar mediante una
referencia a esos recursos dependientes.
La plantilla depende de unos pocos parámetros que se le deben suministrar en el momento
de ejecutar la plantilla. Estas variables se refieren a la ubicación de los recursos y algunos
de sus valores de configuración. Estos valores se toman de los parámetros porque pueden
cambiar de una implementación a otra, por lo que el uso de parámetros ayuda a mantener
la plantilla genérica.
El primer paso es crear una cuenta de almacenamiento, como se muestra en el código
siguiente:
{
«type»: «Microsoft.Storage/storageAccounts»,
«name»: «[variables(‘storageAccountName’)]»,
«apiVersion»: «2019-04-01»,
«location»: «[parameters(‘location’)]»,
«sku»: {
«name»: «Standard_LRS»
},
«kind»: «Storage»,
«properties»: {}
},
Después de crear una cuenta de almacenamiento, se debe definir una red virtual dentro
de la plantilla de ARM. Es importante tener en cuenta que no hay dependencia entre
una cuenta de almacenamiento y una red virtual. Pueden crearse en paralelo. El recurso
de red virtual tiene una subred como su recurso secundario. Ambos se configuran con sus
intervalos IP; normalmente, la subred tiene un intervalo más pequeño que el intervalo IP
de la red virtual:
{
«apiVersion»: «2019-09-01»,
«type»: «Microsoft.Network/virtualNetworks»,
«name»: «[variables(‘virtualNetworkName’)]»,
«location»: «[parameters(‘location’)]»,
«properties»: {
«addressSpace»: {
«addressPrefixes»: [
«[variables(‘addressPrefix’)]»
]
},
«subnets»: [
{
«name»: «[variables(‘subnetName’)]»,
«properties»: {
«addressPrefix»: «[variables(‘subnetPrefix’)]»
}
}
}
}
Si es necesario acceder a la máquina virtual a través de Internet público, también se
puede crear una dirección IP pública, como se muestra en el código siguiente. Una vez
más, es un recurso completamente independiente y se puede crear en paralelo con la
cuenta de almacenamiento y la red virtual:
{
«apiVersion»: «2019-11-01»,
«type»: «Microsoft.Network/publicIPAddresses»,
«name»: «[variables(‘publicIPAddressName’)]»,
«location»: «[parameters(‘location’)]»,
«properties»: {
«publicIPAllocationMethod»: «Dynamic»,
«dnsSettings»: {
«domainNameLabel»: «[parameters(‘dnsLabelPrefix’)]»
}
}
},
Después de crear la red virtual, la cuenta de almacenamiento y la dirección IP pública,
se puede crear una interfaz de red. Una interfaz de red depende de una red virtual y un
recurso de subred. Opcionalmente, también se pueden asociar a una dirección IP pública.
Esto se muestra en el siguiente código:
{
«apiVersion»: «2019-11-01»,
«type»: «Microsoft.Network/networkInterfaces»,
«name»: «[variables(‘nicName’)]»,
«location»: «[parameters(‘location’)]»,
«dependsOn»: [
«[resourceId(‘Microsoft.Network/publicIPAddresses/’,
variables(‘publicIPAddressName’))]»,
«[resourceId(‘Microsoft.Network/virtualNetworks/’,
variables(‘virtualNetworkName’))]»
],
«properties»: {
«ipConfigurations»: [
{
«name»: «ipconfig1»,
«properties»: {
«privateIPAllocationMethod»: «Dynamic»,
«publicIPAddress»: {
«id»: «[resourceId(‘Microsoft.Network/
publicIPAddresses’,variables(‘publicIPAddressName’))]»
},
«subnet»: {
«id»: «[variables(‘subnetRef’)]»
}
}
}
]
}
},
Es importante tener en cuenta que tanto la dirección IP pública como la subred se
denominan mediante sus identificadores únicos de Azure.
Después de la creación de la interfaz de red, tenemos todos los recursos necesarios para
crear una máquina virtual. En el siguiente bloque de código se muestra cómo crear una
máquina virtual utilizando una plantilla de ARM. Tiene una dependencia en la tarjeta de
red y la cuenta de almacenamiento. Esto crea indirectamente dependencias en la red
virtual, la subred y la dirección IP pública.
Para la máquina virtual, configuramos la configuración de recursos obligatorios, incluidos
type, apiVersion, location y name junto con todas las dependencias, como se muestra en
el siguiente código:
{
«apiVersion»: «2019-07-01»,
«type»: «Microsoft.Compute/virtualMachines»,
«name»: «[variables(‘vmName’)]»,
«location»: «[resourceGroup().location]»,
«tags»: {
«displayName»: «VirtualMachine»
},
«dependsOn»: [
«[concat(‘Microsoft.Storage/storageAccounts/’,
variables(‘storageAccountName’))]»,
«[concat(‘Microsoft.Network/networkInterfaces/’, variables(‘nicName’))]»
],
«properties»: {
«hardwareProfile»: { «vmSize»: «[variables(‘vmSize’)]» },
«availabilitySet»: {
«id»: «[resourceId(‘Microsoft.Compute/availabilitySets’,
parameters(‘adAvailabilitySetName’))]»
},
«osProfile»: {
«computerName»: «[variables(‘vmName’)]»,
«adminUsername»: «[parameters(‘adminUsername’)]»,
«adminPassword»: «[parameters(‘adminPassword’)]»
},
«storageProfile»: {
«imageReference»: {
«publisher»: «[variables(‘imagePublisher’)]»,
«offer»: «[variables(‘imageOffer’)]»,
«sku»: «[parameters(‘windowsOSVersion’)]»,
«version»: «latest»
},
«osDisk»: { «createOption»: «FromImage» },
«copy»: [
{
«name»: «dataDisks»,
«count»: 3,
«input»: {
«lun»: «[copyIndex(‘dataDisks’)]»,
«createOption»: «Empty»,
«diskSizeGB»: «1023»,
«name»: «[concat(variables(‘vmName’), ‘-datadisk’, copyIndex(‘dataDisks’))]»
}
}
]
},
«networkProfile»: {
«networkInterfaces»: [
{
«id»: «[resourceId(‘Microsoft.Network/networkInterfaces’,
variables(‘nicName’))]»
}
]
}
}
}
En el código anterior, la máquina virtual se configura con:
- Un perfil de hardware: el tamaño de la máquina virtual.
- Un perfil de SO: el nombre y las credenciales para iniciar sesión en la máquina virtual.
- Un perfil de almacenamiento: la cuenta de almacenamiento en la que se va a almacenar
el archivo de disco duro virtual (VHD) de la máquina virtual, incluidos los discos de datos. - Un perfil de red: la referencia a la tarjeta de interfaz de red.
En la siguiente sección se mostrará un ejemplo de uso de plantillas de ARM para
aprovisionar una solución de plataforma como servicio.
Soluciones de PaaS que utilizan plantillas de ARM
Los recursos y soluciones de plataforma como servicio (PaaS) se pueden implementar
mediante plantillas de ARM. Uno de los principales recursos relacionados con PaaS es Azure
Web Apps y, en esta sección, nos centraremos en la creación de aplicaciones web en Azure
utilizando plantillas de ARM.
La plantilla espera que se suministren algunos parámetros al ejecutarla. Los parámetros
necesarios son la SKU del plan de App Service, la región de Azure que hospeda los recursos
y la capacidad de SKU del plan de App Service.
Hay un par de variables declaradas dentro de la plantilla para que sea genérica y fácil de
mantener. La primera, hostingPlanName, es para el nombre del plan de App Service y la
siguiente, webSiteName, es para el propio servicio de aplicación.
Hay como mínimo dos recursos que se deben declarar y aprovisionar para una aplicación
web en funcionamiento en Azure. Son las siguientes:
- El plan de Azure App Service
- Azure App Service
El primer paso para crear una aplicación web en Azure es definir la configuración de
un plan de Azure App Service. El código siguiente define un nuevo plan de App Service.
Es importante tener en cuenta que el tipo de recurso es Microsoft.Web/serverfarms.
La mayoría de los valores de configuración del plan, como location, name y capacity,
llegan como parámetros a la plantilla de ARM:
{
«apiVersion»: «2019-08-01»,
«name»: «[variables(‘hostingPlanName’)]»,
«type»: «Microsoft.Web/serverfarms»,
«location»: «[parameters(‘location’)]»,
«tags»: {
«displayName»: «HostingPlan»
},
«sku»: {
«name»: «[parameters(‘skuName’)]»,
«capacity»: «[parameters(‘skuCapacity’)]»
},
«properties»: {
«name»: «[variables(‘hostingPlanName’)]»
}
},
El siguiente recurso que debe aprovisionarse después de un plan es el propio servicio de
aplicación. Es importante que se cree una dependencia entre ambos recursos de forma que
ya se haya creado un plan antes de que se cree el propio servicio de aplicación:
{
«apiVersion»: «2019-08-01»,
«name»: «[variables(‘webSiteName’)]»,
«type»: «Microsoft.Web/sites»,
«location»: «[parameters(‘location’)]»,
«dependsOn»: [
«[variables(‘hostingPlanName’)]»
],
«properties»: {
«name»: «[variables(‘webSiteName’)]»,
«serverFarmId»: «[resourceId(‘Microsoft.Web/serverfarms’,
variables(‘hostingPlanName’))]»
},
«resources»: [
{
«apiVersion»: «2019-08-01»,
«type»: «config»,
«name»: «connectionstrings»,
«dependsOn»: [
«[variables(‘webSiteName’)]»
],
«properties»: {
«DefaultConnection»: {
«value»: «[concat( ‘sql connection string here’)]»,
«type»: «SQLAzure»
}
}
}
]
}
En el código anterior, se define un recurso de tipo Microsoft.Web/sites y tiene una
dependencia en el plan. También utiliza el plan de App Service y lo asocia mediante
serverFarmId. Además, declara una cadena de conexión que se puede utilizar para
conectarse a SQL Server.
En esta sección se muestra un ejemplo de cómo crear una solución de PaaS en Azure con
una plantilla de ARM. Del mismo modo, otras soluciones de PaaS, incluidas las aplicaciones
de Azure Function, Kubernetes Service y Service Fabric, entre muchas otras, se pueden
crear utilizando plantillas de ARM.
Soluciones relacionadas con datos mediante plantillas de ARM
Hay muchos recursos en Azure relacionados con la administración y el almacenamiento de
datos. Algunos de los recursos importantes relacionados con los datos incluyen Azure SQL,
Azure Cosmos DB, Azure Data Lake Storage, Data Lake Analytics, Azure Synapsis, Databricks
y Data Factory.
Todos estos recursos se pueden aprovisionar y configurar mediante una plantilla de ARM.
En esta sección, crearemos una plantilla de ARM para aprovisionar un recurso de Data
Factory responsable de migrar datos desde Azure Blob Storage a Azure SQL Database
mediante procedimientos almacenados.
Encontrarás el archivo de parámetros junto con la plantilla. Estos valores pueden cambiar
de una implementación a otra; conservaremos la plantilla genérica para que puedas
personalizarla y usarla fácilmente con otras implementaciones también.
Todo el código de esta sección se encuentra en https://github.com/Azure/azurequickstart-
templates/blob/master/101-data-factory-blob-to-sql-copy-stored-proc.
El primer paso es declarar la configuración de la factoría de datos en la plantilla de ARM,
como se muestra en el código siguiente:
«name»: «[variables(‘dataFactoryName’)]»,
«apiVersion»: «2018-06-01»,
«type»: «Microsoft.DataFactory/datafactories»,
«location»: «[parameters(‘location’)]»,
Cada factoría de datos tiene varios servicios vinculados. Estos servicios vinculados actúan
como conectores para obtener datos en la factoría de datos, o la factoría de datos puede
enviarles datos. En la siguiente lista de código se crea un servicio vinculado para la cuenta
de Azure Storage desde la que se leerán los blobs en la factoría de datos y otro servicio
vinculado para Azure SQL Database:
{
«type»: «linkedservices»,
«name»: «[variables(‘storageLinkedServiceName’)]»,
«apiVersion»: «2018-06-01»,
«dependsOn»: [
«[variables(‘dataFactoryName’)]»
],
«properties»: {
«type»: «AzureStorage»,
«description»: «Azure Storage Linked Service»,
«typeProperties»: {
«connectionString»:
«[concat(‘DefaultEndpointsProtocol=https;
AccountName=’,parameters(‘storageAccountName’),’;
AccountKey=’,parameters(‘storageAccountKey’))]»
}
}
},
{
«type»: «linkedservices»,
«name»: «[variables(‘sqlLinkedServiceName’)]»,
«apiVersion»: «2018-06-01»,
«dependsOn»: [
«[variables(‘dataFactoryName’)]»
],
«properties»: {
«type»: «AzureSqlDatabase»,
«description»: «Azure SQL linked service»,
«typeProperties»: {
«connectionString»: «[concat(‘Data Source=tcp:’, parameters(‘sqlServerName’),
‘.database.windows.net,1433;Initial Catalog=’, parameters(‘sqlDatabaseName’),
‘;Integrated Security=False;User ID=’, parameters(‘sqlUserId’), ‘;Password=’,
parameters(‘sqlPassword’), ‘;Connect Timeout=30;Encrypt=True’)]»
}
}
},
Después de los servicios vinculados, es el momento de definir los conjuntos de datos para
Azure Data Factory. Los conjuntos de datos ayudan a identificar los datos que se deben leer
y colocar en la factoría de datos. También pueden representar los datos temporales que
debe almacenar Data Factory durante la transformación o incluso la ubicación de destino
en la que se escribirán los datos. El siguiente bloque de código crea tres conjuntos de datos:
uno para cada uno de los aspectos de los conjuntos de datos que se acaba de mencionar.
El conjunto de datos de lectura se muestra en el siguiente bloque de código:
{
«type»: «datasets»,
«name»: «[variables(‘storageDataset’)]»,
«dependsOn»: [
«[variables(‘dataFactoryName’)]»,
«[variables(‘storageLinkedServiceName’)]»
],
«apiVersion»: «2018-06-01»,
«properties»: {
«type»: «AzureBlob»,
«linkedServiceName»: «[variables(‘storageLinkedServiceName’)]»,
«typeProperties»: {
«folderPath»: «[concat(parameters(‘sourceBlobContainer’), ‘/’)]»,
«fileName»: «[parameters(‘sourceBlobName’)]»,
«format»: {
«type»: «TextFormat»
}
},
«availability»: {
«frequency»: «Hour»,
«interval»: 1
},
«external»: true
}
},
El conjunto de datos intermedio se muestra en las siguientes líneas de código:
{
«type»: «datasets»,
«name»: «[variables(‘intermediateDataset’)]»,
«dependsOn»: [
«[variables(‘dataFactoryName’)]»,
«[variables(‘sqlLinkedServiceName’)]»
],
«apiVersion»: «2018-06-01»,
«properties»: {
«type»: «AzureSqlTable»,
«linkedServiceName»: «[variables(‘sqlLinkedServiceName’)]»,
«typeProperties»: {
«tableName»: «[variables(‘intermediateDataset’)]»
},
«availability»: {
«frequency»: «Hour»,
«interval»: 1
}
}
},
Por último, el conjunto de datos utilizado para el destino se muestra aquí:
{
«type»: «datasets»,
«name»: «[variables(‘sqlDataset’)]»,
«dependsOn»: [
«[variables(‘dataFactoryName’)]»,
«[variables(‘sqlLinkedServiceName’)]»
],
«apiVersion»: «2018-06-01»,
«properties»: {
«type»: «AzureSqlTable»,
«linkedServiceName»: «[variables(‘sqlLinkedServiceName’)]»,
«typeProperties»: {
«tableName»: «[parameters(‘sqlTargetTable’)]»
},
«availability»: {
«frequency»: «Hour»,
«interval»: 1
}
}
},
Finalmente, necesitamos una canalización en Data Factory que pueda reunir todos
los conjuntos de datos y servicios vinculados, y ayudar a crear soluciones de datos de
extracción-transformación-carga. Una canalización consta de varias actividades y cada una
de ellas cumple una tarea determinada. Todas estas actividades se pueden definir dentro
de la plantilla de ARM, como verás ahora. La primera actividad copia los blobs de la cuenta
de almacenamiento en un SQL Server intermedio, como se muestra en el código siguiente:
{
«type»: «dataPipelines»,
«name»: «[variables(‘pipelineName’)]»,
«dependsOn»: [
«[variables(‘dataFactoryName’)]»,
«[variables(‘storageLinkedServiceName’)]»,
«[variables(‘sqlLinkedServiceName’)]»,
«[variables(‘storageDataset’)]»,
«[variables(‘sqlDataset’)]»
],
«apiVersion»: «2018-06-01»,
«properties»: {
«description»: «Copies data from Azure Blob to Sql DB while invoking stored
procedure»,
«activities»: [
{
«name»: «BlobtoSqlTableCopyActivity»,
«type»: «Copy»,
«typeProperties»: {
«source»: {
«type»: «BlobSource»
},
«sink»: {
«type»: «SqlSink»,
«writeBatchSize»: 0,
«writeBatchTimeout»: «00:00:00»
}
},
«inputs»: [
{
«name»: «[variables(‘storageDataset’)]»
}
],
«outputs»: [
{
«name»: «[variables(‘intermediateDataset’)]»
}
]
},
{
«name»: «SqlTabletoSqlDbSprocActivity»,
«type»: «SqlServerStoredProcedure»,
«inputs»: [
{
«name»: «[variables(‘intermediateDataset’)]»
}
],
«outputs»: [
{
«name»: «[variables(‘sqlDataset’)]»
}
],
«typeProperties»: {
«storedProcedureName»: «[parameters(‘sqlWriterStoredProcedureName’)]»
},
«scheduler»: {
«frequency»: «Hour»,
«interval»: 1
},
«policy»: {
«timeout»: «02:00:00»,
«concurrency»: 1,
«executionPriorityOrder»: «NewestFirst»,
«retry»: 3
}
}
],
«start»: «2020-10-01T00:00:00Z»,
«end»: «2020-10-02T00:00:00Z»
}
}
]
}
La última actividad copia datos del conjunto de datos intermedio al conjunto de datos de
destino final.
También hay tiempos de inicio y fin durante los cuales debe ejecutarse la canalización.
Esta sección se ha centrado en la creación de una plantilla de ARM para una solución
relacionada con los datos. En la siguiente sección, abordaremos las plantillas de ARM
para crear centros de datos en Azure con Active Directory y DNS.
Crear una solución de IaaS en Azure con Active Directory y DNS
La creación de una solución de IaaS en Azure implica crear varias máquinas virtuales,
promover que una máquina virtual sea un controlador de dominio y hacer que
otras máquinas virtuales se unan al controlador de dominio como nodos unidos al
dominio. También significa instalar un servidor DNS para la resolución de nombres
y, opcionalmente, un servidor de acceso para acceder a estas máquinas virtuales de
forma segura.
La plantilla crea un bosque de Active Directory en las máquinas virtuales. Crea varias
máquinas virtuales basadas en los parámetros suministrados.
La plantilla crea:
- Un par de conjuntos de disponibilidad
- Una red virtual
- Grupos de seguridad de red para definir los puertos permitidos y no permitidos y las
direcciones IP
A continuación, la plantilla hace lo siguiente:
- Aprovisiona uno o dos dominios. El dominio raíz se crea de forma predeterminada;
el dominio secundario es opcional - Aprovisiona dos controladores de dominio por dominio
- Ejecuta los scripts de configuración de estado deseados para promover que una
máquina virtual sea un controlador de dominio
Podemos crear varias máquinas virtuales utilizando el enfoque que se describe en la sección
Soluciones de máquinas virtuales que utilizan plantillas de ARM. Sin embargo, estas máquinas
virtuales deben formar parte de un conjunto de disponibilidad si necesitan tener alta
disponibilidad. Cabe señalar que los conjuntos de disponibilidad proporcionan un 99,95 %
de disponibilidad para las aplicaciones implementadas en estas máquinas virtuales, mientras
que las zonas de disponibilidad proporcionan un 99,99 % de disponibilidad.
Un conjunto de disponibilidad puede configurarse como se muestra en el siguiente código:
{
«name»: «[variables(‘adAvailabilitySetNameRoot’)]»,
«type»: «Microsoft.Compute/availabilitySets»,
«apiVersion»: «2019-07-01»,
«location»: «[parameters(‘location’)]»,
«sku»: {
«name»: «Aligned»
},
«properties»: {
«PlatformUpdateDomainCount»: 3,
«PlatformFaultDomainCount»: 2
}
},
Una vez creado el conjunto de disponibilidad, se debe añadir un perfil adicional a la
configuración de la máquina virtual para asociar la máquina virtual al conjunto de
disponibilidad, como se muestra en el siguiente código:
«availabilitySet» : {
«id»: «[resourceId(‘Microsoft.Compute/availabilitySets’,
parameters(‘adAvailabilitySetName’))]»
}
Debes tener en cuenta que los conjuntos de disponibilidad son obligatorios para utilizar
equilibradores de carga con máquinas virtuales.
Otro cambio necesario en la configuración de la red virtual es agregar información de DNS,
como se muestra en el siguiente código:
{
«name»: «[parameters(‘virtualNetworkName’)]»,
«type»: «Microsoft.Network/virtualNetworks»,
«location»: «[parameters(‘location’)]»,
«apiVersion»: «2019-09-01»,
«properties»: {
«addressSpace»: {
«addressPrefixes»: [
«[parameters(‘virtualNetworkAddressRange’)]»
]
},
«dhcpOptions»: {
«dnsServers»: «[parameters(‘DNSServerAddress’)]»
},
«subnets»: [
{
«name»: «[parameters(‘subnetName’)]»,
«properties»: {
«addressPrefix»: «[parameters(‘subnetRange’)]»
}
}
]
}
},
Por último, para convertir una máquina virtual en Active Directory, debe ejecutarse en la
máquina virtual un script de PowerShell o un script de configuración de estado deseado
(DSC). Incluso para unir otras máquinas virtuales al dominio, se debe ejecutar otro conjunto
de scripts en esas máquinas virtuales.
Los scripts se pueden ejecutar en la máquina virtual mediante el recurso
CustomScriptExtension, como se muestra en el código siguiente:
{
«type»: «Microsoft.Compute/virtualMachines/extensions»,
«name»: «[concat(parameters(‘adNextDCVMName’),’/PrepareNextDC’)]»,
«apiVersion»: «2018-06-01»,
«location»: «[parameters(‘location’)]»,
«properties»: {
«publisher»: «Microsoft.Powershell»,
«type»: «DSC»,
«typeHandlerVersion»: «2.21»,
«autoUpgradeMinorVersion»: true,
«settings»: {
«modulesURL»: «[parameters(‘adNextDCConfigurationModulesURL’)]»,
«configurationFunction»: «[parameters(‘adNextDCConfigurationFunction’)]»,
«properties»: {
«domainName»: «[parameters(‘domainName’)]»,
«DNSServer»: «[parameters(‘DNSServer’)]»,
«DNSForwarder»: «[parameters(‘DNSServer’)]»,
«adminCreds»: {
«userName»: «[parameters(‘adminUserName’)]»,
«password»: «privateSettingsRef:adminPassword»
}
}
},
«protectedSettings»: {
«items»: {
«adminPassword»: «[parameters(‘adminPassword’)]»
}
}
}
},
En esta sección, hemos creado un centro de datos en Azure mediante el paradigma de
IaaS. Hemos creado varias máquinas virtuales y convertido una de ellas en controlador de
dominio, instalado DNS y le hemos asignado un dominio. Ahora, otras máquinas virtuales
de la red pueden unirse a este dominio y pueden formar un centro de datos completo
en Azure.
Consulta https://github.com/Azure/azure-quickstart-templates/tree/master/301-createad-
forest-with-subdomain para obtener la lista completa de código para crear un centro de
datos en Azure.
Resumen
La opción de implementar recursos mediante una sola implementación en suscripciones,
grupos de recursos y regiones diversos permite mejores posibilidades de implementación,
reducir los errores de implementación y acceder a ventajas avanzadas, como la creación de
sitios de recuperación ante desastres y lograr una alta disponibilidad.
En este capítulo, has visto cómo crear varios tipos diferentes de soluciones mediante
plantillas de ARM. Aquí se ha incluido la creación de una solución basada en infraestructura
con máquinas virtuales; una solución basada en plataforma con Azure App Service; una
solución relacionada con los datos que utiliza el recurso de Data Factory (incluida su
configuración); y un centro de datos en Azure con máquinas virtuales, Active Directory
y DNS instalados sobre la máquina virtual.
En el siguiente capítulo, nos centraremos en la creación de plantillas de ARM modulares,
una habilidad fundamental para los arquitectos que realmente quieren llevar sus plantillas
de ARM a un nivel superior. También veremos diversas opciones