Las cuestiones arquitectónicas, como la alta disponibilidad y la escalabilidad, son algunos de los elementos de mayor prioridad para cualquier arquitecto. Este es un factor común en muchos proyectos y soluciones. Sin embargo, esto cobra aún más importancia a la hora de implementar aplicaciones en el cloud dada la complejidad asociada. En la mayoría de las ocasiones, la complejidad no proviene de la aplicación, sino de las opciones disponibles en cuanto a recursos similares en el cloud. Otra complejidad que surge del cloud es la disponibilidad constante de nuevas características. Estas nuevas características casi pueden hacer que las decisiones de un arquitecto resulten completamente redundantes posteriormente.
En este capítulo, vamos a analizar la perspectiva de un arquitecto en cuanto a la implementación de aplicaciones escalables y de alta disponibilidad en Azure. Azure es una plataforma madura que ofrece varias opciones para la implementación de soluciones de alta disponibilidad y escalabilidad en diversos niveles. Es vital para un arquitecto conocer estas soluciones, incluidas las diferencias entre ellas y los costes involucrados, y finalmente, estar en una posición para elegir una solución adecuada
que cumpla los requisitos de la mejor solución disponible. No hay una única solución
para todo, sino una adecuada para cada proyecto.
Una de las prioridades más importantes para las organizaciones es ejecutar aplicaciones
y sistemas que estén disponibles para su consumo por parte de los usuarios siempre
que lo necesiten. Los usuarios quieren que sus aplicaciones estén operativas y sean
funcionales además de seguir estando disponibles para sus clientes, incluso si se produce
algún evento desafortunado. La alta disponibilidad es el tema principal de este capítulo.
Mantener las luces encendidas es la metáfora común utilizada para la alta disponibilidad.
Lograr una alta disponibilidad para las aplicaciones no es una tarea sencilla y las
organizaciones deben invertir una cantidad considerable de tiempo, energía, recursos
y dinero para lograrlo. Además, sigue existiendo el riesgo de que la implementación
de una organización no produzca los resultados deseados. Azure proporciona numerosas
características de alta disponibilidad para máquinas virtuales (MV) y servicios de plataforma
como servicio (PaaS). En este capítulo, vamos a repasar las características arquitectónicas
y de diseño proporcionadas por Azure para garantizar la alta disponibilidad en la ejecución
de aplicaciones y servicios.
En este capítulo, abordaremos los siguientes temas:
- Alta disponibilidad
- Alta disponibilidad de Azure
- Consideraciones de la arquitectura para lograr una alta disponibilidad
- Escalabilidad
- Actualizaciones y mantenimiento
Alta disponibilidad
La alta disponibilidad constituye uno de los principales requisitos técnicos no funcionales
para cualquier servicio esencial para la empresa y su implementación. La alta disponibilidad
hace referencia a la característica de un servicio o aplicación que lo mantiene operativo
de manera continua, lo que consigue cumpliendo o incluso superando el acuerdo de nivel
de servicio (SLA) prometido. A los usuarios se les promete un SLA determinado basado
en el tipo de servicio. El servicio debe estar disponible para el consumo conforme a lo
establecido en el SLA. Por ejemplo, un SLA puede definir un 99 % de disponibilidad para
una aplicación durante todo el año. Esto significa que debe estar disponible para su consumo
por parte de los usuarios durante 361,35 días. Si no permanece disponible durante este
período, eso constituye una infracción del SLA. La mayoría de las aplicaciones críticas definen
su SLA de alta disponibilidad con un 99,999 % durante un año. Esto significa que la aplicación debe estar activa, operativa y disponible durante todo el año, pero solo puede estar inactiva
y no disponible durante 5,2 horas. Si el tiempo de inactividad supera esa cifra, podrá optar
a un crédito, que se calculará en función del porcentaje total de tiempo de actividad.
Es importante señalar aquí que la alta disponibilidad se define en términos de tiempo,
es decir, anualmente, mensualmente, semanalmente o una combinación de estos.
Un servicio o una aplicación está formado por múltiples componentes que se implementan
en diferentes niveles y capas. Además, un servicio o una aplicación se implementa
en un sistema operativo (SO) y se hospeda en una máquina física o virtual. Consume
servicios de red y almacenamiento para diversos propósitos. Podría incluso depender
de sistemas externos. Para que estos servicios o aplicaciones tengan una alta disponibilidad,
es importante que las redes, el almacenamiento, los SO, las máquinas físicas o virtuales
y cada componente de la aplicación esté diseñado con el SLA y la alta disponibilidad en
mente. Se debe utilizar un proceso de ciclo de vida de la aplicación definido para garantizar
la integración de la alta disponibilidad desde el principio de la planificación de la aplicación
hasta su introducción en las operaciones. Esto también implica la introducción de
redundancia. Deben incluirse recursos redundantes en la arquitectura de implementación
y de la aplicación en general para garantizar que, si un recurso falla, otro lo sustituye para
cubrir las necesidades del cliente.
Estos son algunos de los principales factores que afectan a la alta disponibilidad
de una aplicación:
- Mantenimiento planificado
- Mantenimiento no planificado
- Arquitectura de implementación de aplicaciones
En las secciones siguientes, vamos a analizar cada uno de estos factores. Echemos un vistazo
más de cerca a cómo se garantiza la alta disponibilidad para las implementaciones en Azure.
Alta disponibilidad de Azure
Resulta complicado lograr una alta disponibilidad que cumpla con los exigentes requisitos
del SLA. Azure proporciona numerosas características que permiten la alta disponibilidad
para aplicaciones, desde el SO host e invitado hasta las aplicaciones que utilizan su PaaS.
Los arquitectos pueden utilizar estas características para obtener una alta disponibilidad
en sus aplicaciones a través de la configuración, en lugar de crear estas características
desde cero o depender de herramientas de terceros.
En esta sección, vamos a explicar las características y las capacidades que proporciona
Azure para hacer que las aplicaciones tengan una alta disponibilidad. Antes de adentrarnos
en los detalles arquitectónicos y de configuración, es importante entender conceptos
relacionados con la alta disponibilidad de Azure.
Conceptos
Los conceptos fundamentales proporcionados por Azure para lograr la alta disponibilidad
son los siguientes:
- Conjuntos de disponibilidad
- Dominio de error
- Dominio de actualización
- Zonas de disponibilidad
Como sabes, es muy importante que diseñemos soluciones para que tengan una alta
disponibilidad. Las cargas de trabajo pueden ser críticas y requerir una arquitectura
de alta disponibilidad. Ahora vamos a examinar más de cerca cada uno de los conceptos
de alta disponibilidad en Azure. Empecemos con los conjuntos de disponibilidad.
Conjuntos de disponibilidad
La alta disponibilidad en Azure se logra principalmente a través de la redundancia.
La redundancia significa que hay más de una instancia de un recurso del mismo tipo que
asume el control en caso de que falle un recurso principal. Sin embargo, el simple hecho
de tener más recursos similares no los hace altamente disponibles. Por ejemplo, podría haber
varias MV aprovisionadas dentro de una suscripción, pero el mero hecho de tener varias MV
no las hace altamente disponibles. Azure proporciona un recurso conocido como conjunto
de disponibilidad y al tener varias máquinas virtuales asociadas con él las hace altamente
disponibles. Se debe hospedar un mínimo de dos MV dentro del conjunto de disponibilidad
para que estén altamente disponibles. Todas las MV del conjunto de disponibilidad se vuelven
altamente disponibles al ubicarse en soportes físicos independientes en el centro de datos de
Azure. Durante las actualizaciones, estas MV se actualizan de una en una, en lugar de todas
a la vez. Los conjuntos de disponibilidad proporcionan un dominio de error y un dominio de
actualización para lograrlo, aspecto que vamos a tratar más a fondo en la sección siguiente.
En resumen, los conjuntos de disponibilidad proporcionan redundancia en un nivel de centro
de datos similar al almacenamiento con redundancia local.
Es importante tener en cuenta que los conjuntos de disponibilidad proporcionan alta
disponibilidad dentro de un centro de datos. Si todo un centro de datos queda inactivo,
la disponibilidad de la aplicación se verá afectada. Para garantizar que las aplicaciones
siguen estando disponibles aunque un centro de datos esté inactivo, Azure ha introducido
una nueva característica conocida como zonas de disponibilidad, que explicaremos en breve.
Si recuerdas la lista de conceptos fundamentales, el siguiente de la lista es el dominio de
error. A menudo, el dominio de error se indica mediante el acrónimo FD. En la siguiente
sección, analizaremos qué es el FD y cómo es relevante al diseñar soluciones de alta
disponibilidad.
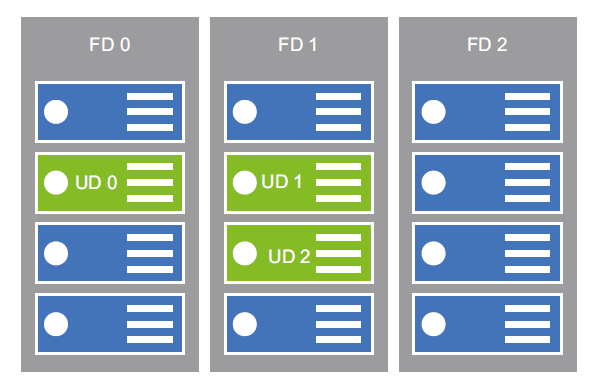
Dominio de error
Los dominios de error (FD) representan un grupo de máquinas virtuales que comparten
una fuente de alimentación y un conmutador de red. Cuando se aprovisiona y se
asigna una MV a un conjunto de disponibilidad, este se hospeda dentro de un FD. Cada
conjunto de disponibilidad tiene dos o tres FD predeterminados en función de la región
de Azure. Algunas regiones proporcionan dos, mientras que otras proporcionan tres FD
en un conjunto de disponibilidad. Los usuarios no pueden configurar los FD.
Cuando se crean varias MV, se colocan en FD diferentes. Si el número de MV es mayor que
la cantidad de FD, las MV adicionales se colocan en los FD existentes. Por ejemplo, si hay
cinco MV, habrá FD hospedados en más de una MV.
Los FD están relacionados con soportes físicos del centro de datos de Azure. Los FD
proporcionan una alta disponibilidad en situaciones de tiempo de inactividad no planificado
como consecuencia de fallos de hardware, de alimentación y de red. Puesto que cada MV se
coloca en un bastidor diferente con hardware diferente, así como una fuente de alimentación
y una red diferentes, otras MV continúan ejecutándose si un soporte se desactiva.
El siguiente de la lista es el dominio de actualización.
Dominio de actualización
Un FD supervisa el tiempo de inactividad no planificado, mientras que un dominio de
actualización gestiona el tiempo de inactividad del mantenimiento planificado. A cada
MV se le asigna también un dominio de actualización y todas las MV dentro de ese dominio
de actualización se reiniciarán juntas. Puede haber hasta 20 dominios de actualización en
un único conjunto de disponibilidad. Los usuarios no pueden configurar los dominios de
actualización. Cuando se crean varias MV, estas se colocan en dominios de actualización
diferentes. Si se aprovisionan más de 20 MV en un conjunto de disponibilidad, estas se
colocan con el método round-robin en estos dominios de actualización. Los dominios
de actualización se encargan del mantenimiento planificado. En Service Health en Azure
Portal, puedes comprobar los detalles de mantenimiento planificados y establecer alertas.
En la siguiente sección, explicaremos las zonas de disponibilidad.
Zonas de disponibilidad
Este es un concepto relativamente nuevo introducido por Azure y es muy similar a la
redundancia de zona de las cuentas de almacenamiento. Las zonas de disponibilidad
proporcionan alta disponibilidad dentro de una región mediante la colocación de instancias
de MV en centros de datos independientes dentro de la región. Las zonas de disponibilidad
son aplicables a muchos recursos de Azure, incluidos MV, discos administrados, conjuntos
de escalado de MV y equilibradores de carga. La lista completa de recursos admitidos por
zonas de disponibilidad se encuentra en https://docs.microsoft.com/azure/availabilityzones/
az-overview#services-that-support-availability-zones. La imposibilidad de
configurar la disponibilidad entre zonas ha sido una brecha en Azure durante mucho
tiempo que pudo corregirse finalmente con la introducción de las zonas de disponibilidad.
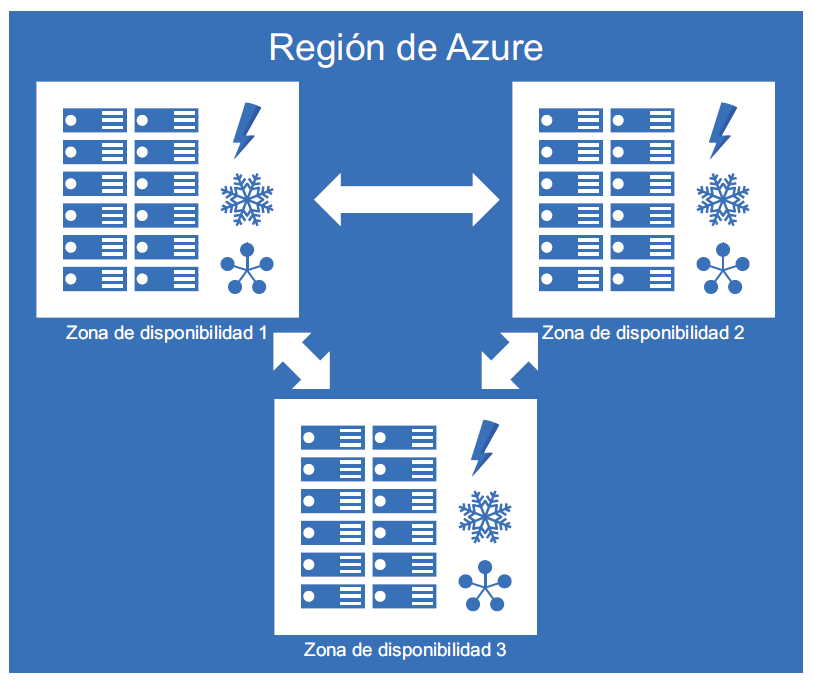
Cada región de Azure consta de varios centros de datos equipados con alimentación,
refrigeración y redes independientes. Algunas regiones tienen más centros de datos
y otras tienen menos. Estos centros de datos dentro de la región se conocen como zonas.
Para garantizar la resistencia, hay un mínimo de tres zonas separadas en todas las regiones
habilitadas. La implementación de MV en una zona de disponibilidad garantiza que estas
MV se encuentren en diferentes centros de datos y en diferentes soportes y redes. Estos
centros de datos de una región están relacionados con redes de alta velocidad y no hay
retraso en la comunicación entre estas MV. En la Figura 2.1 se muestra cómo se configuran
las zonas de disponibilidad en una región:
Puedes encontrar más información sobre las zonas de disponibilidad en https://docs.
microsoft.com/azure/availability-zones/az-overview.
Los servicios con redundancia de zona replican tus aplicaciones y datos en varias zonas
de disponibilidad para protegerte de puntos únicos de error.
Si una aplicación necesita mayor disponibilidad y deseas garantizar su disponibilidad aunque
toda una región de Azure esté inactiva, el siguiente nivel de la escala de disponibilidad es la
característica Traffic Manager, que abordaremos más adelante en este capítulo. Ahora vamos
a seguir con la descripción del modo en que Azure equilibra la carga de las máquinas virtuales.
Equilibrio de carga
El equilibrio de carga, como su nombre indica, se refiere al proceso de equilibrar una carga entre
MV y aplicaciones. Con una MV, no se requiere un equilibrador de carga porque toda la carga
está en una sola MV y no hay ninguna otra MV para compartirla. Sin embargo, con varias MV
con la misma aplicación y servicio, es posible distribuir la carga entre ellas a través del equilibrio
de carga. Azure proporciona unos cuantos recursos para habilitar el equilibrio de carga:
- Equilibradores de carga: el equilibrador de carga de Azure ayuda a diseñar soluciones
con alta disponibilidad. Dentro de la pila del Protocolo de control de transmisión (TCP),
hay un equilibrador de carga de nivel de transporte de capa 4. Se trata de un equilibrador
de carga de capa 4 que distribuye el tráfico entrante entre instancias de servicios en
buen estado definidos en un conjunto de carga equilibrada. Los equilibradores de
carga de capa 4 trabajan en el nivel de transporte y tienen información de nivel de red,
como una dirección IP y un puerto, para decidir el destino de la solicitud entrante.
Explicaremos los equilibradores de carga detalladamente más adelante en este capítulo. - Puertas de enlace de aplicaciones: Azure Application Gateway ofrece una alta
disponibilidad a tus aplicaciones. Son equilibradores de carga de capa 7 que distribuyen el
tráfico entrante entre instancias de servicios en buen estado. Los equilibradores de carga
de capa 7 pueden trabajar en el nivel de aplicación y tienen la información de nivel de
aplicación, como cookies, HTTP, HTTPS y sesiones para la solicitud entrante. Las puertas
de enlace de aplicaciones se describen detalladamente más adelante en este capítulo.
Las puertas de enlace de aplicaciones también se utilizan para la implementación
de Azure Kubernetes Service, específicamente para escenarios en los que el tráfico
de entrada de Internet se debe enrutar a los servicios de Kubernetes del clúster. - Azure Front Door: Azure Front Door es muy similar a las puertas de enlace de
aplicaciones; sin embargo, no funciona en el nivel de la región o del centro de datos.
En su lugar, ayuda en el enrutamiento de solicitudes en todas las regiones del mundo.
Tiene el mismo conjunto de características que el proporcionado por las puertas
de enlace de aplicaciones, pero de manera global. También proporciona un firewall
de aplicaciones web para el filtrado de solicitudes y proporciona otra protección
relacionada con la seguridad. Proporciona afinidad de sesión, terminación TLS
y enrutamiento basado en URL como algunas de sus características. - Traffic Manager: Traffic Manager ayuda en el enrutamiento de solicitudes de manera
global en varias regiones en función del estado y la disponibilidad de los puntos de
conexión regionales. Permite hacer esto mediante el uso de entradas de redirección
de DNS. Es muy resistente y además no afecta en modo alguno al servicio durante
los fallos de la región.
Puesto que hemos explorado los métodos y servicios que se pueden utilizar para lograr el
equilibrio de carga, prosigamos y veamos cómo hacer que las MV sean altamente disponibles.
Alta disponibilidad de MV
Las MV proporcionan capacidades de computación. Proporcionan potencia de
procesamiento y hosting para aplicaciones y servicios. Si una aplicación se implementa
en una sola MV y la máquina deja de funcionar, la aplicación dejará de estar disponible.
Si la aplicación consta de varios niveles y cada nivel se implementa en su propia instancia
individual de una MV, incluso el bloqueo de una instancia única de MV puede provocar que
la aplicación no esté disponible. Azure intenta hacer que incluso las instancias individuales
de MV estén altamente disponibles durante el 99,9 % del tiempo, especialmente si
estas MV de una instancia única usan almacenamiento premium para sus discos. Azure
proporciona un SLA más elevado para las MV que están agrupadas en un conjunto de
disponibilidad. Proporciona un SLA del 99,95 % para las MV que forman parte de un
conjunto de disponibilidad con dos o más MV. El SLA es del 99,99 % si las MV se colocan
en zonas de disponibilidad. En la siguiente sección, explicaremos la alta disponibilidad de
los recursos de computación.
Alta disponibilidad de computación
Las aplicaciones que exigen alta disponibilidad deben implementarse en múltiples MV en
el mismo conjunto de disponibilidad. Si las aplicaciones constan de varios niveles, cada nivel
debe tener un grupo de MV en su conjunto de disponibilidad dedicado. En definitiva, si hay
tres niveles de una aplicación, debe haber tres conjuntos de disponibilidad y un mínimo de
seis MV (dos en cada conjunto de disponibilidad) para que toda la aplicación sea altamente
disponible.
Así pues, ¿cómo proporciona Azure un SLA y alta disponibilidad a las MV de un conjunto
de disponibilidad con múltiples MV en cada conjunto de disponibilidad? Esta es la pregunta
que podría venirte a la mente.
Aquí, entra en juego el uso de conceptos que hemos planteado antes, es decir, los dominios de
error y de actualización. Cuando Azure ve varias MV en un conjunto de disponibilidad, coloca
esas MV en un FD independiente. En otras palabras, estas MV se colocan en soportes físicos
separados en lugar de en el mismo soporte. Esto garantiza que al menos una MV siga disponible
incluso si se produce un error de alimentación, de hardware o de soporte. Hay dos o tres FD
en un conjunto de disponibilidad y, en función del número de MV que haya en un conjunto
de disponibilidad, las MV se colocan en FD separados o se repiten con el método round-robin.
Esto garantiza que la alta disponibilidad no se vea afectada debido a un error de soporte.
Azure también coloca estas MV en un dominio de actualización independiente. Es decir,
Azure etiqueta estas MV internamente de tal forma que dichas MV se revisan y se actualizan
una tras otra, de manera que ningún reinicio de un dominio de actualización afecte a la
disponibilidad de la aplicación. Esto garantiza que la alta disponibilidad no se vea afectada
debido al mantenimiento de la MV y el host. Es importante tener en cuenta que Azure no
es responsable del mantenimiento de las aplicaciones y del nivel del sistema operativo.
Con la colocación de MV en dominios de error y de actualización independientes,
Azure garantiza que no dejen de funcionar todas las MV al mismo tiempo y que estén
activas y disponibles para dar servicios a las solicitudes, incluso aunque se estén
sometiendo a tareas de mantenimiento o afrontando problemas de inactividad física.
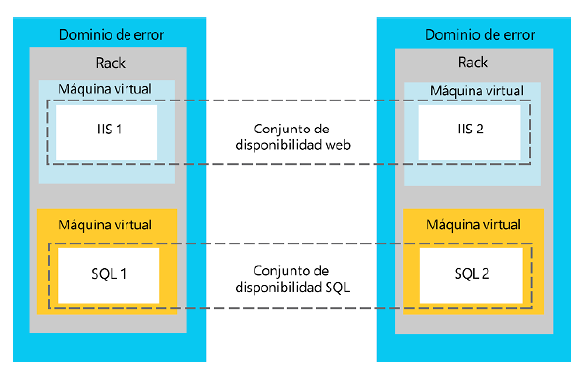
En la Figura 2.2 se muestran cuatro MV (dos tienen Internet Information Services (IIS)
y las otras dos tienen instalado SQL Server). Tanto las MV de IIS como las de SQL
forman parte de conjuntos de disponibilidad. Las MV de IIS y SQL se encuentran
en FD independientes y en soportes diferentes del centro de datos. También están
en dominios de actualización independientes.
En la Figura 2.3 se muestra la relación entre los dominios de error y de actualización:
Hasta ahora, hemos hablado de cómo lograr una alta disponibilidad para los recursos
de computación. En la siguiente sección, aprenderás cómo se puede implementar la alta
disponibilidad para PaaS.
Plataformas de alta disponibilidad
Azure ha proporcionado numerosas características nuevas para garantizar la alta
disponibilidad para PaaS. A continuación, se indican algunas de ellas:
- Contenedores en servicios de aplicaciones
- Grupos de instancias de contenedores de Azure
- Azure Kubernetes Service
- Otros orquestadores de contenedores, como DC/OS y Swarm
Otra plataforma importante que aporta alta disponibilidad es Service Fabric. Tanto Service
Fabric como los orquestadores de contenedores que incluyen Kubernetes garantizan que
el número deseado de instancias de aplicación siempre esté en funcionamiento en un entorno.
Esto significa que aunque una de las instancias esté inactiva en el entorno, el orquestador
lo sabrá gracias a la función de supervisión activa e iniciará una nueva instancia en un nodo
diferente, manteniendo así el número de instancias idóneo y deseado. Puede hacer esto sin
necesidad de que el administrador intervenga manualmente ni de forma automatizada.
Aunque Service Fabric permite que cualquier tipo de aplicación sea de alta disponibilidad,
los orquestadores como Kubernetes, DC/OS y Swarm son específicos de los contenedores.
Además, es importante comprender que estas plataformas proporcionan características
que ayudan en las actualizaciones continuas, en lugar de realizar grandes actualizaciones
que podrían afectar a la disponibilidad de la aplicación.
Cuando hemos hablado de alta disponibilidad para MV, hemos analizado brevemente qué
es el equilibrio de carga. Vamos a describir con mayor profundidad este concepto para
entender mejor cómo funciona en Azure.
Equilibradores de carga en Azure
Azure proporciona dos recursos que tienen la funcionalidad de un equilibrador de carga.
Proporciona un equilibrador de carga de capa 4 que funciona en la capa de transporte de la
pila OSI TCP, así como un equilibrador de carga de capa 7 (puerta de enlace de aplicaciones)
que funciona en los niveles de aplicaciones y sesiones.
Aunque tanto las puertas de enlace de aplicaciones como los equilibradores de carga
ofrecen características básicas de equilibrado de una carga, cumplen funciones distintas.
Hay una serie de casos prácticos en los que tiene más sentido implementar una puerta
de enlace de aplicaciones que un equilibrador de carga.
Una puerta de enlace de aplicaciones proporciona las siguientes funciones que no están
disponibles con los equilibradores de carga de Azure:
- Firewall de aplicaciones web: es un firewall adicional sobre el firewall del SO
que proporciona la capacidad de comprobar los mensajes entrantes. Esto ayuda
a identificar y evitar los frecuentes ataques basados en web, como los ataques
por inyección de código SQL, ataques de scripts de sitios y secuestros de sesión. - Afinidad de sesión basada en cookies: los equilibradores de carga distribuyen el tráfico
entrante hacia las instancias de servicios que están en buen estado y relativamente
libres. Una solicitud puede ser atendida por cualquier instancia de servicio. Sin embargo,
hay aplicaciones que necesitan características avanzadas en las que todas las solicitudes
posteriores a la primera solicitud deben ser procesadas por la misma instancia de servicio.
Esto se conoce como afinidad de sesión basada en cookies. Una puerta de enlace
de aplicaciones proporciona afinidad de sesión basada en cookies para mantener una
sesión de usuario en la misma instancia de servicio mediante el uso de cookies. - Descarga de capa de sockets seguros (SSL): el cifrado y el descifrado de los datos
de solicitud y respuesta se realizan mediante SSL y, por lo general, se trata de
una operación costosa. Lo ideal es que los servidores web inviertan sus recursos
en procesar y proporcionar servicio a solicitudes en lugar de dedicarlos a cifrar
y descifrar el tráfico. La descarga de SSL ayuda a transferir este proceso de cifrado
desde el servidor web hasta el equilibrador de carga, lo que proporciona más recursos
a los servidores web que prestan servicio a los usuarios. La solicitud del usuario se
cifra pero se descifra en la puerta de enlace de aplicaciones en lugar de en el servidor
web. La solicitud de la puerta de enlace de aplicaciones al servidor web no está cifrada. - SSL de extremo a extremo: aunque la descarga de SSL es una buena característica
para determinadas aplicaciones, hay ciertas aplicaciones de seguridad críticas que
requieren un cifrado y descifrado SSL completo, aunque el tráfico pase a través
de equilibradores de carga. Una puerta de enlace de aplicaciones también puede
configurarse para un cifrado SSL de extremo a extremo. - Enrutamiento de contenido basado en URL: las puertas de enlace de aplicaciones
también son útiles para redirigir el tráfico hacia diferentes servidores en función
del contenido de la URL de las solicitudes entrantes. Esto ayuda a hospedar varios
servicios junto con otras aplicaciones.
Equilibradores de carga de Azure
Un equilibrador de carga de Azure distribuye el tráfico entrante teniendo en cuenta la
información de nivel de transporte que está a su disposición. Depende de las siguientes
características:
- Dirección IP de origen
- Dirección IP de destino
- Número de puerto de origen
- Número de puerto de destino
- Tipo de protocolo: TCP o HTTP
Un equilibrador de carga de Azure puede ser un equilibrador de carga privado o un
equilibrador de carga público. Se puede utilizar un equilibrador de carga privado para
distribuir el tráfico dentro de la red interna. Como es interno, no habrá ninguna IP pública
asignada y no se puede acceder a ellas desde Internet. Un equilibrador de carga público
tiene una IP pública externa conectada y se puede acceder a ella a través de Internet.
En la Figura 2.4, puedes ver cómo se incorporan equilibradores de carga internos (privados)
y públicos en una única solución para gestionar tráfico interno y externo, respectivamente:
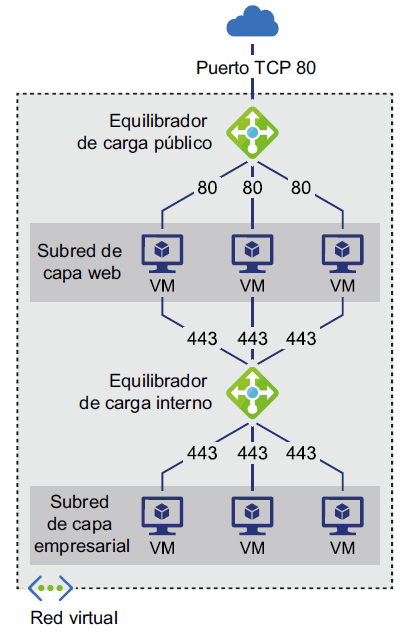
En la Figura 2.4, puedes ver que los usuarios externos acceden a las MV a través del
equilibrador de carga público y, a continuación, el tráfico procedente de la máquina
virtual se distribuye por otro conjunto de MV mediante un equilibrador de carga interno.
Hemos comparado los equilibradores de carga de Azure con las puertas de enlace
de aplicaciones. En la siguiente sección, explicaremos en detalle las puertas de enlace
de aplicaciones.
Azure Application Gateway
Un equilibrador de carga de Azure nos ayuda a habilitar soluciones en la infraestructura.
Sin embargo, hay ocasiones en las que el uso de un equilibrador de carga requiere servicios
y características avanzados. Estos servicios avanzados incluyen terminación SSL, sesiones
temporales, seguridad avanzada, etc. Una Azure Application Gateway proporciona estas
características adicionales; Azure Application Gateway es un equilibrador de carga de
capa 7 que funciona con la aplicación y la carga de sesión en una pila OSI TCP.
Las puertas de enlace de aplicaciones tienen más información que los equilibradores de
carga de Azure para tomar decisiones sobre el enrutamiento de las solicitudes y el equilibrio
de carga entre servidores. Azure gestiona las puertas de enlace de aplicaciones, que son
altamente disponibles.
Una puerta de enlace de aplicaciones se encuentra entre los usuarios y las MV, como
se muestra en la Figura 2.5:
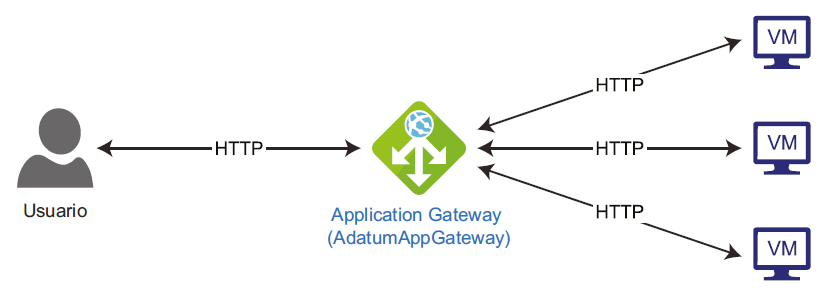
Las puertas de enlace de aplicaciones son un servicio administrado. Utilizan el enrutamiento
de solicitud de aplicaciones (ARR) para enrutar las solicitudes a diferentes servicios y puntos
de conexión. Para crear una puerta de enlace de aplicaciones se requiere una dirección IP
privada o pública. La puerta de enlace de aplicaciones enruta el tráfico HTTP/HTTPS a los
puntos de conexión configurados.
Una puerta de enlace de aplicaciones es similar a un equilibrador de carga de Azure en lo
que respecta a la configuración, aunque posee características y diseños adicionales. Las
puertas de enlace de aplicaciones se pueden configurar con una dirección IP de front-end,
un certificado, una configuración de puerto, un grupo de back-end, afinidad de sesión
e información de protocolo.
Otro servicio que hemos descrito en relación con la alta disponibilidad de las MV es Azure
Traffic Manager. Profundizaremos más sobre este servicio en la siguiente sección.
Azure Traffic Manager
Ahora que hemos explicado en detalle los equilibradores de carga y las puertas de enlace de
aplicaciones de Azure, vamos a pasar a profundizar en Traffic Manager. Los equilibradores
de carga y las puertas de enlace de aplicaciones de Azure son recursos indispensables para
la alta disponibilidad en un centro de datos y una región. Sin embargo, para lograr la alta
disponibilidad en todas las regiones y centros de datos, se necesita otro recurso y Traffic
Manager nos ayuda en este sentido.
Traffic Manager nos ayuda a crear soluciones de alta disponibilidad que abarcan múltiples
ubicaciones geográficas, regiones y centros de datos. Traffic Manager no es similar a los
equilibradores de carga. Utiliza el servicio de nombres de dominio (DNS) para redirigir las
solicitudes a un punto de conexión apropiado determinado por el estado y la configuración
del punto de conexión. Traffic Manager no es un proxy ni una puerta de enlace, y no ve el
tráfico que pasa entre el cliente y el servicio. Simplemente redirige las solicitudes basándose
en los puntos de conexión más apropiados.
Azure Traffic Manager ayuda a controlar el tráfico que se distribuye entre los puntos
de conexión de la aplicación. Se puede calificar como punto de conexión cualquier servicio
de conexión a Internet hospedado dentro o fuera de Azure.
Los puntos de conexión son URL públicas accesibles expuestas a Internet. Las aplicaciones
se aprovisionan en múltiples ubicaciones geográficas y regiones de Azure. Las aplicaciones
implementadas en cada región tienen un punto de conexión único denominado DNS
CNAME. Estos puntos de conexión se asignan al punto de conexión de Traffic Manager.
Cuando se aprovisiona una instancia de Traffic Manager, esta obtiene un punto de conexión
predeterminado con una extensión URL .trafficmanager.net.
Cuando llega una solicitud a la URL de Traffic Manager, encuentra el punto de conexión
más adecuado en su lista y le redirige la solicitud. En resumen, Azure Traffic Manager
actúa como un DNS global para identificar la región que atenderá la solicitud.
Sin embargo, ¿cómo sabe Traffic Manager qué puntos de conexión utilizar y hacia cuáles
redirigir las solicitudes de cliente? Hay dos aspectos que Traffic Manager tiene en cuenta
para determinar la región y el punto de conexión más apropiados.
En primer lugar, Traffic Manager supervisa activamente el estado de todos los puntos de
conexión. Puede supervisar el estado de las MV, los servicios en el cloud y los servicios de
aplicación. Si determina que el estado de una aplicación implementada en una región no es
adecuado para redirigir el tráfico hacia ella, redirige las solicitudes a un punto de conexión
en buen estado.
En segundo lugar, Traffic Manager puede configurarse con información de enrutamiento.
Existen seis métodos de enrutamiento de tráfico en Traffic Manager, que son los siguientes:
- Prioridad: debe utilizarse cuando todo el tráfico debe ir a un punto de conexión
predeterminado y existen copias de seguridad en caso de que los puntos de conexión
principales no estén disponibles. - Ponderado: debe utilizarse para distribuir el tráfico entre todos los puntos
de conexión de manera uniforme o según pesos definidos. - Rendimiento: debe utilizarse para puntos de conexión en diferentes regiones
y los usuarios deben redirigirse hasta el punto de conexión más cercano según
su ubicación. Esto repercute de forma directa en la latencia de red. - Geográfico: debe usarse para redirigir a los usuarios a un punto de conexión
(Azure, externo o anidado) según la ubicación geográfica más cercana. Esto puede
ayudar a respetar el cumplimiento normativo relacionado con la protección de datos,
la localización y la recopilación de tráfico basada en la región. - Subred: este es un nuevo método de enrutamiento y ayuda a proporcionar a los
clientes diferentes puntos de conexión en función de sus direcciones IP. En este
método, se asigna un intervalo de direcciones IP a cada punto de conexión. Estos
rangos de direcciones IP se asignan a la dirección IP del cliente para determinar un
punto de conexión de devolución adecuado. Este método de enrutamiento permite
proporcionar diferentes contenidos a diferentes personas en función de su dirección
IP de origen. - Multivalor: también es un nuevo método agregado en Azure. En este método, se
devuelven varios puntos de conexión al cliente y se puede utilizar cualquiera de ellos.
Esto garantiza que si un punto de conexión no está en buen estado, se pueden usar
otros puntos de conexión en su lugar. Esto ayuda a aumentar la disponibilidad general
de la solución.
Hay que tener en cuenta que una vez que Traffic Manager determina un punto de conexión
en buen estado válido, los clientes se conectan directamente a la aplicación. Ahora pasemos
a describir las capacidades de Azure en el enrutamiento global de las solicitudes de los
usuarios.
En la siguiente sección describiremos otro servicio, denominado Azure Front Door. Este
servicio es como Azure Application Gateway; sin embargo, hay una pequeña diferencia que
hace que este servicio sea distinto. Avancemos y descubramos más sobre Azure Front Door.
Azure Front Door
Azure Front Door es la oferta más reciente de Azure que ayuda a enrutar las solicitudes
a servicios en un nivel global en lugar de un nivel de región local o de centro de datos,
como en el caso de Azure Application Gateway y los equilibradores de carga. Azure Front
Door es como una puerta de enlace de aplicaciones, pero se diferencia en el ámbito.
Es un equilibrador de carga de capa 7 que ayuda en el enrutamiento de solicitudes al
punto de conexión de servicio más cercano y con mejor rendimiento implementado en
varias regiones. Proporciona características como terminación TLS, afinidad de sesión,
enrutamiento basado en URL y varios hosting de sitios, junto con un firewall de aplicaciones
web. Es similar a Traffic Manager ya que, de forma predeterminada, es resistente a errores
de toda la región y proporciona capacidades de enrutamiento. También realiza sondeos
de estado de los puntos de conexión periódicamente para garantizar que las solicitudes
se enruten únicamente a puntos de conexión en buen estado.
Proporciona cuatro métodos de enrutamiento diferentes:
- Latencia: las solicitudes se enrutarán a puntos de conexión que tengan el menor
tiempo de latencia de extremo a extremo. - Prioridad: las solicitudes se enrutarán a un punto de conexión principal y a un punto
de conexión secundario en caso de error del principal. - Ponderado: las solicitudes se enrutarán en función de los pesos asignados a los puntos
de conexión. - Afinidad de sesión: las solicitudes de una sesión terminarán con el mismo punto
de conexión para utilizar los datos de sesión de solicitudes anteriores. La solicitud
original puede terminar con cualquier punto de conexión disponible.
Las implementaciones que buscan resistencia en el nivel global deben incluir Azure Front
Door en su arquitectura, junto con puertas de enlace de aplicaciones y equilibradores
de carga. En la siguiente sección, verás algunas de las consideraciones arquitectónicas
que debes tener en cuenta al diseñar soluciones de alta disponibilidad.
Consideraciones de la arquitectura para lograr una alta disponibilidad
Azure proporciona alta disponibilidad mediante distintas formas y en varios niveles. La alta
disponibilidad puede estar en el nivel de centro de datos, en el nivel de región o incluso
en Azure. En esta sección, estudiaremos algunas de las arquitecturas de alta disponibilidad.
Alta disponibilidad en las regiones de Azure
La arquitectura que se presenta en la Figura 2.6 muestra la implementación de alta
disponibilidad en una única región de Azure. La alta disponibilidad está diseñada en el nivel
de recursos individuales. En esta arquitectura, hay múltiples MV en cada nivel conectadas
a través de una puerta de enlace de aplicaciones o un equilibrador de carga, que forman
cada uno parte de un conjunto de disponibilidad. Cada nivel está asociado con un conjunto
de disponibilidad. Estas MV se colocan en dominios de error y actualización diferentes.
Mientras los servidores web se conectan a las puertas de enlace de aplicaciones, el resto de
los niveles, como los de aplicación y base de datos, tienen equilibradores de carga internos:
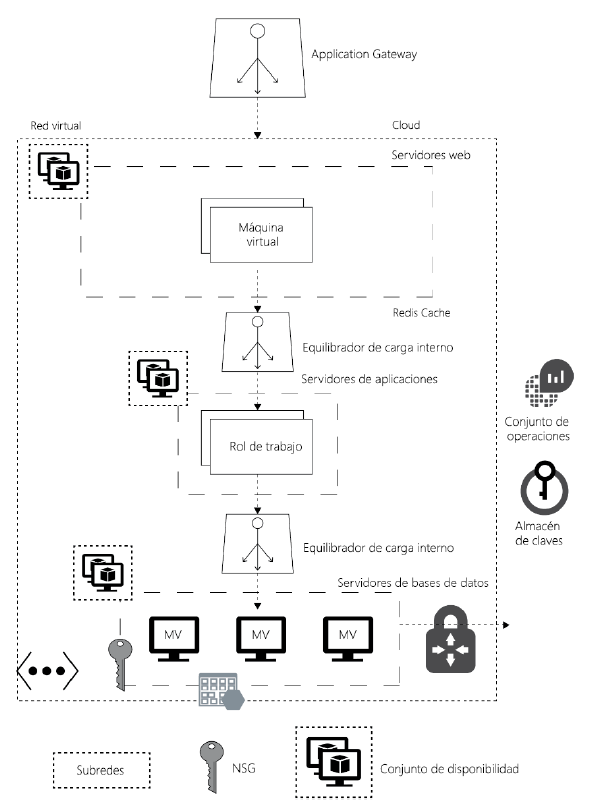
Ahora que ya sabes cómo diseñar soluciones de alta disponibilidad en la misma región,
vamos a analizar cómo se puede diseñar una arquitectura similar, pero repartida entre
varias regiones de Azure.
Alta disponibilidad entre regiones de Azure
Esta arquitectura muestra implementaciones similares en dos regiones diferentes
de Azure. Como se muestra en la Figura 2.7, ambas regiones tienen los mismos recursos
implementados. La alta disponibilidad está diseñada en el nivel de recursos individuales
dentro de estas regiones. Hay varias MV en cada nivel conectadas a través de equilibradores
de carga, que forman parte de un conjunto de disponibilidad. Estas MV se colocan
en dominios de error y actualización diferentes. Mientras los servidores web se conectan
a equilibradores de carga externos, el resto de los niveles, como los de aplicación y base
de datos, tiene equilibradores de carga internos. Cabe señalar que los equilibradores de
carga de la aplicación se pueden utilizar para los niveles de servidores web y aplicaciones
(en lugar de los equilibradores de carga de Azure) si se requiriesen servicios avanzados,
como afinidad de sesión, terminación SSL, seguridad avanzada con un firewall de
aplicaciones web (WAF) y enrutamiento basado en ruta. Las bases de datos de ambas
regiones están conectadas entre sí mediante emparejamiento de red virtual y puertas
de enlace. Esto es útil para la configuración del trasvase de registros, SQL Server Always
On y otras técnicas de sincronización de datos.
Los puntos de conexión de los equilibradores de carga de ambas regiones se utilizan
para configurar puntos de conexión de Traffic Manager y el tráfico se enruta en función
del método de equilibrio de carga de prioridad. Traffic Manager ayuda al enrutamiento
de todas las solicitudes de la región del este de EE. UU. y, después de la conmutación
por error, a Europa Occidental en caso de que la anterior región no esté disponible.
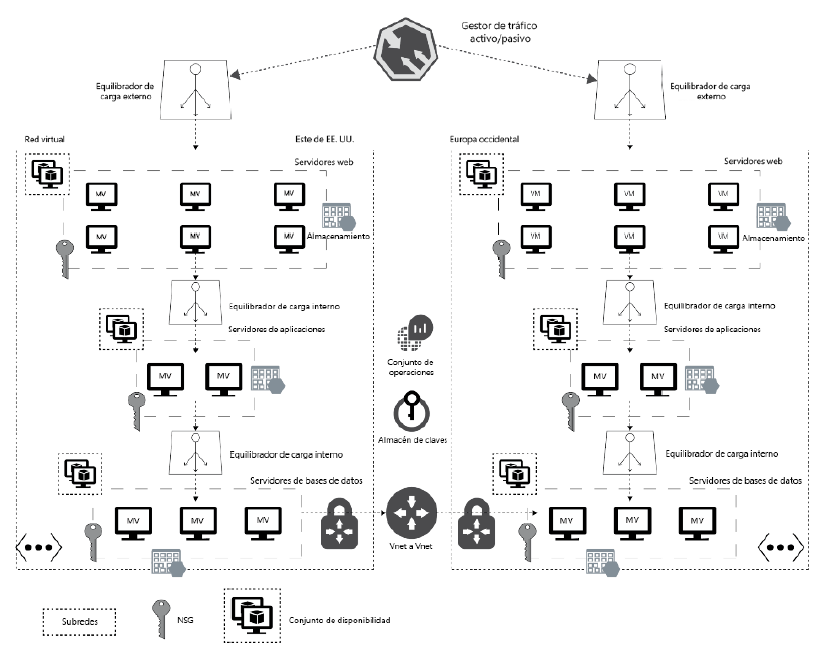
En la siguiente sección, exploraremos la escalabilidad, que es otra ventaja del cloud.
Escalabilidad
La ejecución de aplicaciones y sistemas que están disponibles para su consumo por parte de
los usuarios es un aspecto importante para los arquitectos de cualquier aplicación esencial.
Sin embargo, hay otra característica de las aplicaciones igualmente importante que es una
de las principales prioridades de los arquitectos: la escalabilidad de la aplicación.
Imagina una situación en la que se implementa una aplicación y se obtiene un rendimiento
y una disponibilidad excelentes con unos pocos usuarios, pero tanto la disponibilidad como
el rendimiento disminuyen a medida que comienza a aumentar el número de usuarios.
En ocasiones, una aplicación con una carga normal funciona bien, pero sufre una caída
de rendimiento con un aumento del número de usuarios. Esto puede suceder si se produce
un aumento repentino en el número de usuarios y el entorno no está diseñado para una
cantidad tan grande de usuarios.
Para dar cabida a estos picos en el número de usuarios, puedes aprovisionar el hardware
y el ancho de banda necesarios para gestionarlos. El problema de esto es que la capacidad
adicional no se usa durante la mayor parte del año y, por lo tanto, no proporciona ningún
retorno de la inversión. Se aprovisiona para su uso solo durante la temporada navideña
o las rebajas. Esperamos que ya te sientas más familiarizado con los problemas que están
intentando resolver los arquitectos. Todos estos problemas están relacionados con el ajuste
de tamaño de la capacidad y la escalabilidad de una aplicación. La prioridad de este capítulo
es comprender la escalabilidad como una preocupación arquitectónica y comprobar los
servicios que presta Azure para implementar la escalabilidad.
La planificación y el ajuste de tamaño de la capacidad son dos de las principales prioridades
para los arquitectos y sus aplicaciones y servicios. Los arquitectos deben encontrar un
equilibrio entre comprar y aprovisionar demasiados recursos y comprar y aprovisionar
muy pocos recursos. La disponibilidad de recursos escasos puede conducir a la incapacidad
de proporcionar servicios a todos los usuarios, que haría que estos acabasen recurriendo
a un competidor. Por otro lado, si se tienen demasiados recursos puede afectar al
presupuesto y al rendimiento de la inversión, dado que la mayoría de los recursos no
se utilizarán la mayor parte del tiempo. Por otra parte, el problema aumenta con el nivel
variante de demanda en diferentes épocas del año. Es casi imposible predecir el número
de usuarios de una aplicación a lo largo de cada día, y mucho menos durante un año.
Sin embargo, sí se puede calcular un número aproximado utilizando información de
periodos anteriores y mediante una supervisión continua.
La escalabilidad hace referencia a la capacidad de gestionar el aumento del número
de usuarios y de proporcionar el mismo nivel de rendimiento que cuando hay menos
usuarios utilizando recursos para la implementación, los procesos y la tecnología de la
aplicación. La escalabilidad puede significar atender más solicitudes sin que esto afecte
al rendimiento o puede implicar la gestión de un trabajo de mayor volumen que ocupe
más tiempo sin que se produzca una pérdida de rendimiento en ninguno de los casos.
Los arquitectos deben llevar a cabo ejercicios de ajuste de tamaño y planificación de la
capacidad al inicio de un proyecto y durante la fase de planificación para proporcionar
escalabilidad a las aplicaciones.
Algunas aplicaciones tienen patrones de demanda estables, mientras que otros son difíciles
de predecir. Los requisitos de escalabilidad son conocidos en el caso de las aplicaciones
con una demanda estable, mientras que discernirlos puede ser un proceso más complejo
en las aplicaciones con una demanda variable. El escalado automático, un concepto que
estudiaremos en la siguiente sección, debe utilizarse para las aplicaciones cuyas demandas
no se puedan predecir.
Las personas suelen confundir la escalabilidad con el rendimiento. En la siguiente sección,
verás una rápida comparación de estos dos términos.
Escalabilidad y rendimiento
Es bastante fácil confundirse entre escalabilidad y rendimiento en lo que se refiere
a cuestiones arquitectónicas, porque la escalabilidad consiste en asegurar que, con
independencia del número de usuarios que consuman la aplicación, todos reciban el
mismo nivel predeterminado de rendimiento.
El rendimiento está relacionado con garantizar que una aplicación satisfaga los tiempos
de respuesta y rendimiento predefinidos. La escalabilidad hace referencia a disponer de
provisiones para más recursos cuando sea necesario para poder atender a más usuarios
sin sacrificar el rendimiento.
Resulta más fácil de entender con esta analogía: la velocidad de un tren se relaciona
directamente con el rendimiento de una red ferroviaria. Sin embargo, cuando se permite
que más trenes funcionen en paralelo a una velocidad igual o superior, esto representa
la escalabilidad de la red ferroviaria.
Ahora que ya sabes cuál es la diferencia entre escalabilidad y rendimiento, veamos cómo
Azure proporciona escalabilidad.
Escalabilidad de Azure
En esta sección, vamos a explicar las características y las capacidades que proporciona
Azure para hacer que las aplicaciones tengan una alta disponibilidad. Antes de adentrarnos
en los detalles arquitectónicos y de configuración, es importante entender conceptos
relacionados con la alta disponibilidad de Azure, en otras palabras, el escalado.
El escalado hace referencia al aumento o disminución de la cantidad de recursos que
se utilizan para atender las solicitudes de los usuarios. El escalado puede ser automático
o manual. El escalado manual requiere que un administrador inicie manualmente el
proceso de escalado, mientras que el escalado automático hace referencia a un aumento
o disminución automáticos de los recursos en función de los eventos disponibles en
el entorno y el ecosistema, como la memoria y la disponibilidad de la CPU. El escalado
y la reducción de los recursos se pueden llevar a cabo en vertical o en horizontal,
algo que se explicará más adelante en esta sección.
Además de las actualizaciones graduales, los componentes fundamentales proporcionados
por Azure para lograr una alta disponibilidad son los siguientes:
- Escalado o reducción vertical
- Escalado o reducción horizontal
- Escalado automático
Escalado vertical
El escalado vertical de una MV o de un servicio implica la adición de recursos adicionales
a los servidores existentes, como CPU, memoria y discos. Su propósito es aumentar la
capacidad del hardware y los recursos físicos existentes.
Reducción vertical
La reducción vertical de una MV o de un servicio implica la eliminación de recursos existentes
de los servidores existentes, como CPU, memoria y discos. Su objetivo es reducir la capacidad
del hardware y los recursos físicos y virtuales existentes.
Escalado horizontal
El escalado horizontal implica añadir hardware adicional, por ejemplo, servidores y
capacidad adicionales. Por lo general, se trata de agregar nuevos servidores, asignándoles
direcciones IP, implementando aplicaciones en ellos y haciendo que formen parte de los
equilibradores de carga existentes, de manera que el tráfico se pueda encaminar hacia ellos.
El escalado horizontal también puede ser automático o manual. Sin embargo, para obtener
mejores resultados, se debe utilizar la automatización:

Reducción horizontal
La reducción horizontal es el proceso de eliminación del hardware existente, es decir,
servidores y capacidad existentes. Normalmente, esto implica la eliminación de los
servidores existentes, la anulación de la asignación de sus direcciones IP, así como la
eliminación de la configuración del equilibrador de carga existente, de manera que el tráfico
no pueda dirigirse hacia ellos. Como el escalado horizontal, la reducción horizontal puede ser
automática o manual.
Escalado automático
El escalado automático hace referencia al proceso de escalado/reducción vertical o
escalado/reducción horizontal de forma dinámica y según la demanda de la aplicación,
que se produce mediante automatización. El escalado automático es útil porque garantiza
que una implementación siempre conste de un número de instancias de servidor idóneo.
El escalado automático ayuda a crear aplicaciones con tolerancia a los errores. Esto no
solo admite la escalabilidad, sino que también hace que las aplicaciones estén altamente
disponibles. Por último, ofrece la mejor administración de costes. El escalado automático
permite tener la configuración óptima para instancias de servidor basándose en la demanda.
Ayuda a no realizar un aprovisionamiento excesivo de servidores, solo para que acaben siendo
infrautilizados, y elimina servidores que ya no son necesarios después del escalado horizontal.
Hasta ahora, hemos descrito la escalabilidad en Azure. Azure ofrece opciones de
escalabilidad para la mayoría de sus servicios. Exploremos la escalabilidad de PaaS
en Azure en la siguiente sección.
Escalabilidad de la PaaS
Azure proporciona App Service para hospedar aplicaciones administradas. App Service
es una oferta de PaaS de Azure. Proporciona servicios para las plataformas web y móviles.
Detrás de la web y estas plataformas móviles hay una infraestructura administrada que
gestiona Azure en nombre de sus usuarios. Los usuarios no ven ni administran ninguna
infraestructura, pero tienen la capacidad de ampliar la plataforma e implementar
sus aplicaciones sobre ella. Gracias a ello, los desarrolladores y arquitectos pueden
concentrarse en sus problemas empresariales en lugar de preocuparse por la plataforma
base y el aprovisionamiento de la infraestructura, la configuración y la resolución
de problemas. Los desarrolladores tienen la flexibilidad de elegir cualquier lenguaje,
SO y marco para desarrollar sus aplicaciones. App Service ofrece múltiples planes y,
en función de los planes seleccionados, existen diferentes grados de escalabilidad
disponibles. App Service proporciona los cinco planes siguientes:
- Libre: utiliza infraestructura compartida. Significa que se implementarán varias
aplicaciones en la misma infraestructura de un mismo inquilino o de varios inquilinos.
Proporciona 1 GB de almacenamiento gratuito. Sin embargo, en este plan no hay
ninguna instalación de escalado. - Compartido: también utiliza infraestructura compartida y proporciona 1 GB de
almacenamiento gratuito. Además, también se proporcionan dominios personalizados
como una característica extra. Sin embargo, en este plan no hay ninguna instalación
de escalado. - Básico: tiene tres referencias de almacén (SKU) diferentes: B1, B2 y B3. Cada
una cuenta con un mayor número de unidades de recursos disponibles para ella
en términos de CPU y memoria. En definitiva, proporciona una configuración
mejorada de las MV que prestan soporte a estos servicios. Además, proporcionan
almacenamiento, dominios personalizados y compatibilidad SSL. El plan básico
ofrece funciones básicas para el escalado manual. Este plan no dispone de escalado
automático. Se pueden utilizar como máximo tres instancias para el escalado
horizontal de la aplicación. - Estándar: también tiene tres SKU diferentes: S1, S2 y S3. Cada una cuenta con un
mayor número de unidades de recursos disponibles para ella en términos de CPU
y memoria. En definitiva, proporciona una configuración mejorada de las MV que
prestan soporte a estos servicios. Además, proporcionan almacenamiento, dominios
personalizados y compatibilidad con SSL de manera similar al plan básico. Este plan
también incluye una instancia de Traffic Manager, espacios de ensayo y una copia de
seguridad diaria como característica adicional al plan básico. El plan estándar ofrece
funciones para el escalado manual. Se pueden utilizar como máximo 10 instancias
para el escalado horizontal de la aplicación. - Premium: también tiene tres SKU diferentes: P1, P2 y P3. Cada una cuenta con un
mayor número de unidades de recursos disponibles para ella en términos de CPU
y memoria. En definitiva, proporciona una configuración mejorada de las MV que
prestan soporte a estos servicios. Además, proporciona almacenamiento, dominios
personalizados y compatibilidad con SSL de manera similar al plan básico. Este plan
también incluye una instancia de Traffic Manager, espacios de ensayo y 50 copias de
seguridad diarias como característica adicional al plan básico. El plan estándar ofrece
funciones para el escalado automático. Se pueden utilizar como máximo 20 instancias
para el escalado horizontal de la aplicación.
Hemos explorado los niveles de escalabilidad disponibles para los servicios PaaS. Ahora,
veamos cómo se puede escalar en el caso de un plan de App Service.
Escalado o reducción vertical de PaaS
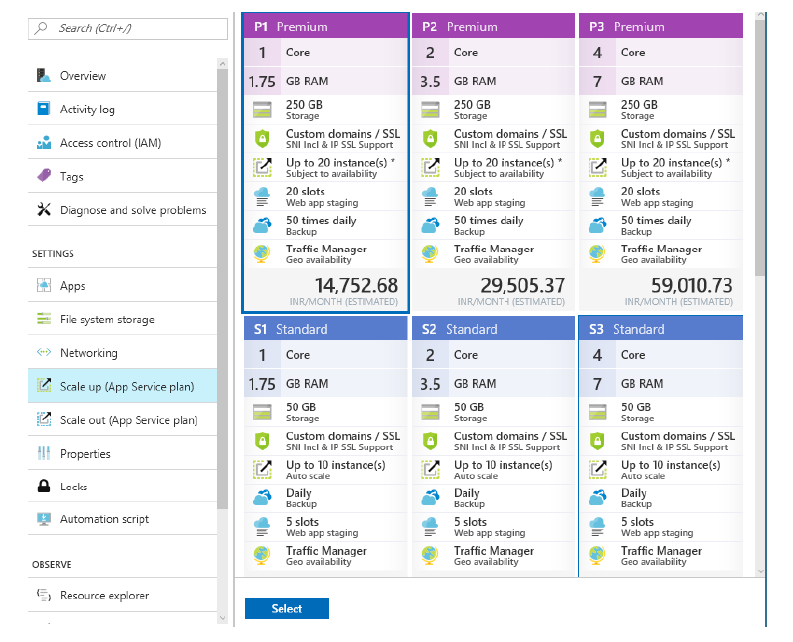
El escalado y la reducción verticales de los servicios hospedados en App Service son
bastante sencillos. El menú Escalar verticalmente de Azure App Services abre un nuevo
panel con todos los planes y sus SKU enumerados. La elección de un plan y una SKU
escalará o reducirá verticalmente el servicio, como se muestra en la Figura 2.9:
Escalado o reducción horizontal de PaaS
El escalado y la reducción horizontales de los servicios hospedados en App Service también
son bastante sencillos. El elemento de menú Escalar horizontalmente de Azure App Services
abre un nuevo panel con las opciones de configuración del escalado.
De forma predeterminada, el escalado automático está deshabilitado para los planes premium
y estándar. Puede activarse si se utiliza el elemento de menú Escalar horizontalmente y se
hace clic en el botón Habilitar escalado automático, como se muestra en la Figura 2.10:
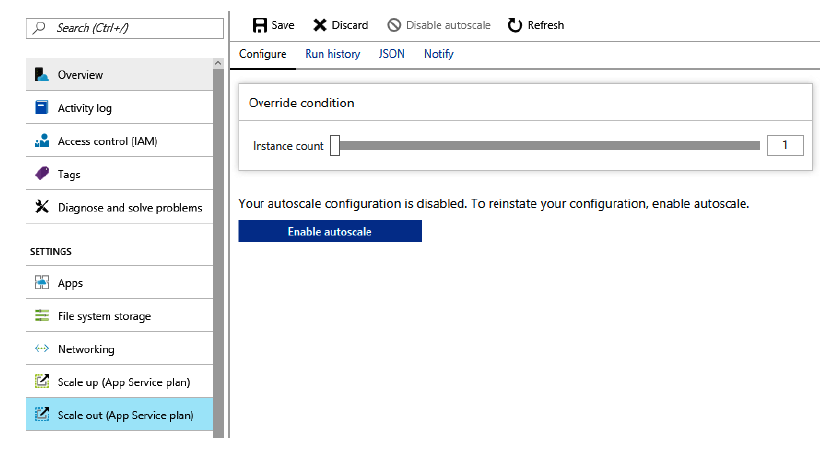
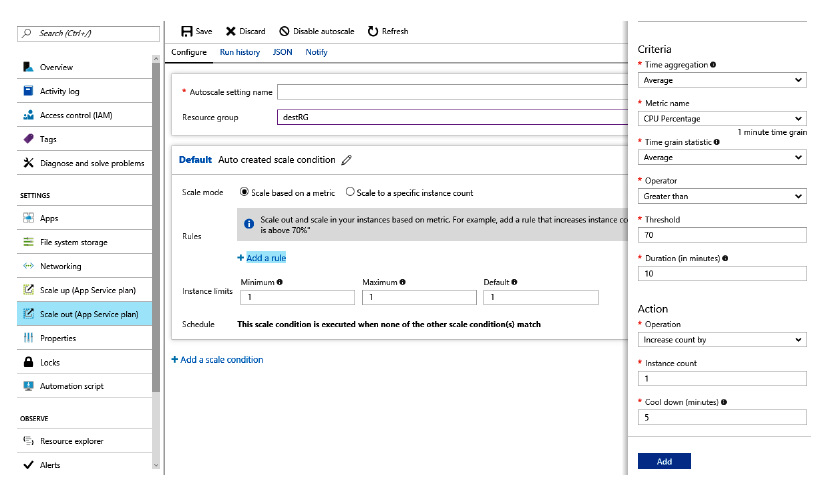
El escalado manual no requiere configuración, pero el escalado automático contribuye
a la configuración con la ayuda de las siguientes propiedades:
- Modo de escalado: se basa en cualquier métrica de rendimiento, como el uso de
CPU o memoria. O bien los usuarios pueden especificar simplemente el número
de instancias que desean escalar. - Cuándo escalar: pueden agregarse varias reglas que determinen cuándo realizar
el escalado y la reducción verticales. Cada regla puede determinar criterios como
el consumo de CPU o memoria, si aumentar o disminuir el número de instancias,
cuántas instancias aumentar o reducir al mismo tiempo. Debe configurarse al menos
una regla para el escalado horizontal y otra para la reducción horizontal. La definición
de umbrales ayuda a definir los límites superior e inferior que deben activar el
escalado automático, ya sea para aumentar o para disminuir el número de instancias. - Cómo escalar: especifica cuántas instancias se deben crear o eliminar en cada
operación de escalado o reducción horizontal:
Esta es una característica muy útil que puede habilitarse en cualquier implementación.
No obstante, debes habilitar el escalado horizontal y la reducción horizontal juntos para
garantizar que se restablezca la capacidad normal de tu entorno después del escalado
horizontal.
Puesto que hemos descrito la escalabilidad en PaaS, a continuación vamos a hablar sobre
la escalabilidad en IaaS.
Escalabilidad de la IaaS
Hay usuarios que desean tener un control total sobre su infraestructura base, plataforma
y aplicación. Preferirán consumir soluciones de IaaS en lugar de soluciones de PaaS.
Cuando estos clientes creen MV, también son responsables de ajustar el tamaño de la
capacidad y el escalado. No existe una configuración «out of the box» para el escalado
manual o automático de las MV. Estos clientes deben escribir sus propios scripts de
automatización, desencadenadores y reglas para lograr el escalado automático. La creación
de MV conlleva la responsabilidad de mantenerlas. La revisión, actualización y mejora
de las MV es responsabilidad de los propietarios. Los arquitectos deben pensar en el
mantenimiento planificado y en el no planificado. Debe pensarse bien cómo se deben aplicar
las revisiones, el orden, el agrupamiento y otros factores de estas MV para garantizar que
no se pone en riesgo la escalabilidad ni la disponibilidad de una aplicación. Para paliar estos
problemas, Azure proporciona conjuntos de escalado de máquinas virtuales (VMSS) como
una solución, que describiremos a continuación.
Arquitectura de VMSS
Los VMSS permiten crear hasta 1000 MV en un conjunto de escalado cuando se utiliza
una imagen de plataforma y 100 MV si se usa una imagen personalizada. Si el número
de MV es inferior a 100 en un conjunto de escalado, estas se colocan en un único conjunto
de disponibilidad. Sin embargo, si el número es superior a 100, se crean varios conjuntos de
disponibilidad (denominados grupos de selección de ubicación) y las MV se distribuyen entre
estos conjuntos de disponibilidad. En el capítulo 1, Introducción a Azure, hemos visto que
las MV de un conjunto de disponibilidad se colocan en dominios de error y de actualización
diferentes. Los conjuntos de disponibilidad relacionados con los VMSS tienen cinco dominios
de error y actualización de forma predeterminada. Los VMSS proporcionan un modelo que
contiene información de los metadatos de todo el conjunto. Cambiar este modelo y aplicar los
cambios afecta a todas las instancias de MV. Esta información de metadatos incluye el número
máximo y mínimo de instancias de MV, la SKU del sistema operativo y la versión, el número
actual de MV, los dominios de error y de actualización, etc. Esto se muestra en la Figura 2.13:
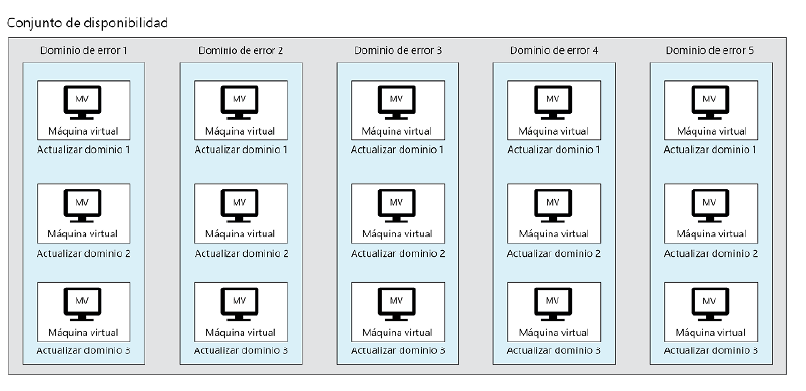
Escalado de VMSS
El escalado hace referencia a un aumento o una disminución de los recursos de
computación y almacenamiento. Un VMSS es un recurso repleto de características que hace
que el escalado resulte sencillo y eficaz. Ofrece un escalado automático que ayuda a escalar
o reducir verticalmente basándose en eventos y datos externos, como el uso de la CPU y la
memoria. A continuación se describen algunas de las características de escalado de VMSS.
Escalado horizontal y vertical
El escalado puede ser horizontal, vertical o ambos. El escalado horizontal es otra denominación
para escalado/reducción horizontal, mientras que el escalado vertical hace referencia
al escalado/reducción vertical.
Capacidad
Los VMSS tienen una propiedad capacity que determina el número de MV en un conjunto
de escalado. Un VMSS puede implementarse con cero como valor de esta propiedad.
No creará ni una sola MV, pero si aprovisionas un VMSS con un número para la propiedad
capacity, se crea ese número de MV.
Escalado automático
El escalado automático de MV en un VMSS hace referencia a la adición o eliminación
de instancias de MV en función del entorno configurado para satisfacer las demandas
de rendimiento y escalabilidad de una aplicación. En general, en ausencia de un VMSS,
esto se logra utilizando scripts de automatización y runbooks.
Los VMSS contribuyen a este proceso de automatización con la ayuda de la configuración.
En lugar de escribir scripts, un VMSS puede configurarse para el escalado y la reducción
automáticas verticales.
El escalado automático usa varios componentes integrados para lograr su objetivo
final. El escalado automático conlleva la supervisión de las MV y la recopilación datos
de telemetría sobre estas, de manera continua. Estos datos se almacenan, combinan
y, a continuación, evalúan conforme a un conjunto de reglas para determinar si debe
activar el escalado automático. El desencadenador podría ser un escalado o una reducción
horizontal. También puede ser un escalado o una reducción vertical.
El mecanismo de escalado automático utiliza registros de diagnóstico para la recopilación
de datos de telemetría de las MV. Estos registros se almacenan en las cuentas de
almacenamiento como métricas de diagnóstico. El mecanismo de escalado automático
también utiliza el servicio de supervisión Application Insights, que lee estas métricas,
las combina y las almacena en una cuenta de almacenamiento.
Los trabajos de escalado automático en segundo plano se ejecutan continuamente para
leer los datos de almacenamiento de Application Insights, evaluarlos basándose en todas
las reglas configuradas para el escalado automático y, si cumple alguna de las reglas
o combinación de reglas, ejecutar el proceso de escalado automático. Las reglas pueden
tener en cuenta las métricas de las MV invitadas y del servidor host.
Las reglas definidas mediante las descripciones de propiedades están disponibles en
https://docs.microsoft.com/azure/virtual-machine-scale-sets/virtual-machine-scalesets-
autoscale-overview.
La arquitectura de escalado automático de VMSS se muestra en la Figura 2.14:
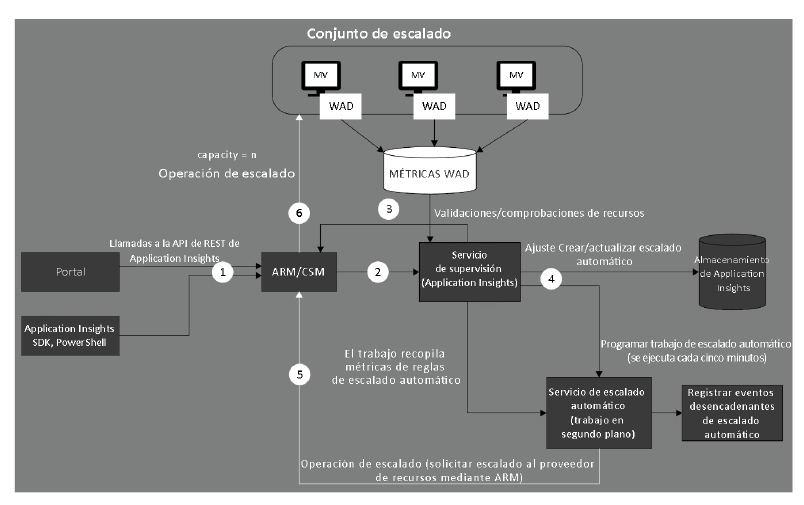
El escalado automático se puede configurar para escenarios que son más complejos que las
métricas generales disponibles desde los entornos. Por ejemplo, el escalado podría basarse
en cualquiera de los siguientes escalados:
- Un día específico
- Una programación recurrente, como los fines de semana
- Días laborables frente a fines de semana
- Días festivos y eventos únicos
- Múltiples métricas de recursos
Estas pueden configurarse con la propiedad schedule de recursos de Application Insights,
que sirven para registrar las reglas.
Los arquitectos deben garantizar que al menos dos acciones, el escalado horizontal y la
reducción horizontal, se configuran conjuntamente. El escalado o la reducción horizontales
de una configuración no ayudarán a lograr los beneficios de escalado proporcionados por
los VMSS.
En resumen, hemos descrito las opciones de escalabilidad de Azure y las características
de escalado detalladas en el caso de IaaS y PaaS para satisfacer tus requisitos empresariales.
Si recuerdas el modelo de responsabilidad compartida, recordarás que las actualizaciones
y el mantenimiento de la plataforma debe realizarlo el proveedor de cloud. En este caso,
Microsoft se encarga de las actualizaciones y el mantenimiento relacionados con la
plataforma. Veamos cómo se consigue esto en la siguiente sección.
Actualizaciones y mantenimiento
Después de implementar VMSS y las aplicaciones, ambos deben mantenerse de forma activa.
El mantenimiento planificado debe realizarse periódicamente para garantizar que tanto
el entorno como la aplicación estén actualizados con las últimas características, desde
el punto de vista de la seguridad y la resiliencia.
Las actualizaciones pueden estar asociadas con las aplicaciones, la instancia de MV invitada
o con la propia imagen. Las actualizaciones pueden ser bastante complejas, porque deben
producirse sin afectar a la disponibilidad, la escalabilidad y el rendimiento de los entornos
y las aplicaciones. Para garantizar que las actualizaciones puedan tener lugar en una
instancia cada vez utilizando métodos de actualización gradual, es importante que un
VMSS apoye y proporcione las capacidades para estos escenarios avanzados.
Existe una utilidad proporcionada por el equipo de Azure para administrar las actualizaciones
de VMSS. Es una utilidad basada en Python que se puede descargar desde https://github.
com/gbowerman/vmssdashboard. Hace llamadas de API de REST a Azure para administrar
los conjuntos de escalado. Esta utilidad se puede utilizar para iniciar, detener, actualizar
y volver a crear una imagen de MV en un FD o un grupo de MV, como se muestra en la
Figura 2.15:
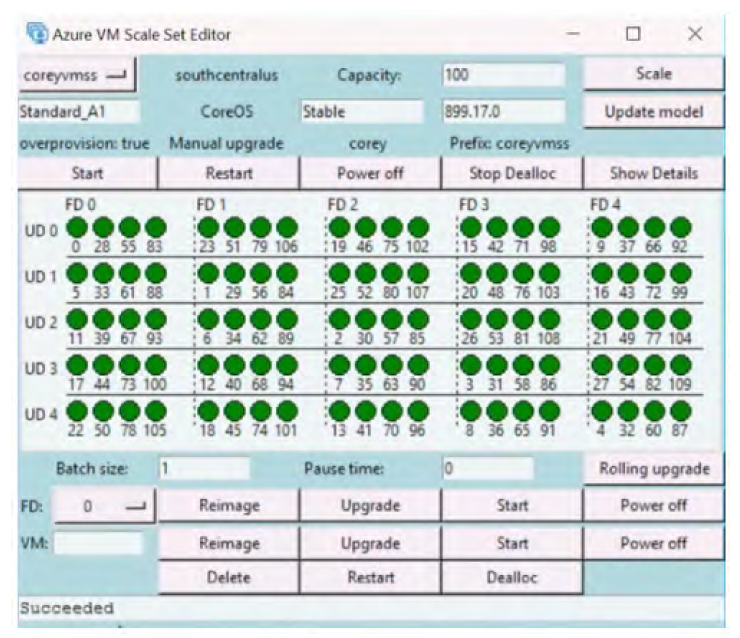
Como tienes una comprensión básica de la actualización y el mantenimiento, veamos cómo
se realizan las actualizaciones de las aplicaciones en VMSS.
Actualizaciones de las aplicaciones
Las actualizaciones de las aplicaciones en VMSS no deben ejecutarse manualmente. Deben
ejecutarse como parte de la administración de versiones y las canalizaciones que utilizan
la automatización. Por otra parte, una actualización debe producirse en una instancia de
la aplicación cada vez, sin que afecte a la disponibilidad y la escalabilidad globales de una
aplicación. Se deben implementar herramientas de administración de la configuración,
como Desired State Configuration (DSC), para administrar las actualizaciones de la
aplicación. El servidor de extracción de DSC se puede configurar con la última versión
de la configuración de la aplicación y debe aplicarse de forma gradual en cada instancia.
En la siguiente sección, nos centraremos en cómo se realizan las actualizaciones en el
sistema operativo invitado.
Actualizaciones de máquinas invitadas
Las actualizaciones de MV son responsabilidad del administrador. Azure no es responsable
de aplicar revisiones a MV invitadas. Las actualizaciones de las máquinas invitadas están en
el modo preview y los usuarios deben controlar la aplicación de las revisiones manualmente
o utilizar métodos automatización personalizados, como runbooks y scripts. Sin embargo,
las revisiones graduales están en modo preview y se pueden configurar en la plantilla de
Azure Resource Manager con la política de actualización, como se muestra aquí:
«upgradePolicy»: {
«mode»: «Rolling»,
«automaticOSUpgrade»: «true» or «false»,
«rollingUpgradePolicy»: {
«batchInstancePercent»: 20,
«maxUnhealthyUpgradedInstanceCount»: 0,
«pauseTimeBetweenBatches»: «PT0S»
}
}
Ahora que ya sabemos cómo se administran las actualizaciones de máquinas invitadas
en Azure, veamos cómo se logran las actualizaciones de imágenes.
Prácticas recomendadas de escalado para VMSS
En esta sección, repasaremos algunas de las prácticas recomendadas que deben implementar las
aplicaciones para aprovechar las ventajas de la capacidad de escalado proporcionada por VMSS.
Preferencia por el escalado horizontal
El escalado horizontal es una solución de escalado mejor que el escalado vertical. Escalar
o reducir verticalmente significa cambiar el tamaño de las instancias de MV. Cuando se cambia
el tamaño de una MV, debe reiniciarse generalmente, lo que conlleva sus propias desventajas.
En primer lugar, hay un tiempo de inactividad para la máquina. En segundo lugar, si hay
usuarios activos conectados a la aplicación en esa instancia, podrían enfrentarse a la falta de
disponibilidad de la aplicación o podrían incluso perder transacciones. El escalado horizontal
no afecta a las MV existentes, sino que aprovisiona máquinas más recientes y las agrega al grupo.
Nuevas instancias e instancias latentes
Se pueden emplear dos métodos para escalar instancias nuevas: crear la nueva instancia desde
cero, que requiere instalar aplicaciones, configurarlas y probarlas, o bien iniciar instancias
latentes en espera cuando sea necesario ante la presión de escalabilidad en otros servidores.
Configurar adecuadamente el número máximo y mínimo de instancias
Si se establece un valor de dos para los recuentos mínimo y máximo de instancias, habiendo
actualmente dos instancias, no podrá tener lugar ninguna acción de escalado. Debe haber
una diferencia suficiente entre los recuentos de instancias máximo y mínimo, que son
inclusivos. El escalado automático siempre escala entre estos límites.
Simultaneidad
Las aplicaciones están diseñadas para que la escalabilidad se centre en la simultaneidad. Las
aplicaciones deben usar patrones asincrónicos para garantizar que las solicitudes de cliente
no esperen indefinidamente para adquirir recursos si los recursos están ocupados atendiendo
otras solicitudes. La implementación de patrones asincrónicos en el código garantiza que los
subprocesos no esperen los recursos y que los sistemas no se agoten como consecuencia
de todos los subprocesos disponibles. Las aplicaciones deben implementar el concepto
de tiempo de espera si se espera que se produzcan errores intermitentes.
Diseñar aplicaciones sin estado
Las aplicaciones y los servicios deben diseñarse para que no tengan estado. La escalabilidad
puede ser difícil de conseguir en el caso de servicios con estado, pero resulta muy
fácil escalar servicios sin estado. Con los estados aparece el requisito de componentes
adicionales y de implementaciones, como replicación, repositorio centralizado o
descentralizado, mantenimiento y sesiones adhesivas. Todos estos son obstáculos en el
camino hacia la escalabilidad. Imagina un estado activo de mantenimiento de servicio en un
servidor local. Sin importar el número de solicitudes que haya en la aplicación general o en
el servidor específico, las solicitudes posteriores deben ser atendidas por el mismo servidor.
Las solicitudes posteriores no pueden ser procesadas por otros servidores. Esto hace que la
implementación de escalabilidad sea un problema.
Almacenamiento en caché y red de distribución de contenido (CDN)
Las aplicaciones y los servicios deben aprovechar el almacenamiento en caché.
El almacenamiento en caché ayuda a eliminar varias llamadas posteriores a cualquiera
de las bases de datos de los sistemas de archivos. Esto contribuye a la disponibilidad
de los recursos y los libera para más solicitudes. La CDN es otro mecanismo utilizado
para almacenar en caché archivos estáticos, como imágenes y bibliotecas JavaScript.
Está disponible en los servidores de todo el mundo. También hacen que los recursos
estén disponibles y libres para solicitudes de cliente adicionales, lo que implica que
las aplicaciones sean altamente escalables.
Diseño N+1
El diseño N+1 hace referencia a la creación de redundancia dentro de la implementación
general para cada componente. Significa planificar cierta redundancia, incluso cuando
no se requiere. Esto podría significar MV, almacenamiento e interfaces de red adicionales.
Si tenemos en cuenta las prácticas recomendadas anteriores al diseñar cargas de trabajo,
el uso de VMSS mejorará la escalabilidad de las aplicaciones. En la siguiente sección,
explicaremos con más detalle la supervisión.
Supervisión
La supervisión es un aspecto estructural importante que debe formar parte de cualquier
solución —ya sea esta grande o pequeña, crítica o no y basada en el cloud o no— y en ningún
caso debe descuidarse.
El término «supervisión» hace referencia al acto de realizar un seguimiento de las soluciones
y obtener diversos datos de telemetría, procesarlos, identificar los que, según determinan
las reglas, se ajustan a los criterios de alerta y activar esas alertas. Normalmente, en el
entorno se implementa un agente que lo supervisa y envía la información de telemetría
a un servidor centralizado, donde se realiza el resto del proceso de generación de alertas
y notificación a las partes interesadas.
La supervisión adopta medidas y emprende acciones tanto proactivas como reactivas con
respecto a una solución. También es el primer paso hacia la auditoría de una solución. Sin
la capacidad de supervisar las entradas de registros, sería difícil auditar un sistema desde
diversas perspectivas, como la seguridad, el rendimiento y la disponibilidad.
La supervisión ayuda a identificar problemas de disponibilidad, rendimiento y escalabilidad
antes de que surjan. La supervisión permite detectar errores de hardware, errores de
configuración de software y problemas de actualización de revisiones mucho antes de que
afecten a los usuarios; también permite poner solución a la degradación del rendimiento
antes de que suceda.
La supervisión localiza de forma reactiva las áreas y ubicaciones que están causando
problemas, identifica los problemas y propicia reparaciones más rápidas y mejores.
Los equipos pueden identificar patrones de problemas con la información de telemetría de
la función de supervisión y eliminarlos con soluciones y características nuevas e innovadoras.
Azure es un completo entorno de cloud que ofrece múltiples características y recursos
de supervisión para supervisar no solo la implementación en el cloud, sino también la
implementación on-premises.
Supervisión en Azure
La primera pregunta que debe responderse es: «¿qué debemos supervisar?». Esta pregunta
es aún más importante en el caso de las soluciones que se implementan en el cloud, ya que
su control es limitado.
Hay algunos componentes importantes que se deberían supervisar. Entre ellos se incluyen
los siguientes:
- Aplicaciones personalizadas
- Recursos de Azure
- Sistemas operativos invitados (MV)
- Sistemas operativos de host (servidores físicos de Azure)
- Infraestructura de Azure
Hay diferentes servicios de registro y supervisión de Azure para estos componentes,
que se describen en las secciones siguientes.
Registros de actividad de Azure
Los registros de actividad, anteriormente conocidos como registros de auditoría
y registros operativos, notifican eventos de plano de control en la plataforma Azure.
Proporcionan información y datos de telemetría en el nivel de la suscripción, en lugar de
en el nivel del recurso individual. Realizan un seguimiento de la información sobre todos
los cambios que se producen en el nivel de la suscripción, como la creación, eliminación
y actualización de recursos con Azure Resource Manager (ARM). Los registros de actividad
nos ayudan a determinar la identidad de, por ejemplo, entidad de servicio, usuarios o grupos,
y realizar acciones (como escribir o actualizar) en los recursos (por ejemplo, almacenamiento,
máquinas virtuales o bases de datos SQL) en un punto temporal específico. Proporcionan
información sobre los recursos cuya configuración se modifica, pero no su funcionamiento
y ejecución internos. Por ejemplo, puedes obtener los registros para iniciar una máquina
virtual, cambiar el tamaño de una máquina virtual o detener una máquina virtual.
El siguiente tema que vamos a tratar son los registros de diagnóstico.
Registros de diagnóstico de Azure
La información que se origina del funcionamiento interno de los recursos de Azure
se reúne en lo que se conoce como registros de diagnóstico. Estos registros proporcionan
información de telemetría sobre las operaciones de los recursos que son inherentes a
los recursos. No todos los recursos proporcionan registros de diagnóstico y los recursos
que proporcionan registros de su propio contenido son completamente diferentes de
otros recursos. Los registros de diagnóstico se configuran individualmente para cada
recurso. Un ejemplo de registro de diagnóstico es el almacenamiento de un archivo
en un contenedor de un blob de una cuenta de almacenamiento.
El siguiente tipo de registro que vamos a describir son los registros de aplicación.
Registros de aplicación de Azure
Los registros de aplicación pueden obtenerlos los recursos de Application Insights y se
pueden administrar centralmente. Ayudan a obtener información sobre el funcionamiento
interno de las aplicaciones personalizadas, como las métricas de rendimiento y disponibilidad,
y los usuarios pueden utilizar los conocimientos adquiridos para administrarlas mejor.
Por último, tenemos registros de sistema operativo invitado y host. Vamos a describir lo que son.
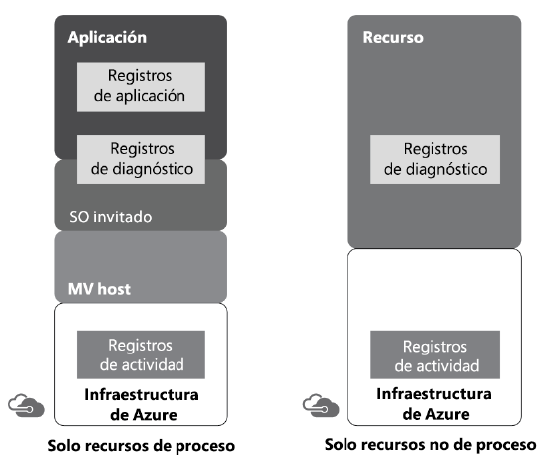
Registros de sistema operativo invitado y host
Los registros de sistema operativo tanto invitado como host se ofrecen a los usuarios
mediante Azure Monitor. Proporcionan información sobre los estados de los sistemas
operativos invitado y host:
Los recursos importantes de Azure relacionados con la supervisión son Azure Monitor, Azure
Application Insights y Log Analytics, anteriormente conocidos como Operational Insights.
Hay otras herramientas, como System Center Operations Manager (SCOM), que si bien
no forman parte de la característica del cloud, pueden implementarse en máquinas virtuales
basadas en IaaS para supervisar cualquier carga de trabajo en Azure o en un centro de datos
on-premises. Analizaremos los tres recursos de supervisión en la siguiente sección.
Azure Monitor
Azure Monitor es una herramienta y un recurso central que ofrece
características de administración completas que te permiten supervisar una suscripción
de Azure. Proporciona características de administración de registros de actividad, registros
de diagnóstico, métricas, Application Insights y Log Analytics. Debe considerarse como
un panel y un recurso de administración de todas las demás capacidades de supervisión.
Nuestro siguiente tema es Azure Application Insights.
Azure Application Insights
Azure Application Insights ofrece capacidades de supervisión, registros y métricas
centralizadas en Azure a las aplicaciones personalizadas. Las aplicaciones personalizadas
pueden enviar métricas, registros y otra información de telemetría a Azure Application
Insights. También ofrece capacidades completas de creación de informes, paneles y análisis
para extraer conocimientos de los datos entrantes y realizar las acciones que correspondan.
Ahora que hemos descrito Application Insights, echemos un vistazo a otro servicio similar
denominado Azure Log Analytics.
Azure Log Analytics
Azure Log Analytics permite el procesamiento centralizado de registros y genera
información y alertas a partir de ellos. Los registros de actividad, los registros de
diagnóstico, los registros de aplicación, los registros de eventos e incluso los registros
personalizados pueden enviar información a Log Analytics que, a su vez, puede
proporcionar capacidades completas de creación de informes, paneles y análisis para
extraer conocimientos de los datos entrantes y realizar las acciones que correspondan.
Ahora que conocemos el propósito de Log Analytics, vamos a analizar cómo se almacenan
los registros en un área de trabajo de Log Analytics y cómo se pueden consultar.
Registros
Un área de trabajo de Log Analytics proporciona capacidades de búsqueda para buscar
entradas de registro específicas, exportar todos los datos de telemetría a Excel o Power
BI y buscar mediante un lenguaje de consulta denominado lenguaje de consulta Kusto (KQL),
similar a SQL.
A continuación, se muestra la pantalla Búsqueda de registros:
En la siguiente sección, describiremos las soluciones de Log Analytics, que son como
capacidades adicionales en un espacio de trabajo de Log Analytics.
Soluciones
En Log Analytics, las soluciones son capacidades adicionales que pueden agregarse a un
área de trabajo para obtener datos de telemetría adicionales que no se obtienen de manera
predeterminada. Cuando se agregan estas soluciones a un espacio de trabajo, los paquetes
de administración correspondientes se envían a todos los agentes conectados al espacio de
trabajo de forma que puedan configurarse automáticamente para capturar datos específicos
de la solución de las MV y los contenedores y luego los envíen al espacio de trabajo de Log
Analytics. Las soluciones de supervisión de Microsoft y los partners están disponibles en
Azure Marketplace.
Azure ofrece numerosas soluciones de Log Analytics para el seguimiento y la supervisión
de diferentes aspectos de los entornos y las aplicaciones. Como mínimo, se debería añadir
al área de trabajo un conjunto de soluciones que sean genéricas y puedan aplicarse a casi
cualquier entorno:
- Capacidad y rendimiento
- Estado del agente
- Seguimiento de cambios
- Contenedores
- Seguridad y auditoría
- Administración de actualizaciones
- Supervisión de rendimiento de red
Otro aspecto clave de la supervisión son las alertas. Las alertas ayudan a notificar a
las personas correctas durante cualquier evento supervisado. En la siguiente sección,
describiremos las alertas.
Alertas
Log Analytics nos permite generar alertas en relación con los datos ingeridos. Para ello,
ejecuta una consulta predefinida compuesta de condiciones para datos entrantes. Si
encuentra registros que se clasifiquen dentro el ámbito de los resultados de la consulta,
genera una alerta. Log Analytics proporciona un entorno altamente configurable para
determinar las condiciones para generar alertas, la ventana de tiempo en la que la consulta
debe devolver registros, la ventana de tiempo en la que debe ejecutarse la consulta y las
acciones que deben realizarse cuando la consulta devuelva resultados como una alerta:
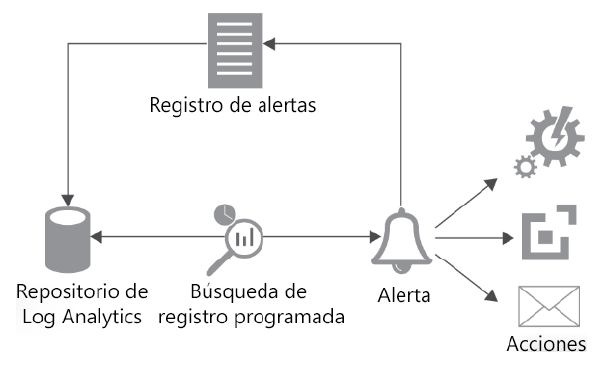
Vamos a explicar los pasos para configurar alertas a través de Log Analytics:
- El primer paso en la configuración de una alerta es agregar una nueva regla de alerta
desde Azure Portal o la automatización desde el menú de alertas del recurso de Log
Analytics. - En el panel resultante, selecciona un ámbito para la regla de alerta. El ámbito determina
qué recurso se debe supervisar para las alertas: puede ser una instancia de recurso,
como una cuenta de Azure Storage, un tipo de recurso, como una máquina virtual
de Azure, un grupo de recursos o una suscripción:
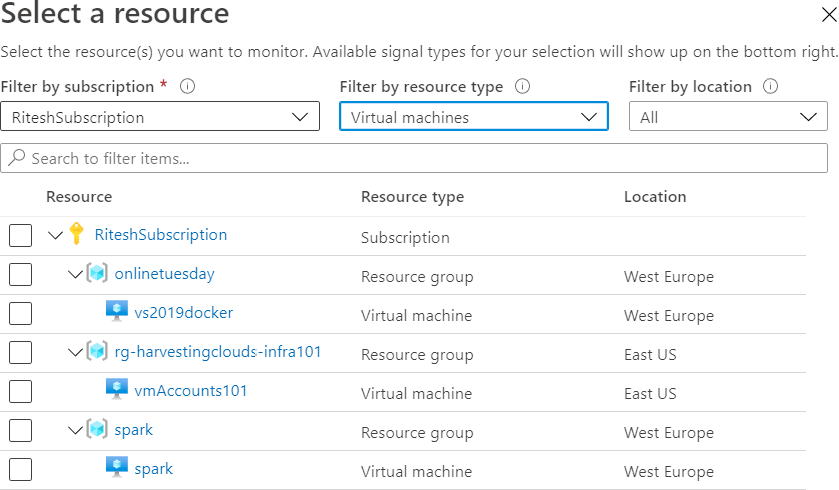
- Tras la selección de recursos, se deben establecer las condiciones de la alerta.
La condición determina la regla que se evalúa con respecto a los registros y las
métricas del recurso seleccionado y solo después de que la condición se vuelva
verdadera se genera una alerta. Hay una gran cantidad de métricas y registros
disponibles para generar condiciones. En el ejemplo siguiente, se crea una alerta
con un valor de umbral estático del 80 % para Porcentaje de CPU (promedio) y los
datos se van a recopilar cada cinco minutos y evaluar cada minuto:
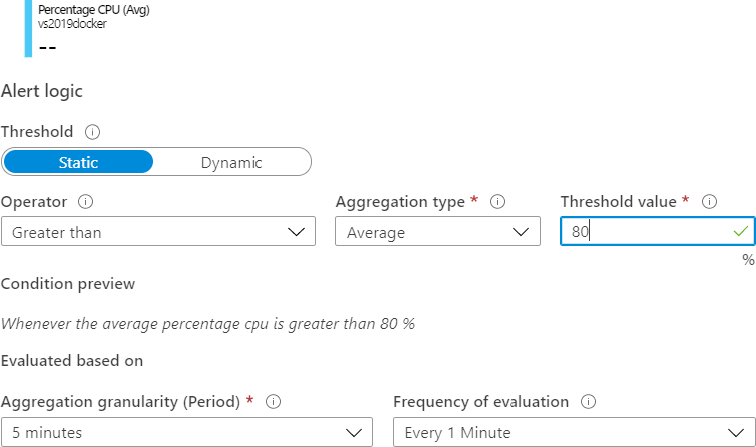
Las alertas también admiten umbrales dinámicos, que utilizan machine learning para
aprender el comportamiento histórico de las métricas y detectar irregularidades que
podrían indicar problemas de servicio.
- Por último, crea un grupo de acciones o reutiliza un grupo existente que determine
las notificaciones relativas a las alertas a las partes interesadas. La sección Grupos
de acciones te permite configurar los pasos que deben seguir a la generación de una
alerta. Por lo general, debe producirse una acción correctiva o una notificación. Log
Analytics ofrece ocho maneras diferentes de crear una nueva acción que se pueden
combinar de cualquier forma. Una alerta ejecutará alguna o todas las siguientes
acciones configuradas:
- Notificación por correo electrónico/SMS/de inserción/voz: se envía una notificación
por correo electrónico/SMS/de inserción/voz a los destinatarios configurados: - Webhooks: un webhook ejecuta un proceso externo arbitrario utilizando un
mecanismo HTTP POST. Por ejemplo, se puede ejecutar una API de REST o se
pueden invocar las API de Service Manager/ServiceNow para crear una incidencia. - Azure Functions: ejecuta una función de Azure, que pasa la carga necesaria
y ejecuta la lógica que contiene la carga. - Logic Apps: ejecuta un flujo de trabajo de Logic Apps personalizado.
- Correo electrónico a rol de Azure Resource Manager: envía un correo electrónico
al titular de un rol de Azure Resource Manager, como propietario, colaborador
o lector. - Webhook seguro: un webhook ejecuta un proceso externo arbitrario utilizando un
mecanismo HTTP POST. Los webhooks están protegidos mediante un proveedor
de identidades, como Azure Active Directory. - Runbooks de Automation: esta acción ejecuta runbooks de Azure Automation.
- ITSM: las soluciones de ITSM se deben aprovisionar antes de utilizar esta opción,
que ayuda a conectarse a los sistemas ITSM y enviarles información.
- Después de toda esta configuración, debes proporcionar los valores
de Nombre, Descripción y Gravedad para que la regla de alerta la genere.
Como se ha mencionado al principio de esta sección, las alertas desempeñan un papel
vital en la supervisión que ayuda al personal autorizado a tomar las medidas necesarias
en función de la alerta que se activa.
Resumen
La alta disponibilidad y la escalabilidad son aspectos arquitectónicos de vital importancia.
La gran mayoría de aplicaciones y arquitectos intentan implementar una alta disponibilidad.
Azure es una plataforma madura que entiende la necesidad de estas cuestiones
arquitectónicas en las aplicaciones y proporciona recursos para implementarlas en varios
niveles. Estas cuestiones arquitectónicas no son opciones añadidas y deben formar parte
del ciclo de vida de desarrollo de las aplicaciones desde la fase de la planificación.
La supervisión es un aspecto importante de la arquitectura de cualquier solución. También
es el primer paso para ser capaz de auditar una aplicación correctamente. Permite que las
operaciones administren la solución, de forma tanto reactiva como proactiva. Proporciona
los registros necesarios para localizar y solucionar los problemas que puedan surgir en
plataformas y aplicaciones. Hay muchos recursos en Azure específicos para implementar
la supervisión en Azure, otros clouds y centros de datos on-premises. Application Insights
y Log Analytics son dos de los recursos más importantes a este respecto. Ni que decir tiene
que la supervisión es imprescindible para innovar con el fin de crear mejores soluciones
y productos a partir de los conocimientos obtenidos de los datos de supervisión.
Este capítulo ha tratado únicamente de la disponibilidad, escalabilidad y supervisión
de soluciones; el siguiente capítulo trata sobre patrones de diseño relacionados con
redes virtuales, cuentas de almacenamiento, regiones, zonas de disponibilidad y conjuntos
de disponibilidad. Durante el diseño de soluciones en el cloud, estos principios son muy
importantes para crear soluciones rentables con una mayor productividad y disponibilidad.