



Datos. No puede hacerlo sin ellos. Casi todas las aplicaciones que compila y ejecuta crean, procesan o recuperan datos. Tradicionalmente, estos datos se han almacenado en una bases de datos estructurados como MySQL, Microsoft SQL o PostgreSQL. Estas grandes bases de datos estructurados son establecidas y bien conocidas, tienen amplia documentación y tutoriales, y se puede acceder a ellas desde la mayoría de los lenguajes de programación principales.
Gran poder implica gran responsabilidad y, generalmente, estas bases de datos estructurados tradicionales conllevan una gran infraestructura y tareas de administración. Eso no quiere decir que no debería usarlas, para nada, pero cuando se trata de aplicaciones que se ejecutan a escala global, tener que crear además clústeres de servidores de bases de datos que replican sus datos y enruten de forma inteligente a los clientes a su instancia más cercana no es una tarea fácil.
Es ahí donde Azure Cosmos DB se convierte en su mejor amigo. No necesita preocuparse sobre cómo replicar sus datos, garantizar coherencia y distribuir las solicitudes de los clientes. Solo debe agregar los datos a uno de los muchos modelos disponibles y luego elegir dónde desea que estén disponibles sus datos. En este capítulo, aprenderá sobre los modelos de bases de datos no estructurados en Cosmos DB, cómo crear y configurar su base de datos para distribución global y cómo compilar aplicaciones web que utilicen su instancia de Cosmos DB altamente redundante y escalable.
¿Qué es Cosmos DB?
El capítulo 4 comenzó a explorar bases de datos no estructurados con tablas de Azure Storage. El ejemplo era básico, pero los conceptos son el fundamento de Cosmos DB. En primer lugar, demos un paso atrás y analicemos lo que significa una base de datos estructurada y no estructurada.
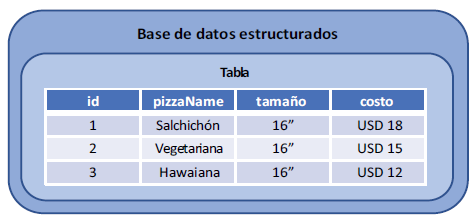
En las bases de datos estructurados, cada servidor debe contener toda la base de datos para que las consultas y la recuperación de información sean correctas. Los datos se juntan en consultas obtenidas de distintas tablas en función de los criterios que el desarrollador compila como parte la consulta estructurada. De ahí proviene el término Structured Query Language (SQL) o lenguaje de consulta estructurado. A medida que las bases de datos crecen tanto en tamaño como en complejidad, los servidores que ejecutan la base de datos deben ser lo suficientemente dimensionados para manejar esos datos in-memory. Eso se vuelve difícil y costoso con bases de datos demasiado grandes. Dado que necesitan una estructura, también resulta complicado agregar propiedades y cambiar la estructura más adelante.
Bases de datos (NoSQL) no estructurados
Los datos no estructurados en bases de datos NoSQL no se almacenan en tablas de filas y columnas; más bien, se almacenan en matrices dinámicas que le permiten agregar nuevas propiedades para un elemento, según sea necesario. Una gran ventaja de este enfoque es que puede agregar rápidamente un nuevo tipo de pizza o ingrediente especial sin cambiar la estructura subyacente de la base de datos. En una base de datos estructurados, es necesario agregar una nueva columna a una tabla y luego actualizar la aplicación para utilizar la columna adicional. En las bases de datos NoSQL.
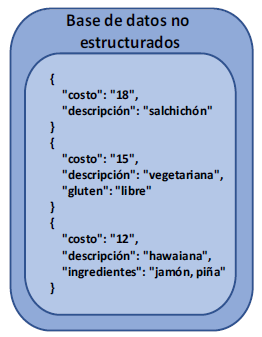
Las bases de datos de NoSQL también ofrecen diferentes modelos de base de datos. Estos modelos dan una indicación de cómo se almacenan los datos y se recuperan en la base de datos. El modelo que utilice varía en función del tamaño y el formato de los datos con los que trabaja y de cómo necesite representar los datos de la aplicación. Estos modelos incluyen documento, gráfico y tabla. No se quede entrampado en los modelos por ahora; los diferentes modelos funcionan mejor para diferentes conjuntos de datos no estructurados, dependiendo de cómo necesite relacionar y consultar los datos. La clave está en entender que las bases de datos no estructurados NoSQL tienen un concepto subyacente diferente a la forma en que almacenan y recuperan los datos, lo que puede utilizar a su ventaja a medida que compila y ejecuta aplicaciones en la nube en Azure.
Escalado de bases de datos
¿Recuerda que dijimos que para una base de datos estructurados, normalmente toda la base de datos debe existir en cada servidor? A medida que empieza a tener bases de datos muy grandes, necesita servidores cada vez más grandes para ejecutarlas. Es posible que nunca trabaje con bases de datos que crezcan a cientos de gigabytes o incluso terabytes de tamaño, pero las bases de datos NoSQL sirven para entender cómo las bases de datos crecen y escalan de manera diferente a las bases de datos SQL. La diferencia es que las bases de datos NoSQL suelen escalar de forma horizontal en lugar de vertical.
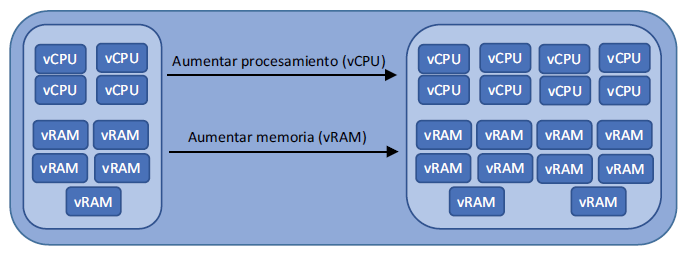
Hay un límite de cuánto puede escalar verticalmente una VM, es decir, darle más memoria y CPU. Empieza a tener problemas de rendimiento en otras partes de la unidad de proceso al exprimir al máximo el rendimiento de almacenamiento y el ancho de banda de la red. Y eso sin mencionar su billetera (o la billetera de su jefe) cuando ve la cuenta de esas inmensas VM. Como resumen del capítulo 9, la escalabilidad vertical se ilustra en la figura 10.3. Ahora imagine un clúster de esas VM con inmensas bases de datos, porque busca redundancia y resiliencia para su aplicación, ¿verdad?
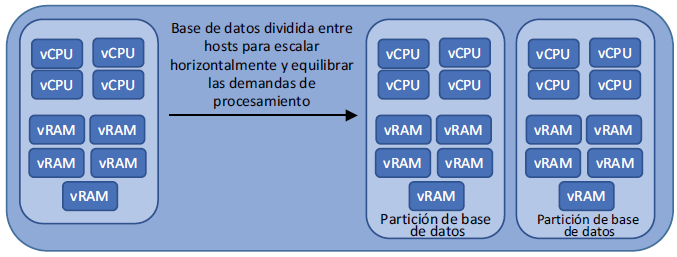
Por el contrario, la escalabilidad horizontal le permite ejecutar VM de base de datos con menos recursos a un precio más bajo. Para hacer esto, las bases de datos NoSQL dividen los datos en nodos de la base de datos y dirigen las solicitudes desde su aplicación al nodo apropiado. Los demás nodos del clúster no necesitan saber dónde se almacenan todos los datos; solo necesitan responder a sus propias solicitudes. Puede agregar rápidamente nodos a un clúster en respuesta a la demanda del cliente según sea necesario.
Como resultado, en una base de datos NoSQL, no es necesario que toda la base de datos quepa en la memoria de un host. Solo se necesita guardar y procesar una parte de la base de datos, una partición. Si su aplicación funciona con grandes cantidades de datos estructurados, una base de datos NoSQL puede perjudicar el rendimiento, ya que los diferentes hosts consultan sus datos para luego devolver al cliente. Si tiene una gran cantidad de datos no estructurados que procesar, las bases NoSQL pueden optimizar el rendimiento o, al menos, ofrecen la ventaja de administración y eficiencia. En la figura se muestra un ejemplo de cómo las bases de datos no estructurados escalan horizontalmente entre hosts.
Cosmos DB se encarga de todo
Entonces, ¿qué es Cosmos DB? Es una plataforma de bases de datos globalmente distribuida y de escalado automático que le permite utilizar diversas formas de bases de datos NoSQL. Al igual que con servicios como Web Apps, Cosmos DB se encarga de gran parte de la administración que usted debe realizar. Cuando crea una aplicación web, no es necesario configurar equilibradores de carga o clústeres: se eligen las regiones y se puede configurar escalado automático y, a continuación, se carga el código de la aplicación. La plataforma Azure se encarga de cómo replicar y distribuir el tráfico de aplicaciones web de forma altamente disponible. Con Cosmos DB, no debe preocuparse por la gran cantidad de bases de datos que necesita, cuánta memoria asignar o cómo replicar datos para redundancia. Simplemente elige la cantidad de rendimiento que podría necesitar y las regiones para guardar sus datos, y luego empieza a agregar datos.
Este capítulo utiliza un modelo SQL para Cosmos DB, pero los datos se almacenan en formato NoSQL, JSON. Estos pueden ser conceptos nuevos, pero quédese conmigo. Se pueden usar otros modelos, incluido Mongo, Cassandra, Gremlin y Table. La funcionalidad es la misma para todos: escoge el modelo, elige las regiones y agrega los datos. Ese es el poder de Cosmos DB.
Creación de una cuenta y base de datos de Cosmos DB
Veamos Cosmos DB y las bases de datos no estructuradas en acción, lo que podemos hacer de un par de maneras. La primera es utilizar Azure Portal para crear una cuenta, seleccionar y crear un modelo de base de datos e ingresar datos en la base de datos para que la aplicación pueda consultarla. O bien, puede utilizar la CLI de Azure, Azure PowerShell o kits de desarrollo de software (SDK) específicos del lenguaje para crearlo todo en código. Usemos Azure Portal para que también podamos crear y consultar los datos visualmente.
Creación y relleno de una base de datos de Cosmos DB
En el capítulo 4, creó su primera base de datos NoSQL con una tabla de Azure Storage. Utilicemos Cosmos DB para crear una base de datos similar, esta vez una que ofrezca todas las opciones de redundancia geográfica y replicación para asegurarse de que los clientes puedan pedir pizzas en su tienda en línea sin interrupciones. Vamos a crear una cuenta de Cosmos DB y una base de datos de documentos, y luego agreguemos algunos datos para tres tipos de pizzas.
Pruébelo ahora
Para ver Cosmos DB en acción, cree una cuenta a través de Azure Portal:
1 Abra Azure Portal y seleccione Crear un recurso en la esquina superior izquierda del panel.
2 Busque y seleccione Azure Cosmos DB y, a continuación, elija Crear.
3 Elija crear un grupo de recursos, como azuremolchapter10 y escriba un nombre único para su cuenta de Cosmos DB, como azuremol.
4 El tipo de modelo que puede utilizar para su base de datos se conoce como API. Para este ejemplo, seleccione Core (SQL) en el menú desplegable.
5 Para Ubicación, seleccione Este de EE. UU. Cosmos DB está disponible en todas las regiones de Azure, pero para este ejemplo, la aplicación web que implemente en el laboratorio de fin del capítulo espera que use Este de EE. UU.
6 Deje la opción de redundancia geográfica como deshabilitada, junto con cualquier otra característica adicional, como las regiones de multiescritura.
Tráfico seguro con puntos de conexión de servicio
Tiene la opción de conectar su Cosmos DB a una red virtual de Azure con algo llamado punto de conexión de servicio. No analizaremos esta opción ahora, pero es una característica interesante que ayuda a asegurar su instancia permitiendo el acceso a la base de datos solo desde una red virtual definida.
Si crea aplicaciones de middleware que utilicen Cosmos DB, o aplicaciones solo internas, puede utilizare un punto de conexión de servicio de red virtual para que el acceso sea desde una red virtual específica, no a través de Internet y con un punto de conexión público. Un número cada vez mayor de servicios de Azure admiten este tipo de puntos de conexión, y es otro ejemplo de cómo ofrecer opciones para asegurar su entorno para que se adapte a los requisitos de su empresa.
7 Cuando esté listo, revise y cree su cuenta de Cosmos DB. Crear una cuenta demora unos minutos.
En este momento su base de datos está vacía, así que exploremos cómo puede guardar algunos datos básicos para el menú de su pizzería. Cosmos DB agrupa los datos de una base de datos en algo llamado contenedor. No, no es el mismo tipo de contenedor que es la fuerza impulsora de Docker, Kubernetes y las aplicaciones nativas de la nube que puede haber oído. Esta confusión de nombres no es una ventaja, pero sigue conmigo por ahora.
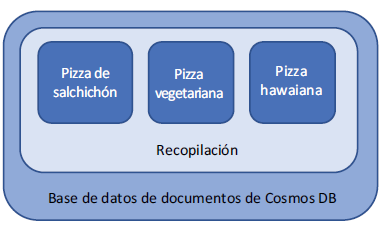
En las bases de datos de Cosmos DB que utilizan el modelo de documento, la información se agrupa lógicamente en contenedores denominados colecciones. Otros modelos de API tienen un nombre ligeramente diferente para la entidad de contenedor, como graph para la API de Gremlin. Para nuestra API de SQL, las colecciones almacenan datos relacionados que se pueden indexar y consultar rápidamente, como se muestra en la figura. Las colecciones no son totalmente diferentes de cómo se organiza una base de datos SQL tradicional en tablas, pero ofrecen mucha más flexibilidad a la hora de distribuir los datos para rendimiento o redundancia.
Como Cosmos DB está diseñado para manejar grandes cantidades de datos y para un alto rendimiento, puede elegir cómo dimensionar y controlar el flujo y el costo de esos datos. El rendimiento se calcula en unidades de solicitud por segundo (RU/s), y una unidad de solicitud equivale a 1 KB de datos de documento. Básicamente, usted define el ancho de banda que quiere para su base de datos. En caso de que no lo haya adivinado, cuanto más ancho de banda (RU/s) quiera, más tendrá que pagar. Cosmos DB le muestra la cantidad de datos que está utilizando y el rendimiento que utiliza su aplicación, y normalmente no necesita preocuparse demasiado sobre dimensionar correctamente las cosas. Para su pizzería, iremos de a poco.
Pruébelo ahora
Para crear una colección y rellenar algunas entradas de la base de datos, complete los siguientes pasos:
1 Busque y seleccione Grupos de recursos en la barra de navegación del lado izquierdo de Azure Portal.
2 Seleccione el grupo de recursos donde creó la base de datos de Cosmos DB, como azuremolchapter10.
3 Seleccione su cuenta de Cosmos DB en la lista de recursos y, a continuación, elija la página Información general.
4 Seleccione para agregar un contenedor.
5 Ya que se trata de su primera base de datos, escriba un nombre, como pizzadb.
6 Deje el rendimiento establecido en el valor predeterminado.
7 Para el ID de contenedor, ingrese pizzas. Este paso crea un contenedor lógico que puede utilizar para guardar elementos en el menú de la pizzería.
8 Escriba una clave de partición de/description para asegurarse de que los tipos de pizza se distribuyan de manera uniforme.
La clave de partición identifica la forma en que se pueden separar los datos en la base de datos. No es realmente necesario en una pequeña base de datos de muestra como esta, pero su uso es una buena práctica a medida que su aplicación se amplía.
9 No elija agregar clave única. Las claves definen más lógicamente el contenedor, por ejemplo, para las subdivisiones de alimentos que pueden pedir los clientes. La colección más amplia es para su menú, pero en bases de datos mucho más grandes, podría querer claves de partición para las pizzas, las bebidas, y los postres.
10 Para crear la base de datos y la colección, seleccione Aceptar.
Ahora tiene una cuenta de Cosmos DB, una base de datos y una colección, pero Cosmos DB todavía no contiene sus pizzas. Puede importar algunos datos o escribir código que incorpora una gran cantidad de datos. Vamos a crear manualmente tres pizzas para explorar algunas de las herramientas gráficas incorporadas en Azure Portal para buscar, consultar y manipular los datos en su base de datos de Cosmos DB.
Pruébelo ahora
Para agregar algunas entradas a la base de datos, complete los siguientes pasos, como se muestra en la figura:
1 En su cuenta de Cosmos DB, elija Explorador de datos en el menú de la izquierda en la ventana Información general.
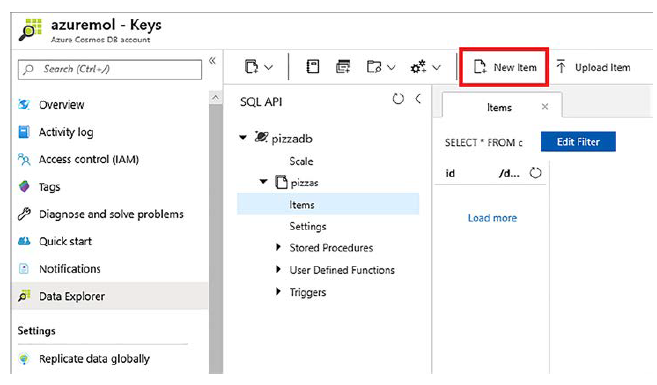
2 Amplíe primero la base de datos pizzadb y luego la colección de pizzas.
3 Agregue un nuevo elemento para poner algunas pizzas en la base de datos. Los datos se agregan en formato JSON.
4 En el cuadro de texto, sustituya cualquier texto existente por los siguientes datos para crear un nuevo elemento de menú para una pizza básica de pepperoni:
{
«description»: «Pepperoni»,
«cost»: «18»
}
5 Para agregar los datos a la base de datos, seleccione Guardar.
6 Agregue otra pizza a su menú. Esta vez, agregue una propiedad para indicar que esta pizza tiene masa sin gluten. No necesita hacer nada especial en la base de datos subyacente, simplemente agregue otra propiedad a sus datos. Para agregar otro elemento nuevo, escriba los siguientes datos y seleccione Guardar:
{
«description»: «Veggie»,
«cost»: «15»,
«gluten»: «free»
}
7 Agregue un último tipo de pizza. Esta vez, agregue una propiedad que incluya los ingredientes de la pizza. Para agregar otro elemento nuevo, escriba los siguientes datos y seleccione Guardar:
{
«description»: «Hawaiian»,
«cost»: «12»,
«toppings»: «ham, pineapple»
}
Estas tres entradas muestran el poder de una base de datos NoSQL. Agregó propiedades a las entradas sin necesidad de actualizar el esquema de la base de datos. Dos propiedades diferentes mostraron que la pizza vegetariana tiene masa sin gluten y qué ingredientes tiene la pizza hawaiana. Cosmos DB acepta esas propiedades adicionales y los datos ahora están disponibles para sus aplicaciones.
Se agregan algunas propiedades JSON adicionales para cosas como id, _rid y _self. Estas no son propiedades por las que tenga que preocuparse demasiado por ahora. Cosmos DB usa estas propiedades para realizar seguimiento e identificar los datos; no debe editarlos o eliminarlos manualmente.
Agregar redundancia global a una base de datos de Cosmos DB
Ahora tiene una base de datos de Cosmos DB que guarda un menú básico de pizzas en la región Este de EE. UU. ¡Pero su pizzería está lista para abrir franquicias en todo el mundo! Replique los datos de sus pizzas en regiones de Azure en diferentes ubicaciones, cerca de sus nuevos clientes.
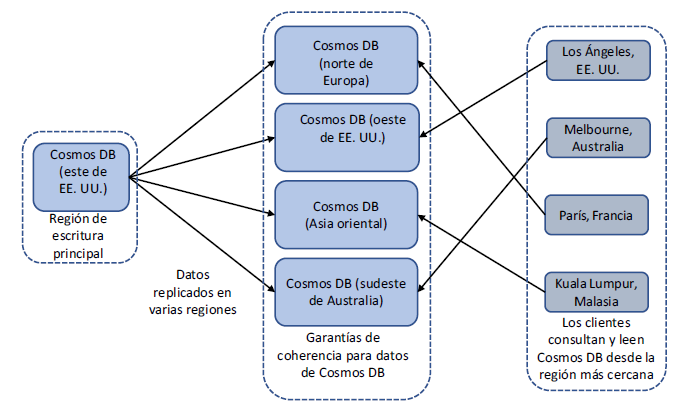
¿Para qué sirve hacer esto? Si todos sus clientes leen y escriben datos de la base de datos en una región, es una gran cantidad de posible tráfico cruzando cables bajo el océano y enrutamiento en todo el mundo. Para proporcionar la mejor experiencia de baja latencia a los clientes, puede replicar sus datos a las regiones de Azure disponibles alrededor del mundo, y los clientes podrán conectarse a la réplica más cercana a ellos, como se muestra en la figura.
Los modelos de coherencia y las garantías se incorporan a la plataforma de Cosmos DB para gestionar automáticamente esta coherencia y replicación de datos. Puede desasignar una o más regiones como ubicación de escritura primaria. Los ejemplos de este libro utilizan un único punto de escritura, pero puede utilizar el soporte de Multimaster para escribir datos en el punto de conexión más cercano para que luego se propague de forma asincrónica a otras regiones. Los datos también se replican rápidamente en las regiones leídas que usted designe. Puede controlar el orden de conmutación por error para designar regiones de lectura y, con la aplicación, especificar automática o manualmente regiones desde las que se leerán.
Puede definir un modelo de coherencia (que es más una consideración de diseño que operacional) que defina la rapidez con la que se replican las escrituras en varias regiones. Los modelos de coherencia van de fuerte, que espera que las escrituras replicadas sean confirmadas por réplicas y así garantizar que las lecturas sean uniformes, a definitivo, que es más relajado. El modelo definitivo garantiza que todos los datos se repliquen, pero puede haber un ligero retraso cuando las lecturas de réplicas devuelvan valores diferentes hasta que estén todos sincronizados.
Hay un equilibrio entre una distribución geográfica más limitada, como el modelo de coherencia fuerte y una replicación geográfica más amplia que ofrece el modelo de coherencia definitiva, pero entendiendo que hay un ligero retraso mientras se replican los datos. También hay costos relacionados con el ancho de banda y con el procesamiento, dependiendo de la coherencia y la frecuencia con que desea que se repliquen los datos. La plataforma Azure maneja la replicación subyacente de los datos desde su punto de escritura; no es necesario que compile sus aplicaciones para replicar los datos o determinar la mejor manera de leer los datos desde los puntos de conexión replicados.
En una escala global, esto significa que podría tener varias VM o aplicaciones web como las que creó en capítulos anteriores, pero en diferentes regiones del mundo. Esas aplicaciones se conectan a una instancia de Cosmos DB local para consultar y leer todos sus datos. Mediante algunas útiles funciones de tráfico de red Azure que analizaremos en el capítulo 11, los usuarios pueden ser direccionados automáticamente a una de estas instancias de aplicaciones web locales, que también utilizan una instancia local de Cosmos DB. En caso de interrupciones o mantenimiento regionales, la plataforma completa enruta al cliente a la siguiente instancia más cercana.
En el mundo tradicional de las bases de datos estructurados donde usted administra las VM, la instalación de la bases de datos y la configuración de clúster, se requiere una seria planificación de diseño, ya que toda esta configuración es complicada de implementar. Con Cosmos DB, el proceso requiere apenas tres clics.
Pruébelo ahora
Complete los siguientes pasos para replicar sus datos de Cosmos DB globalmente:
1 Busque y seleccione Grupos de recursos en la barra de navegación del lado izquierdo de Azure Portal.
2 Seleccione el grupo de recursos donde creó la base de datos de Cosmos DB, como azuremolchapter10.
3 Seleccione su cuenta de Cosmos DB en la lista de recursos. Esos dos clics fueron gratis, pero ¡empiece a contar desde aquí!
4 Seleccione la opción de menú a la izquierda para replicar los datos de manera global. En el mapa, que muestra todas las regiones de Azure disponibles, se muestra que su base de datos está actualmente disponible en la región Este de EE. UU.
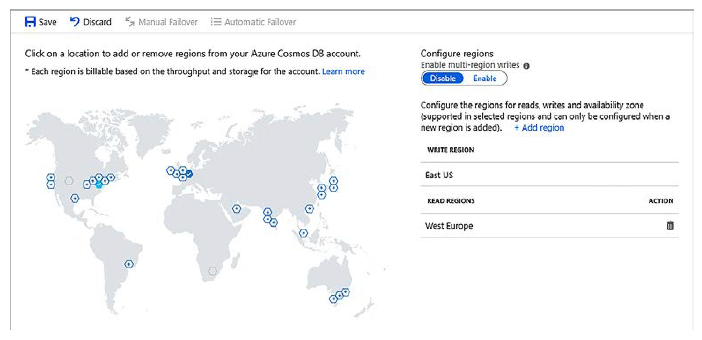
5 Elija Oeste de Europa y, a continuación, seleccione Guardar. Puede elegir cualquier región Azure que desee, pero para el laboratorio de fin del capítulo sus datos se deben replicar a Oeste de Europa. Replicar los datos en la región que seleccionó y que luego queden disponibles en línea para que sus aplicaciones los utilicen puede tomar un rato.
¡Vaya contando esos clics! Tres clics, ¿verdad? Seamos generosos y consideremos los dos primeros clics para seleccionar el grupo de recursos y la cuenta Cosmos DB. Por lo tanto, en no más de cinco clics y en cuestión de segundos, creó una instancia de réplica de su base de datos que permite a sus aplicaciones acceder a los datos desde la región más cercana. ¿Puede hacerlo con un clúster MySQL tradicional? Por favor, envíeme un tweet a @fouldsy si puede hacerlo rápidamente fuera de Cosmos DB.
Con su base de datos ahora distribuida globalmente, ¿necesita hacer varios cambios en el código para determinar a qué región de Cosmos DB se conectará? ¿Cómo puede mantener todas estas diferentes versiones de sus aplicaciones en la región Azure donde se ejecutan? Fácil, ¡deje que la plataforma Azure determine todo!
Acceso a los datos distribuidos globalmente
En su gran mayoría, la plataforma Azure determina la mejor ubicación para hablarle a su aplicación. Una aplicación normalmente necesita leer y escribir datos. Puede definir las directivas de conmutación por error para su base de datos de Cosmos DB que controla la ubicación de escritura principal. Esta ubicación de escritura actúa como el nodo central para garantizar que los datos se repliquen uniformemente en todas las regiones. Pero su aplicación web puede normalmente leer de varias regiones disponibles para acelerar las consultas y devolver datos al cliente. Todo esto es manejado por llamadas REST.
Veamos lo que sucede con la CLI de Azure cuando pide información sobre una base de datos de Cosmos DB. Este proceso es como una aplicación que hace una conexión a una base de datos, pero impide que se meta demasiado profundo en el código.
Pruébelo ahora
Utilice az cosmosdb show para encontrar información sobre su ubicación de lectura y escritura, como se muestra a continuación:
1 Abra Azure Portal en un navegador web y, a continuación, abra Cloud Shell.
2 Utilice az cosmosdb show para ver las ubicaciones de lectura y escritura de su base de datos de Cosmos DB.
Escriba el nombre del grupo de recursos y el nombre de la base de datos que creó en los ejercicios anteriores «Pruébelo ahora». En el ejemplo siguiente, el grupo de recursos azuremolchapter10 y el nombre de la base de datos de Cosmos DB es azuremol:
az cosmosdb show \
–resource-group azuremolchapter10 \
–name azuremol
Este comando devuelve una gran cantidad de resultados, así que examinemos las dos partes clave: leer ubicaciones y escribir ubicaciones. Este es un ejemplo del resultado de la sección readLocations:
«readLocations»:
[
{
«documentEndpoint»:»https://azuremol-eastus.documents.azure.com:443/»,
«failoverPriority»: 0,
«id»: «azuremol-eastus»,
«isZoneRedundant»: «false»,
«locationName»: «East US»,
«provisioningState»: «Succeeded»
},
{
«documentEndpoint»:
➥»https://azuremol-westeurope.documents.azure.com:443/»,
«failoverPriority»: 1,
«id»: «azuremol-westeurope»,
«isZoneRedundant»: «false»,
«locationName»: «West Europe»,
«provisioningState»: «Succeeded»
}
],
Cuando la aplicación hace una conexión a una base de datos de Cosmos DB, puede especificar una directiva de conexión. Si las bases de datos no son normalmente lo suyo, piense en una conexión Open Database Connectivity (ODBC) básica que puede crear en una máquina Windows. Normalmente, la cadena de conexión define un nombre de host, un nombre de base de datos, un puerto y credenciales. Cosmos DB no es diferente. Puede conectarse a Cosmos DB desde varios lenguajes, incluyendo .NET, Python, Node.js y Java. Los lenguajes pueden diferir, pero todos los SDK tienen un valor similar: descubrimiento del punto de conexión. La directiva de conexión tiene dos propiedades principales importantes:
– Descubrimiento automático del punto de conexión: el SDK lee todos los puntos de conexión disponibles de Cosmos DB y utiliza el orden de conmutación por error especificado. Este enfoque asegura que su aplicación siempre siga el orden que especifique en la base de datos. Por ejemplo, es posible que desee que todas las lecturas pasen por el Este de EE. UU. y solo utilizar Oeste de Europa cuando haya mantenimiento en la ubicación principal.
– Ubicaciones del punto de conexión preferido: usted especifica las ubicaciones que desee utilizar. Un ejemplo es si implementa su aplicación en Oeste de Europa y quiere asegurarse de que utiliza el punto de conexión de Oeste de Europa. Se va perdiendo un poco de flexibilidad a medida que se agregan o eliminan los puntos de conexión, pero se asegura de que el punto de conexión predeterminado esté cerca de la aplicación sin necesidad de un enrutamiento de red más avanzado para determinar esto.
Por lo general, la aplicación permite que el SDK de Cosmos DB se encargue de esta tarea. La aplicación no cambia la forma de manejar la conexión a la base de datos: solo sabe que puede conectarse a diferentes ubicaciones. Pero el SDK es lo que establece la conexión y utiliza este reconocimiento de la ubicación.
En la figura 10.10 se muestra un enfoque simplificado de cómo se utiliza este reconocimiento de ubicación entre la aplicación y el SDK. Una vez más, el lenguaje no importa, y el enfoque es el mismo: la figura usa el SDK de Python porque en ese lenguaje se han escrito un par de ejemplos. En este ejemplo, también se supone que está utilizando ubicaciones de punto de conexión automático.
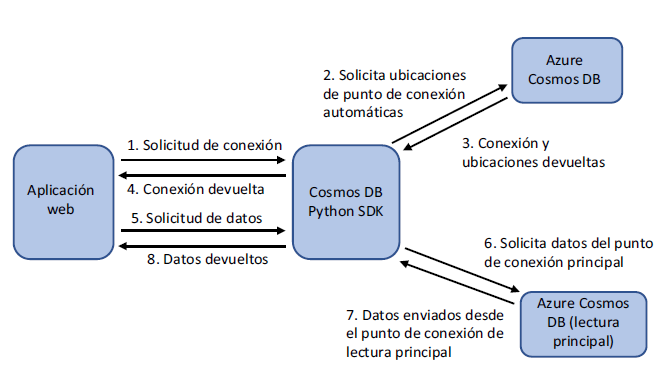
Los pasos ilustrados son los siguientes:
1 Su aplicación necesita establecer una conexión a una base de datos de Cosmos DB. En la directiva de conexión, habilita el descubrimiento automático de puntos de conexión. La aplicación utiliza el SDK de Cosmos DB para establecer una conexión con la base de datos.
2 El SDK de Cosmos DB hace una solicitud de conexión e indica que desea utilizar ubicaciones automáticas de los puntos de conexión.
3 Se devuelve una conexión basándose en las credenciales y la base de datos solicitadas.
4 El SDK devuelve un objeto de conexión para que utilice la aplicación. La información de ubicación se obtiene de la aplicación.
5 La aplicación solicita algunos datos de la base de datos de Cosmos DB. El SDK se utiliza de nuevo para consultar y obtener los datos.
6 El SDK utiliza la lista de puntos de conexión disponibles y hace la solicitud al primer punto de conexión disponible. A continuación, el SDK utiliza el punto de conexión para consultar los datos. Si el punto de conexión principal no está disponible, como durante mantenimiento, se utiliza automáticamente la siguiente ubicación del punto de conexión.
7 Cosmos DB devuelve los datos de la ubicación del punto de conexión.
8 El SDK pasa los datos de Cosmos DB de vuelta a la aplicación para analizarlos y mostrarlos según sea necesario.
Lo último que hay que ver en Cosmos DB son las claves de acceso, que permiten controlar quién puede acceder a los datos y qué permisos tiene. Las claves se pueden volver a generar, y al igual que con las contraseñas, puede implementar una directiva para realizar periódicamente este proceso de regeneración de claves. Para acceder a los datos distribuidos en Cosmos DB, necesita obtener sus claves. Azure Portal ofrece la forma de ver todas las claves y cadenas de conexión de su base de datos.
Pruébelo ahora
Complete los siguientes pasos para ver las claves de su cuenta Cosmos DB:
1 Busque y seleccione Grupos de recursos en la barra de navegación del lado izquierdo de Azure Portal.
2 Seleccione el grupo de recursos donde creó la base de datos de Cosmos DB, como azuremolchapter10.
3 Seleccione su cuenta de Cosmos DB en la lista de recursos.
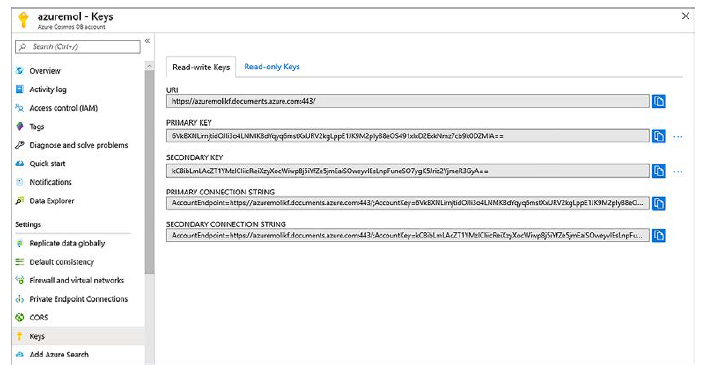
4 En el lado izquierdo, seleccione Claves.
5 Anote el identificador URI y la clave principal. Utilizará estos valores en el laboratorio de fin del capítulo.
En Cosmos DB se realizan muchas acciones para distribuir sus datos y permitir que sus aplicaciones lean y escriban desde las ubicaciones más apropiadas. Pero esa es precisamente la idea. El conocimiento de lo que hace el servicio Cosmos DB le ayuda a diseñar y planificar su aplicación, o a solucionar problemas si las aplicaciones no permiten que el SDK realice las operaciones de lectura y escritura necesarias. Sin embargo, no es necesario preocuparse sobre cómo y cuándo se realizan esas acciones; simplemente céntrese en sus aplicaciones y utilice los servicios Azure como Cosmos DB para proporcionar la funcionalidad y los beneficios de la nube que le permiten operar a escala global.
Laboratorio: Implementación de una aplicación web que usa Cosmos DB
En la sección anterior distribuyó globalmente su base de datos de Cosmos DB. Luego, repasamos un montón de teoría sobre cómo las aplicaciones web pueden leer desde ubicaciones de todo el mundo. Ahora probablemente quiera ver a Cosmos DB en acción, ¡así que esta es su oportunidad! En este laboratorio, se utiliza la aplicación web básica de los capítulos anteriores, pero esta vez, el menú de la pizza proviene de los elementos que agregó a la base de datos Cosmos DB en un ejercicio anterior de
«Pruébelo ahora»:
1 Cree una aplicación web en Azure Portal.
2 Como la pizzería ya no es una página HTML básica, elija Node LTS para el tiempo de ejecución que se ejecuta en Linux.
3 Cuando la aplicación web esté lista, cree un origen de implementación (repositorio Git local). Los pasos son los mismos que cuando creó uno en capítulos anteriores, como el capítulo 3, así que revise esos ejercicios si necesita refrescar la memoria.
4 Abra Cloud Shell. En capítulos anteriores, obtuvo una copia de los ejemplos de Azure de GitHub. Si no lo hizo, consiga una copia de la siguiente manera:
git clone https://github.com/fouldsy/azure-mol-samples-2nd-ed.git
5 Cámbielo al directorio que contiene el ejemplo de aplicación web de Cosmos DB.
cd ~/azure-mol-samples-2nd-ed/10/cosmosdbwebapp
6 Edite el archivo de configuración con la URL de base de datos y la clave de acceso que copió en el ejercicio anterior «Pruébelo ahora» para ver sus claves de Cosmos DB:
nano config.js
7 Escriba el archivo presionando Ctrl-O, y luego salga presionando Ctrl-X.
8 Agregue y confirme sus cambios en Git con el siguiente comando:
git init && git add . && git commit -m «Pizza»
9 Cree un vínculo al nuevo repositorio de Git en el espacio de ensayo con git remote add azure, seguido de su URL de implementación de Git.
10 Utilice git push azure master para insertar los cambios a su aplicación web.
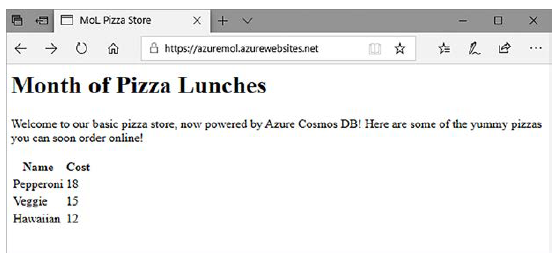
11 Seleccione la dirección URL de la aplicación web desde la ventana Información general de Azure Portal.
12 Abra esta URL en un navegador web para ver su pizzería, que ahora está basada en Cosmos DB.
Y bien aqui cerramos la entrada de hoy, gracias por asistir nos vemos en los proximos dias.