



En el capítulo anterior, describimos a grandes rasgos el cloud de Azure y aprendimos algunos conceptos importantes relacionados con esta solución. Este capítulo trata sobre los patrones de cloud de Azure relacionados con las redes virtuales, las cuentas de almacenamiento, las regiones, las zonas de disponibilidad y los conjuntos de disponibilidad. Estos son componentes importantes que afectan la arquitectura final que se entrega a los consumidores en términos de coste, eficiencia y productividad general. En este capítulo también se describirán brevemente los patrones de cloud que nos ayudan en la implementación de escalabilidad y rendimiento para una arquitectura.
En este capítulo, abordaremos los siguientes temas:
- Diseño de red virtual de Azure
- Diseño de almacenamiento de Azure
- Zonas de disponibilidad, regiones y conjuntos de disponibilidad de Azure
- Patrones de diseño de Azure relacionados con la mensajería, el rendimiento
y la escalabilidad
Zonas de disponibilidad y regiones de Azure
Azure cuenta con grandes centros de datos interconectados en una única red de gran tamaño.
Los centros de datos se agrupan, según su proximidad física, en regiones de Azure. Por ejemplo,
los centros de datos en Europa occidental se encuentran disponibles para los usuarios de Azure
de Europa occidental. Los usuarios no pueden elegir su centro de datos preferido. Pueden
seleccionar su región de Azure y Azure asignará un centro de datos adecuado.
La elección de la región correcta es una decisión arquitectónica importante ya que afecta
a los siguientes aspectos:
- Disponibilidad de recursos
- Cumplimiento normativo relativo a datos y privacidad
- Rendimiento de la aplicación
- Coste de ejecución de aplicaciones
Veamos cada uno de estos puntos más detalladamente.
Disponibilidad de recursos
No todos los recursos están disponibles en todas las regiones de Azure. Si tu arquitectura
de la aplicación exige un recurso que no está disponible en una región, no resultará útil
elegir dicha región. Por el contrario, una región debe elegirse basándose en la disponibilidad
de los recursos que requiera la aplicación. Puede darse el caso de que el recurso no esté
disponible en la fase de desarrollo de la arquitectura de la aplicación y que pueda figurar
en la hoja de ruta de Azure para que esté disponible posteriormente.
Por ejemplo, Log Analytics no está disponible en todas las regiones. Si tus orígenes de datos
están en la región A y el área de trabajo de Log Analytics está en la región B, debes pagar
por el ancho de banda, que son los cargos de la salida de datos de la región A a B. Del mismo
modo, algunos servicios pueden funcionar con recursos ubicados en la misma región. Por
ejemplo, si quieres cifrar los discos de la máquina virtual que se implementan en la región
A, debes implementar Azure Key Vault en la región A para almacenar las claves de cifrado.
Antes de implementar cualquier servicio, debes comprobar si tus servicios de dependencia
están disponibles en esa región. La siguiente página del producto es una buena fuente para
comprobar la disponibilidad de los productos Azure en todas las regiones: https://azure.
microsoft.com/global-infrastructure/services.
Cumplimiento normativo relativo a datos y privacidad
Cada país cuenta con una regulación propia en términos de conformidad normativa sobre
datos y privacidad. Algunos países son muy específicos respecto al almacenamiento de los
datos de sus ciudadanos en sus propios territorios. Por tanto, estos requisitos legales se
deben tomar en consideración en la arquitectura de cada aplicación.
Rendimiento de las aplicaciones
El rendimiento de una aplicación depende de la ruta de red tomada por las solicitudes y las
respuestas para llegar a sus destinos y volver. La ubicación que está geográficamente más
cerca de ti puede no ser siempre la región con la latencia más baja. Calculamos la distancia
en kilómetros o millas, pero la latencia se basa en la ruta que usa el paquete. Por ejemplo,
una aplicación implementada en Europa occidental para usuarios en el sureste de Asia no
ofrecerá el mismo nivel de rendimiento que una aplicación implementada en la región de
Asia oriental para los usuarios de esa región. Por lo tanto, es muy importante que diseñes
tus soluciones en la región más cercana para proporcionar la menor latencia y, por lo tanto,
el mejor rendimiento.
Coste de ejecución de aplicaciones
El coste de los servicios de Azure puede variar entre una región y otra. Debe elegirse una
región con un coste total más reducido. En este libro, hay un capítulo completo sobre la
administración de costes (Capítulo 6, Administración de costes para soluciones de Azure)
y debe consultarse para obtener más información sobre los costes.
Hasta ahora, hemos analizado cómo elegir la región adecuada para diseñar nuestra solución.
Ahora que tenemos en mente una región adecuada para nuestra solución, veamos cómo
diseñar nuestras redes virtuales en Azure.
Redes virtuales
Las redes virtuales se deben concebir como una oficina física o una configuración de red
LAN doméstica. Conceptualmente, ambas son iguales, aunque la red virtual de Azure (VNet)
se implementa como una red definida por software y respaldada por una infraestructura
de red física gigante.
Se requiere una Vnet para hospedar una máquina virtual. Ofrece un medio de comunicación
seguro entre los recursos de Azure para que se puedan conectar entre sí. Las Vnet
proporcionan direcciones IP internas para los recursos, facilitan el acceso y la conectividad
a otros recursos (incluidas las máquinas virtuales de la misma red virtual), enrutan
solicitudes y ofrecen conectividad con otras redes.
Una red virtual se encuentra dentro de un grupo de recursos y está alojada dentro de una
región, por ejemplo, Europa occidental. No puede abarcar varias regiones, sino que puede
abarcar todos los centros de datos dentro de una región, lo que significa que podemos
abarcar redes virtuales en varias zonas de disponibilidad en una región. Para lograr la
conectividad entre todas las regiones, las redes virtuales pueden conectarse mediante
una conectividad entre redes virtuales (Vnet a Vnet).
Las redes virtuales también proporcionan conectividad a centros de datos on-premises lo
que habilita los clouds híbridos. Hay numerosos tipos de tecnologías VPN que puedes usar
para ampliar tus centros de datos on-premises al cloud, como VPN de sitio a sitio y VPN de
punto a sitio. Existe también una conectividad dedicada entre la red virtual de Azure y las
redes on-premises mediante el uso de ExpressRoute.
Las redes virtuales son gratuitas. Cada suscripción puede crear hasta 50 redes virtuales
en todas las regiones. No obstante, este número puede aumentarse si te pones en contacto
con el servicio de asistencia de Azure. No se te cobrará si los datos no salen de la región de
implementación. En el momento de redactar este documento, las transferencias de datos
entrantes y salientes dentro de las zonas de disponibilidad de la misma región no incurrirán
en cargos; sin embargo, la facturación comenzará a partir del 1 de julio de 2020.
La información sobre los límites de las conexiones de red está disponible en la
documentación de Microsoft en https://docs.microsoft.com/azure/azure-resourcemanager/
management/azure-subscription-service-limits.
Consideraciones de arquitectura para redes virtuales
Como cualquier otro recurso, las redes virtuales pueden aprovisionarse con plantillas de
ARM, API de REST, PowerShell y CLI. Es muy importante planificar la topología de red lo
antes posible para evitar problemas más adelante en el ciclo de vida de desarrollo. Esto
se debe a que, una vez que una red se aprovisiona y se empiezan a utilizar los recursos,
es difícil realizar modificaciones sin tiempos de inactividad. Por ejemplo, para mover
una máquina virtual de una red a otra será necesario apagar dicha máquina virtual.
Examinemos algunas de las consideraciones arquitectónicas clave durante el diseño de una
red virtual.
Regiones
VNet es un recurso de Azure y recibe aprovisionamiento dentro de una región, como
Europa occidental. Las aplicaciones que abarcan varias regiones necesitarán redes virtuales
separadas, una por cada región, además de estar conectadas utilizando la conectividad
Vnet a Vnet. Hay un coste asociado a esta conectividad, tanto para el tráfico de entrada
como para el de salida. No hay cargos para los datos de entrada (entrada), pero hay cargos
asociados con los datos de salida.
DNS dedicado
De manera predeterminada, las Vnet utilizan el DNS proporcionado por Azure para resolver
los nombres dentro de una red virtual, además de permitir la resolución de nombres en
Internet. Si una aplicación desea un servicio de resolución de nombres dedicado o desea
conectarse a centros de datos on-premises, debe aprovisionar su propio servidor DNS
que debe configurarse dentro de la red virtual para una resolución correcta de los nombres.
Además, puedes hospedar tu dominio público en Azure y administrar completamente los
registros desde Azure Portal, sin necesidad de administrar servidores DNS adicionales.
Número de redes virtuales
El número de redes virtuales se ve afectado por el número de regiones, el uso del ancho
de banda por parte de los servicios, la conectividad entre regiones y la seguridad. El hecho
de tener menos Vnet pero más grandes en lugar de varias Vnet más pequeñas eliminará la
sobrecarga administrativa.
Número de subredes en cada red virtual
Las subredes proporcionan aislamiento dentro de una red virtual. También pueden
proporcionar un límite de seguridad. Los grupos de seguridad de la red (NSG) pueden
asociarse a subredes de forma que restrinjan o permitan el acceso específico a puertos
y direcciones IP. Los componentes de aplicaciones con requisitos de accesibilidad y
seguridad separados deben ubicarse dentro de subredes separadas.
Intervalos de IP para redes y subredes
Cada subred tiene un intervalo de IP. El intervalo de IP no debe ser tan grande que las
direcciones IP estén infrautilizadas pero, por otro lado, no debería ser tan pequeño
que las subredes se asfixien por una falta de direcciones IP. Esto debe tenerse en cuenta
después de la comprensión de las necesidades de direcciones IP futuras de la implementación.
La planificación debe girar en torno a las direcciones IP y sus intervalos para los centros de
datos on-premises, las subredes y las redes de Azure. No deben producirse solapamientos
para así garantizar una conectividad y una accesibilidad perfectas.
Supervisión
La supervisión es un aspecto importante de la arquitectura, así como un elemento
fundamental que debe incluirse en la implementación general. Azure Network Watcher
ofrece funcionalidades de registro y diagnóstico con conocimientos sobre el estado y
el rendimiento de la red. Algunas de las capacidades de Azure Network Watcher son:
- Diagnosticar problemas de filtrado del tráfico de red hacia o desde una máquina virtual
- Descripción del próximo salto de las rutas definidas por el usuario
- Ver los recursos en una red virtual y sus relaciones
- Supervisión de la comunicación entre una máquina virtual y un punto de conexión
- Captura de tráfico de una máquina virtual
- Registros de flujo de NSG, que registra la información relacionada con el tráfico
que fluye a través de un NSG. Estos datos se almacenarán en Azure Storage para
su posterior análisis
También proporciona registros de diagnóstico para todos los recursos de red de un grupo
de recursos.
El rendimiento de la red se puede supervisar mediante Log Analytics. La solución
de administración Network Performance Monitor proporciona la capacidad de supervisión
de la red. Supervisa el estado, la disponibilidad y la accesibilidad de las redes. También
se utiliza para supervisar la conectividad entre cloud público y subredes on-premises
que hospedan varios niveles de una aplicación de varios niveles.
Cuestiones de seguridad
Las redes virtuales se encuentran entre los primeros componentes a los que tiene acceso
cualquier recurso en Azure. La seguridad desempeña un papel importante al permitir o
denegar acceso a un recurso. Los NSG son el principal medio de habilitación de seguridad
de las redes virtuales. Se pueden conectar a subredes de redes virtuales y todos los flujos
de entrada y salida se ven limitados, filtrados y permitidos por ellos.
El enrutamiento definido por el usuario (UDR) y el reenvío IP también ayudan a filtrar y
enrutar las solicitudes a recursos en Azure. Puedes obtener más información sobre el UDR
y la tunelización forzada en https://docs.microsoft.com/azure/virtual-network/virtualnetworks-
udr-overview.
Azure Firewall es una oferta de Firewall como servicio totalmente administrada de Azure.
Puede ayudarte a proteger los recursos de tu red virtual. Azure Firewall se puede utilizar
para el filtrado de paquetes en el tráfico entrante y saliente, entre otras cosas. Además,
la característica de inteligencia sobre amenazas de Azure Firewall se puede utilizar para
alertar y denegar tráfico procedente de o hacia dominios o direcciones IP malintencionados.
El origen de datos para direcciones IP y dominios es la fuente de inteligencia sobre
amenazas de Microsoft.
Los recursos también pueden estar asegurados y protegidos mediante la implementación
de dispositivos de red (https://azure.microsoft.com/solutions/network-appliances) como
Barracuda, F5 y otros componentes de terceros.
Implementación
Las redes virtuales deben implementarse en sus propios grupos de recursos dedicados.
Los administradores de red deben gozar del permiso del propietario para usar este grupo
de recursos, mientras que los desarrolladores o los miembros del equipo deben tener
permisos de colaborador para que se les permita crear otros recursos de Azure en otros
grupos de recursos que consumen servicios de la red virtual.
También se recomienda implementar recursos con direcciones IP estáticas en una subred
dedicada, mientras que los recursos relacionados con direcciones IP dinámicas pueden
ubicarse en otra subred.
Las políticas no solo deben crearse para que únicamente los administradores de red puedan
eliminar la red virtual, sino que también deben etiquetarse para facilitar la facturación.
Conectividad
Los recursos de una región de una red virtual pueden comunicarse perfectamente. Incluso
los recursos en otras subredes dentro de una misma red virtual pueden interactuar entre
sí sin necesidad de una configuración específica. Los recursos en varias regiones no pueden
utilizar la misma red virtual. La red virtual no pueden sobrepasar los límites de una región.
Para que un recurso se comunique entre regiones, necesitamos puertas de enlace dedicadas
en ambos extremos para facilitar la conversación.
Dicho esto, si quieres iniciar una conexión privada entre dos redes en diferentes regiones,
puedes utilizar el emparejamiento global de redes virtuales. Con el emparejamiento global
de redes virtuales, la comunicación se realiza a través de la red troncal de Microsoft, lo
que significa que no se requiere Internet público, puerta de enlace o cifrado durante la
comunicación. Si tus redes virtuales están en la misma región con diferentes espacios de
direcciones, los recursos de una red no podrán comunicarse con la otra. Puesto que están
en la misma región, podemos utilizar el emparejamiento de redes virtuales, que es similar
al emparejamiento global de redes virtuales; la única diferencia es que las redes virtuales
de origen y destino se implementan en la misma región.
Como muchas organizaciones tienen un cloud híbrido, los recursos de Azure a veces
necesitan comunicarse o conectarse con centros de datos on-premises o viceversa. Las
redes virtuales de Azure pueden conectarse a centros de datos on-premises con ayuda
de la tecnología VPN y ExpressRoute. De hecho, una red virtual puede conectarse a varios
centros de datos on-premises y otras regiones de Azure a la vez. Es recomendable que cada
una de estas conexiones se encuentre en sus subredes dedicadas dentro de una red virtual.
Ahora que hemos explorado varios aspectos de las redes virtuales, vamos a hablar sobre las
ventajas de las redes virtuales.
Ventajas de las redes virtuales
Las redes virtuales son un elemento fundamental en la implementación de cualquier solución
de IaaS significativa. Las máquinas virtuales no se pueden aprovisionar sin redes virtuales.
Además de ser un componente casi obligatorio en las soluciones de IaaS, proporcionan
grandes ventajas arquitectónicas, algunas de las cuales se describen a continuación:
- Aislamiento: la mayoría de los componentes de las aplicaciones presenta diferentes
requisitos de seguridad y ancho de banda y tiene una administración del ciclo de
vida diferente. Las redes virtuales ayudan a crear bolsas aisladas para que estos
componentes puedan administrarse de manera independiente de otros componentes
con la ayuda de las redes virtuales y las subredes. - Seguridad: el filtrado y el seguimiento de los usuarios que acceden a los recursos
son dos características importantes que ofrecen las redes virtuales. Pueden detener
el acceso a puertos y direcciones IP malintencionados. - Extensibilidad: las redes virtuales actúan como una red LAN privada en el cloud.
También pueden ampliarse hasta convertirse en una red de área extensa (WAN)
mediante la conexión con otras redes virtuales distribuidas por todo el mundo,
además de ampliarse como extensiones a centros de datos on-premises.
Hemos explorado las ventajas de las redes virtuales. Ahora la pregunta es cómo podemos
aprovechar estas ventajas y diseñar una red virtual para hospedar nuestra solución. En la
siguiente sección, vamos a examinar el diseño de redes virtuales.
Diseño de redes virtuales
En esta sección, tendremos en cuenta algunos diseños y escenarios de casos prácticos
populares de las redes virtuales.
Puede haber varios usos de las redes virtuales. Una puerta de enlace puede implementarse
en cada punto de conexión de la red virtual para habilitar la seguridad y transmitir paquetes
con integridad y confidencialidad. Una puerta de enlace es un elemento fundamental en
la conexión con redes on-premises; no obstante, es un componente opcional al usar el
emparejamiento de redes virtuales de Azure. Además, puedes utilizar la característica
Tránsito de puerta de enlace para simplificar el proceso de ampliar tu centro de datos
on-premises sin implementar varias puertas de enlace. Tránsito de puerta de enlace
permite compartir una puerta de enlace de ExpressRoute o VPN con todas las redes
virtuales emparejadas. Esto facilitará administrar y reducir el coste de la implementación
de varias puertas de enlace.
En la sección anterior, hemos hablado del emparejamiento y mencionado que no utilizamos
puertas de enlace ni Internet público para establecer la comunicación entre redes del mismo
nivel. Ahora pasemos a explorar algunos de los aspectos de diseño del emparejamiento y qué
necesidades de emparejamiento deben utilizarse en escenarios concretos.
Conectar con recursos dentro de la misma región y suscripción
Pueden conectarse entre sí varias redes virtuales dentro de la misma región y suscripción.
Con ayuda del emparejamiento de redes virtuales, ambas redes pueden conectarse y utilizar
la red troncal de la red privada de Azure para transmitir paquetes entre sí. Las máquinas
virtuales y los servicios en estas redes pueden comunicarse entre sí, aunque están sujetos
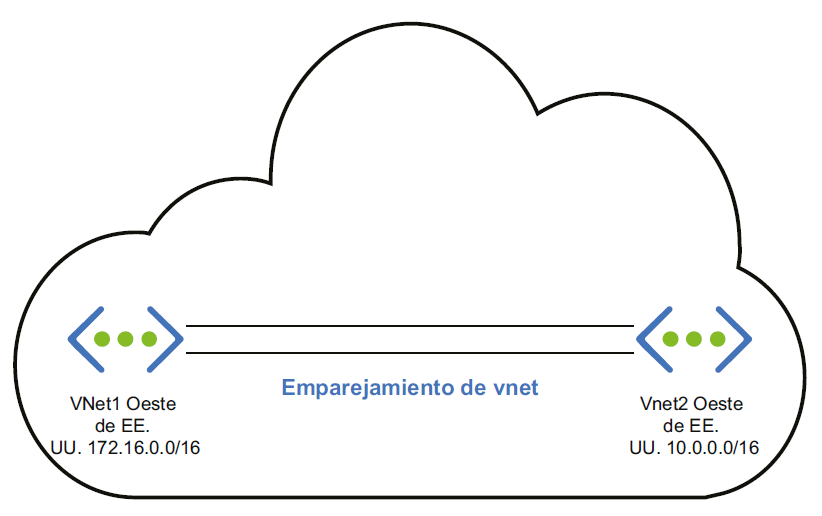
a las limitaciones del tráfico de la red. En el siguiente diagrama, tanto VNet1 como VNet2
se implementan en la región Oeste de EE. UU. Sin embargo, el espacio de direcciones de
VNet1 es 172.16.0.0/16 y de VNet2 es 10.0.0.0/16. De forma predeterminada, los recursos
de VNet1 no podrán comunicarse con los recursos de VNet2. Puesto que hemos establecido
el emparejamiento de redes virtuales entre los dos, los recursos serán capaces de
comunicarse entre sí a través de la red troncal de Microsoft:
Conectar con recursos dentro de la misma región y en otra suscripción
Este escenario es muy similar al anterior, con la excepción de que las redes virtuales
se hospedan en dos suscripciones diferentes. Las suscripciones pueden formar parte
del mismo inquilino o de varios. Si ambos recursos forman parte de la misma suscripción
y de la misma región, se aplica el escenario anterior. Este escenario se puede implementar
de dos maneras: mediante el uso de puertas de enlace o mediante el emparejamiento de
redes virtuales.
Si estamos utilizando puertas de enlace en este escenario, debemos implementar una puerta
de enlace en ambos extremos para facilitar la comunicación. A continuación se muestra la
representación arquitectónica de usar puertas de enlace para conectar dos recursos con
suscripciones diferentes:
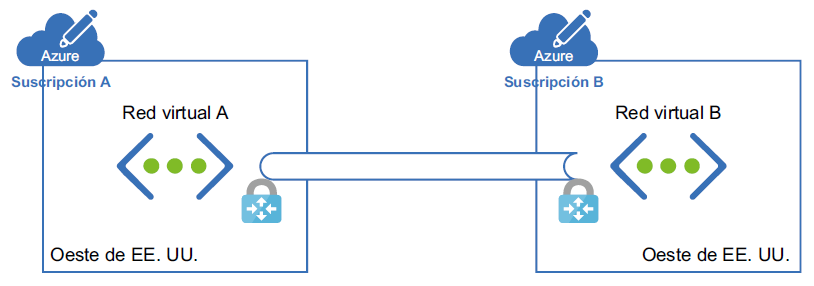
Sin embargo, la implementación de puertas de enlace conlleva algunos cargos. Hablaremos
sobre el emparejamiento de redes virtuales y después compararemos estas dos
implementaciones para ver cuál es la mejor para nuestra solución.
Mientras utilizamos el emparejamiento, no estamos implementando ninguna puerta
de enlace. En la Figura 3.3 se representa cómo se realiza el emparejamiento:
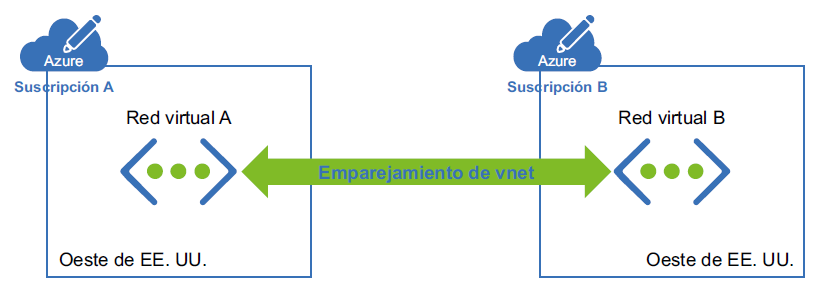
El emparejamiento de redes virtuales proporciona una conexión de baja latencia y alto
ancho de banda y, como se muestra en el diagrama, no estamos implementando ninguna
puerta de enlace para que se realice la comunicación. Esto resulta útil para escenarios como
la replicación de datos o la conmutación por error. Como se ha mencionado anteriormente,
el emparejamiento utiliza la red troncal de Microsoft, lo que elimina la necesidad de
Internet público.
Las puertas de enlace se utilizan en escenarios donde se necesita cifrado y el ancho de
banda no es un problema, ya que se trata de una conexión de ancho de banda limitado.
Sin embargo, esto no significa que haya una restricción del ancho de banda. Además,
este enfoque se utiliza cuando los clientes no son tan sensibles a la latencia.
Hasta ahora, hemos examinado los recursos en la misma región en todas las suscripciones.
En la siguiente sección, exploraremos cómo establecer una conexión entre redes virtuales
en dos regiones diferentes.
Conectar con recursos en diferentes regiones y en otra suscripción
En este escenario, tenemos dos implementaciones de nuevo. Una utiliza una puerta
de enlace y la otra utiliza el emparejamiento global de redes virtuales.
El tráfico pasará a través de la red pública y tendremos puertas de enlace implementadas en
ambos extremos para facilitar una conexión cifrada. En la Figura 3.4 se explica cómo se hace:
Vamos a utilizar un enfoque similar mediante el emparejamiento global de redes virtuales.
En la Figura 3.5 se muestra cómo se realiza el emparejamiento global de redes virtuales:

Las consideraciones al elegir puertas de enlace o emparejamiento ya se han analizado.
Estas consideraciones también son aplicables en este escenario. Hasta ahora, hemos estado
conectando redes virtuales entre regiones y suscripciones; aún no hemos hablado sobre la
conexión de un centro de datos on-premises al cloud. En la siguiente sección, explicaremos
los métodos para hacer esto.
Conectar con centros de datos on-premises
Las redes virtuales pueden conectarse con centros de datos on-premises, de manera que
los centros de datos on-premises y Azure se conviertan en una única red de área extensa
(WAN). Una red on-premises debe implementarse en puertas de enlace y VPN en ambos
extremos de la red. Hay tres tecnologías diferentes disponibles para este propósito.
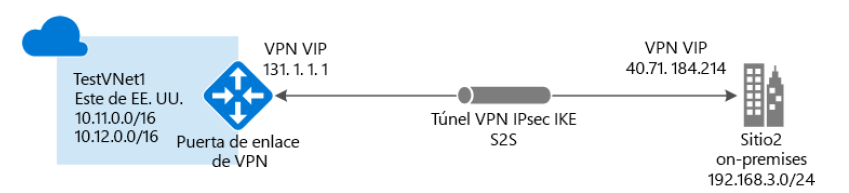
VPN de sitio a sitio
Esta tecnología debe usarse cuando la red de Azure y el centro de datos on-premises
estén conectados para formar una WAN en la que cualquier recurso en ambas redes
pueda acceder a cualquier otro recurso de las redes independientemente de si se han
implementado en Azure o en un centro de datos on-premises. Las puertas de enlace de
VPN deben estar disponibles en ambos extremos de las redes por motivos de seguridad.
Además, se deben implementar puertas de enlace de Azure en las subredes de las redes
virtuales conectadas con centros de datos on-premises. Las direcciones IP públicas deben
asignarse a puertas de enlace on-premises para que Azure pueda conectarse a ellas través
de la red pública:
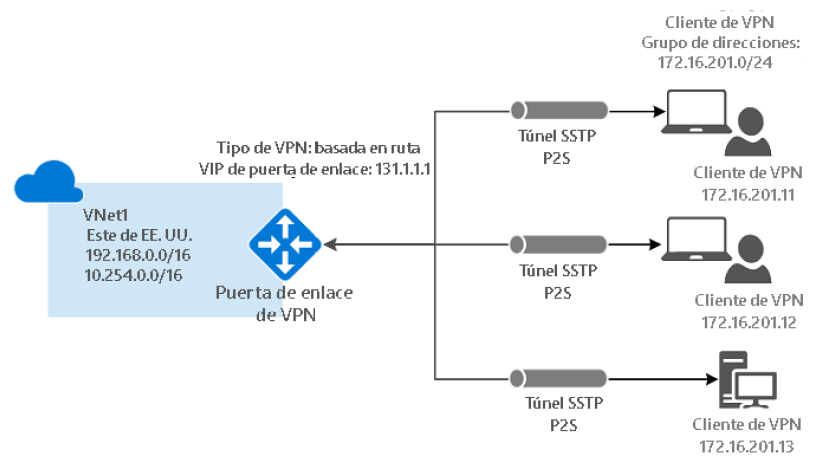
VPN de punto a sitio
Esta tecnología es similar a la conectividad VPN de sitio a sitio; sin embargo, hay un solo
servidor u ordenador conectado al centro de datos on-premises. Se debe usar cuando
haya algunos usuarios o clientes que deseen conectarse a Azure de forma segura desde
ubicaciones remotas. Además, en este caso no es necesario utilizar direcciones IP públicas
ni puertas de enlace en el centro de datos on-premises:
ExpressRoute
Tanto la tecnología VPN de sitio a sitio como la de punto a sitio funcionan a través
de Internet público. Cifran el tráfico en las redes con la tecnología VPN y la tecnología
de certificados. Sin embargo, hay aplicaciones que quieren implementarse mediante
tecnologías híbridas (algunos componentes en Azure, otros en un centro de datos
on-premises) y al mismo tiempo no desean usar Internet público para conectarse a
Azure y a los centros de datos on-premises. Azure ExpressRoute es la mejor solución
para estos casos, aunque implica un precio elevado en comparación con los otros dos
tipos de conexión. También es el proveedor más seguro y fiable, con mayor velocidad
y menor latencia porque el tráfico nunca llega al Internet público. Azure ExpressRoute
puede ayudar a ampliar las redes on-premises e integrarlas en Azure a través de una
conexión privada dedicada facilitada por un proveedor de conectividad. Si la solución
hace un uso intensivo de la red, por ejemplo, en una aplicación empresarial transaccional
como SAP, se recomienda encarecidamente el uso de ExpressRoute.
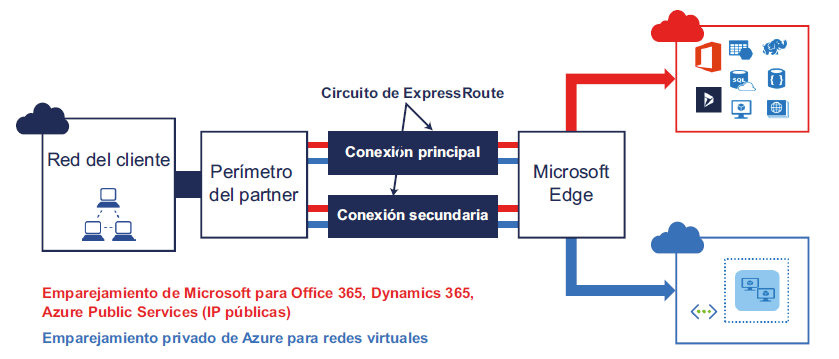
En la Figura 3.9 se muestran los tres tipos de redes híbridas:
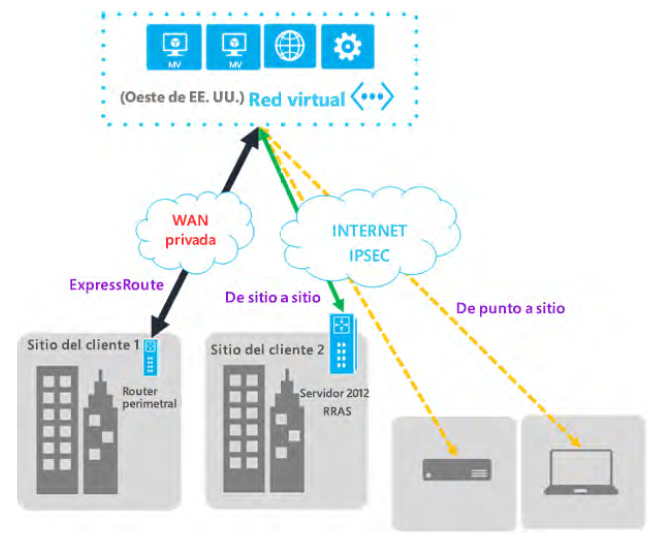
Desde una perspectiva de seguridad y aislamiento, se recomienda que las redes virtuales
tengan subredes independientes para cada componente lógico con implementaciones
separadas.
Todos los recursos que implementamos en Azure requieren redes de una manera u otra,
por lo que se requiere un profundo conocimiento de las redes al diseñar soluciones en
Azure. Otro elemento clave es el almacenamiento. En la siguiente sección, vas a aprender
más sobre el almacenamiento.
Almacenamiento
Azure proporciona una solución de almacenamiento duradera, de alta disponibilidad
y escalable a través de sus servicios de almacenamiento.
El almacenamiento se utiliza para almacenar datos a largo plazo. Azure Storage está
disponible en Internet para casi todos los lenguajes de programación.
Categorías de almacenamiento
La solución de almacenamiento se compone de dos categorías de cuentas de almacenamiento:
- Un nivel de rendimiento de almacenamiento estándar que permite almacenar tablas,
colas, archivos, blobs y discos de máquinas virtuales de Azure. - Un nivel de rendimiento de almacenamiento premium con capacidad para almacenar
discos de máquinas virtuales de Azure, en el momento de su escritura. El tipo de
almacenamiento premium ofrece un mayor rendimiento y operaciones de entrada/
salida por segundo (IOPS) que el almacenamiento general estándar. El nivel premium
está disponible actualmente en forma de discos de datos para máquinas virtuales que
cuentan con SSD.
En función del tipo de datos que se almacenen, el almacenamiento se clasifica en diferentes
tipos. Examinemos los tipos de almacenamiento y aprendamos más sobre ellos.
Tipos de almacenamiento
Azure proporciona cuatro tipos de servicios de almacenamiento general: - Azure Blob Storage: este tipo de almacenamiento es el más adecuado para
datos no estructurados, como documentos, imágenes y otros tipos de archivos.
El almacenamiento de blobs puede estar en el nivel de acceso frecuente, acceso
esporádico o de archivo. El nivel de acceso frecuente está diseñado para almacenar
datos a los que se debe acceder con mucha frecuencia. El nivel de acceso esporádico
se utiliza para datos a los que se accede con menos frecuencia que los datos del nivel
de acceso frecuente y se almacenan durante 30 días. Por último, el nivel de archivo
se utiliza para archivado cuando la frecuencia de acceso es muy baja. - Azure Table Storage: se trata de un almacén de datos de atributos clave NoSQL. Debe
utilizarse para datos estructurados. Los datos se almacenan en forma de entidades. - Azure Queue Storage: proporciona un almacenamiento fiable de mensajes para
almacenar un gran número de mensajes. Se puede acceder a estos mensajes desde
cualquier lugar a través de llamadas HTTP o HTTPS. Un mensaje de cola puede tener
un tamaño de hasta 64 KB.
- Azure Files: se trata de un almacenamiento compartido basado en el protocolo SMB.
Se utiliza normalmente para almacenar y compartir archivos. Con este tipo también
se almacenan datos no estructurados, pero la principal diferencia estriba en que
puede compartirse mediante el protocolo SMB. - Discos de Azure: se trata de un almacenamiento de nivel de bloque para Azure Virtual
Machines.
Estos cinco tipos de almacenamiento satisfacen diferentes necesidades de diseño y cubren
casi todos los tipos de instalaciones de almacenamiento de datos.
Características de almacenamiento
La solución Azure Storage es flexible. Es decir, puedes almacenar tan solo unos pocos
megabytes o hasta petabytes de datos. No es necesario bloquear previamente la capacidad,
ya que la solución aumentará y se reducirá automáticamente. Los consumidores solo tienen
que pagar por el uso real de almacenamiento. Estas son algunas de las principales ventajas
de usar Azure Storage:
- Azure Storage es una solución segura. Solo se puede acceder a ella con el protocolo
SSL. Además, dicho acceso debe autenticarse previamente. - Azure Storage permite generar un token Secure Access Signature (SAS) de nivel de
cuenta que puede ser utilizado por los clientes de almacenamiento para su autenticación.
También es posible generar tokens SAS de nivel de servicio individuales para blobs, colas,
tablas y archivos. - Los datos almacenados en Azure Storage pueden cifrarse. Esto se conoce como
asegurar datos en reposo. - Azure Disk Encryption se utiliza para cifrar el SO y los datos de los discos en máquinas
virtuales de IaaS. El cifrado en el cliente (CSE) y el cifrado del servicio Storage (SSE)
se utilizan para cifrar los datos en Azure Storage. SSE es un ajuste de Azure Storage que
garantiza que los datos se cifran al escribirse en el almacenamiento y que se descifran
cuando el motor de almacenamiento los lee. Por consiguiente, no es necesario realizar
ningún cambio en la aplicación para activar los SSE. En el modo CSE, las aplicaciones
cliente pueden utilizar Storage SDK para cifrar los datos antes de enviarlos y escribirlos
en Azure Storage. Más adelante, la aplicación cliente puede descifrar estos datos en
el momento en que se leen. Esto proporciona seguridad tanto a los datos en tránsito
como a los datos en reposo. CSE depende de los secretos de Azure Key Vault. - Azure Storage ofrece una alta disponibilidad, así como durabilidad. Esto significa
que Azure siempre conserva varias copias de las cuentas de Azure. La ubicación
y el número de copias dependen de la configuración de replicación.
Azure proporciona las siguientes opciones de configuración de replicación y redundancia
de datos:
- Almacenamiento con redundancia local (LRS): dentro de una única ubicación física
en la región principal, habrá tres réplicas de los datos de forma sincrónica. Desde
el punto de vista de la facturación, esta es la opción más económica; sin embargo,
no se recomienda para soluciones que requieran alta disponibilidad. LRS proporciona
un nivel de durabilidad del 99,999999999 % para objetos durante un año determinado. - Almacenamiento con redundancia de zona (ZRS): en el caso de LRS, las réplicas se
almacenaron en la misma ubicación física. En el caso de ZRS, los datos se replicarán
sincrónicamente en las zonas de disponibilidad de la región principal. Como cada una
de estas zonas de disponibilidad es una ubicación física independiente en la región
principal, ZRS proporciona una mayor durabilidad y mayor disponibilidad que LRS. - Almacenamiento con redundancia geográfica (GRS): GRS aumenta la alta disponibilidad
al replicar sincrónicamente tres copias de datos dentro de una sola región principal
mediante LRS. También copia los datos en una única ubicación física de la región
secundaria. - Almacenamiento con redundancia de zona geográfica (GZRS): es muy similar
a GRS, pero en lugar de replicar datos dentro de una única ubicación física en la
región principal, GZRS los replica sincrónicamente en tres zonas de disponibilidad.
Como hemos comentado en el caso de ZRS, dado que las zonas de disponibilidad
son ubicaciones físicas aisladas dentro de la región principal, GZRS tiene una mejor
durabilidad y se puede incluir en diseños de alta disponibilidad. - Almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS)
y almacenamiento con redundancia de zona geográfica con acceso de lectura: los
datos replicados en la región secundaria por GZRS o GRS no están disponibles para
lectura o escritura. La región secundaria usará estos datos en el caso de la conmutación
por error del centro de datos principal. RA-GRS y RA-GZRS siguen el mismo patrón de
replicación que GRS y GZRS, respectivamente; la única diferencia es que se pueden leer
los datos replicados en la región secundaria a través de RA-GRS o RA-GZRS.
Ahora que hemos comprendido las diversas opciones de almacenamiento y conexión
disponibles en Azure, vamos a conocer la arquitectura subyacente de la tecnología.
Consideraciones de arquitectura para cuentas de almacenamiento
Las cuentas de almacenamiento deben aprovisionarse dentro de la misma región que
la de otros componentes de la aplicación. Esto se traducirá en la utilización de la misma
red troncal de la red del centro de datos sin incurrir en cargos por utilización de red.
Los servicios de Azure Storage tienen objetivos de escalabilidad para capacidad,
velocidad de transacciones y ancho de banda asociados a cada uno de ellos. Una cuenta
de almacenamiento general permite un almacenamiento de hasta 500 TB de datos.
Si es necesario almacenar más de 500 TB de datos, se deben crear varias cuentas
de almacenamiento o utilizar un tipo de almacenamiento premium.
El rendimiento general del almacenamiento es, como máximo, de 20 000 IOPS o 60 MB
de datos por segundo. Se limitará cualquier requisito de un nivel de IOPS o datos
administrados por segundo superior. Si, en términos de rendimiento, esto no es suficiente
para tus aplicaciones, debes utilizar bien un almacenamiento premium o bien varias cuentas
de almacenamiento. Para una cuenta, el límite de escalabilidad para acceder a las tablas
es de hasta 20 000 (1 KB cada una) de entradas. El recuento de entidades que se insertan,
actualizan, eliminan o analizan contribuirá al objetivo. Una sola cola puede procesar
aproximadamente 2000 mensajes (1 KB cada uno) por segundo y cada uno de los recuentos
de AddMessage, GetMessage y DeleteMessage se tratará como un mensaje. Si estos valores
no son suficientes para tu aplicación, debes repartir los mensajes entre varias colas.
El tamaño de las máquinas virtuales determina el tamaño y la capacidad de los discos de
datos disponibles. Si bien las máquinas virtuales más grandes ofrecen discos de datos con
mayor capacidad para IOPS, la capacidad máxima seguirá estando limitada a 20 000 IOPS y
60 MB por segundo. Se debe recordar que estos son los niveles máximos y, por tanto, deberá
tenerse en cuenta el uso de niveles inferiores al finalizar la arquitectura de almacenamiento.
En el momento de redactar este documento, las cuentas GRS ofrecen un objetivo de ancho
de banda de 10 Gbps en EE. UU. para entrada y de 20 Gbps si RA-GRS/GRS está habilitado.
Cuando se trata de cuentas LRS, los límites están en el lado más alto en comparación
con GRS. En cuanto a las cuentas LRS, la entrada es de 20 Gbps y la salida es de 30 Gbps.
Fuera de EE. UU., los valores son menores: el objetivo de ancho de banda es de 10 Gbps
y de 5 Gbps para la salida. Si es necesario un mayor ancho de banda, puedes ponerte en
contacto con el soporte técnico de Azure y ellos podrán ayudarte con otras opciones.
Las cuentas de almacenamiento deben estar habilitadas para incluir la función de
autenticación con tokens SAS. No deben permitir el acceso anónimo. Por otra parte,
para el almacenamiento de blobs, deben crearse diferentes contenedores con tokens
SAS separados y basados en los diferentes tipos y las diferentes categorías de clientes
que acceden a dichos contenedores. Estos tokens SAS se deben regenerar periódicamente
para garantizar que las claves no estén en riesgo de ser adivinadas ni descifradas por nadie.
Aprenderás más sobre los tokens SAS y otras opciones de seguridad en el capítulo 8, Diseñar
aplicaciones seguras en Azure.
En general, los blobs recuperados para las cuentas de almacenamiento de blobs deben
almacenarse en caché. Podemos determinar si la caché está obsoleta al comparar su
propiedad de última modificación para volver a recuperar el último blob.
Las cuentas de almacenamiento ofrecen características de simultaneidad para garantizar
que el mismo archivo y los mismos datos no los modifiquen simultáneamente diferentes
usuarios. Ofrecen lo siguiente:
- Simultaneidad optimista: permite que varios usuarios modifiquen los datos a la vez,
pero durante la escritura realiza comprobaciones para ver si el archivo o los datos
se han modificado. En tal caso, se indica a los usuarios que deben volver a recuperar
los datos y realizar de nuevo la actualización. Esta es la función de simultaneidad
predeterminada para tablas. - Simultaneidad pesimista: cuando una aplicación intenta actualizar un archivo, emite
un bloqueo que niega explícitamente cualquier actualización por parte de otros
usuarios. Esta es la función de simultaneidad predeterminada para archivos cuando
se accede a estos con el protocolo SMB. - «El último en escribir gana»: las actualizaciones no están limitadas y el ultimo usuario
es el que actualiza el archivo independientemente de lo que se haya leído al principio.
Esta es la función de simultaneidad predeterminada para colas, blobs y archivos
(cuando se accede a estos con REST).
En este punto, debes saber cuáles son los diferentes servicios de almacenamiento y cómo
se pueden aprovechar en tus soluciones. En la siguiente sección, vamos a ver los patrones
de diseño y cómo se relacionan con los diseños arquitectónicos.
Patrones de diseño del cloud
Los patrones de diseño son soluciones probabas para abordar problemas de diseño
conocidos. Son soluciones reutilizables que se pueden aplicar a diversos problemas.
No son diseños ni código reutilizable que pueden incorporarse como parte de una
solución. Consisten en guías de orientación y descripciones documentadas para resolver
un problema. Un problema puede manifestarse en contextos diferentes y los patrones de
diseño pueden ayudar a resolverlo. Azure brinda numerosos servicios y cada uno ofrece
características y capacidades específicas. La utilización de estos servicios es sencilla, pero
la creación de soluciones que conforman estos múltiples servicios puede resultar todo
un desafío. Además, lograr ofrecer prestaciones como una alta disponibilidad, una elevada
escalabilidad, fiabilidad, rendimiento y seguridad para una solución no es una tarea trivial.
Los patrones de diseño de Azure proporcionan soluciones inmediatas que se pueden adaptar
a problemas individuales. Nos ayudan a crear soluciones altamente disponibles, escalables,
fiables, seguras y centradas en el rendimiento en Azure. Aunque hay muchos patrones y
algunos de ellos se describen con mayor detalle en capítulos posteriores, en este capítulo
abordaremos algunos de los patrones de mensajería, rendimiento y escalabilidad. Incluiremos,
además, enlaces a descripciones más detalladas de estos patrones. Estos patrones de diseño
merecen un libro completo por sí mismos. Se han mencionado en este capítulo para que
puedas conocer su existencia y para ofrecer referencias con información adicional.
Patrones de mensajería
Los patrones de mensajería ayudan a conectar servicios de forma flexible. Esto quiere decir
que los servicios nunca se comunican directamente entre sí. Por el contrario, un servicio
genera y envía un mensaje a un agente (generalmente una cola) y cualquier otro servicio
que esté interesado en dicho mensaje puede recogerlo y procesarlo. No se establece
ninguna comunicación directa entre el servicio emisor y el receptor. Este desacoplamiento
no solo hace que los servicios y la aplicación general sean más fiables, sino que también los
convierte en una solución más sólida y tolerante a errores. Los receptores pueden recibir
y leer mensajes a su propia velocidad.
La mensajería ayuda en la creación de patrones asincrónicos. Esta implica enviar mensajes
de una entidad a otra. Estos mensajes los crea y envía un remitente, se almacenan en un
sistema de almacenamiento duradero y, finalmente, los consumen los destinatarios.
Los principales aspectos arquitectónicos que abordan los patrones de mensajería son los
siguientes:
- Durabilidad: los mensajes se almacenan en un sistema de almacenamiento duradero
y las aplicaciones pueden leerlos después de recibirlos en caso de conmutación
por error. - Fiabilidad: los mensajes ayudan a implementar la fiabilidad ya que se conservan en
el disco y nunca se pierden. - Disponibilidad de los mensajes: los mensajes están disponibles para su consumo por
parte de las aplicaciones después de la restauración de la conectividad y antes de un
periodo de inactividad.
Azure proporciona temas y colas de Service Bus para implementar patrones de mensajería
dentro de las aplicaciones. Azure Queue Storage también puede utilizarse para el mismo
propósito.
La elección entre las colas de Azure Service Bus y Queue Storage consiste en decidir la
duración de almacenamiento del mensaje, el tamaño del mensaje, la latencia y el coste.
Azure Service Bus permite mensajes de 256 KB, mientras que Queue Storage permite
mensajes de 64 KB. Azure Service Bus puede almacenar mensajes durante un periodo
de tiempo ilimitado y Queue Storage puede almacenar mensajes durante siete días.
El coste y la latencia son más altos en el caso de las colas de Service Bus.
En función de tus necesidades y los requisitos de la aplicación, debes tener en cuenta
los factores anteriores antes de decidir la cola más adecuada. En la siguiente sección,
analizaremos diferentes tipos de patrones de mensajería.
Patrón de consumidores en competencia
Un solo consumidor de mensajes trabaja de manera sincrónica, a menos que la aplicación
implemente la lógica de lectura de mensajes de forma asincrónica. El patrón de consumidores
en competencia implementa una solución en la que varios consumidores están listos para
procesar mensajes entrantes y compiten para procesar cada mensaje. Esto puede dar lugar
a soluciones altamente disponibles y escalables. Esta patrón es escalable porque, con varios
consumidores, se puede procesar un mayor número de mensajes en un menor periodo de
tiempo. Y ofrece una alta disponibilidad porque debe haber al menos un consumidor para
procesar los mensajes, incluso si alguno de ellos se bloquea.
Este patrón debe usarse cuando los mensajes sean independientes unos de otros. Los
mensajes por sí mismos contienen toda la información necesaria para que un consumidor
pueda llevar a cabo una tarea. Este patrón no debe utilizarse si no hay ninguna dependencia
entre mensajes. Los consumidores deben ser capaces de realizar las tareas de manera
aislada. Además, este patrón puede aplicarse en casos de servicios con demanda variable.
Según la demanda, pueden agregarse o quitarse consumidores adicionales.
Es necesaria una cola de mensajes para implementar el patrón de consumidores en
competencia. En este patrón, los patrones procedentes de varias fuentes pasan por
una única cola, que está conectada a varios consumidores en el otro extremo. Estos
consumidores borran cada mensaje después de leerlo para que no se vuelva a procesar:
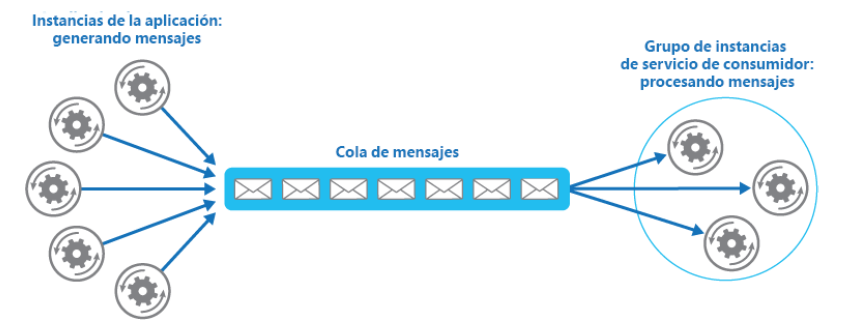
Consulta la documentación de Microsoft en https://docs.microsoft.com/azure/architecture/
patterns/competing-consumers para obtener más información sobre este patrón.
Patrón de colas de prioridad
A menudo es necesario priorizar algunos mensajes sobre otros. Este patrón es importante
para aplicaciones que ofrecen diferentes acuerdos de nivel de servicio (SLA) a los
consumidores, los cuales prestan servicios basados en planes diferenciales y suscripciones.
Las colas siguen el patrón «primero en entrar, primero en salir». Los mensajes se procesan
de manera secuencial. Sin embargo, con la ayuda del patrón de colas de prioridad, es posible
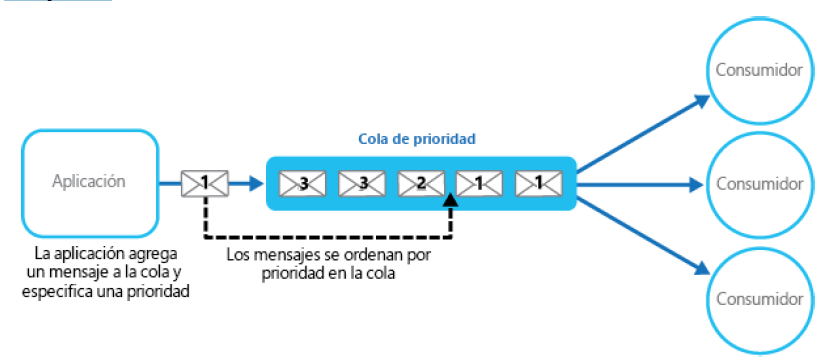
el procesamiento acelerado de algunos mensajes debido a su mayor prioridad. Existen varias
maneras de implementar este patrón. Si la cola te permite asignar prioridad y reorganizar
mensajes según su prioridad, puede que una única cola sea suficiente para implementar
este patrón:
No obstante, si la cola puede reorganizar mensajes, puedes crear colas independientes para
las diferentes prioridades y cada cola puede tener asociados consumidores separados:
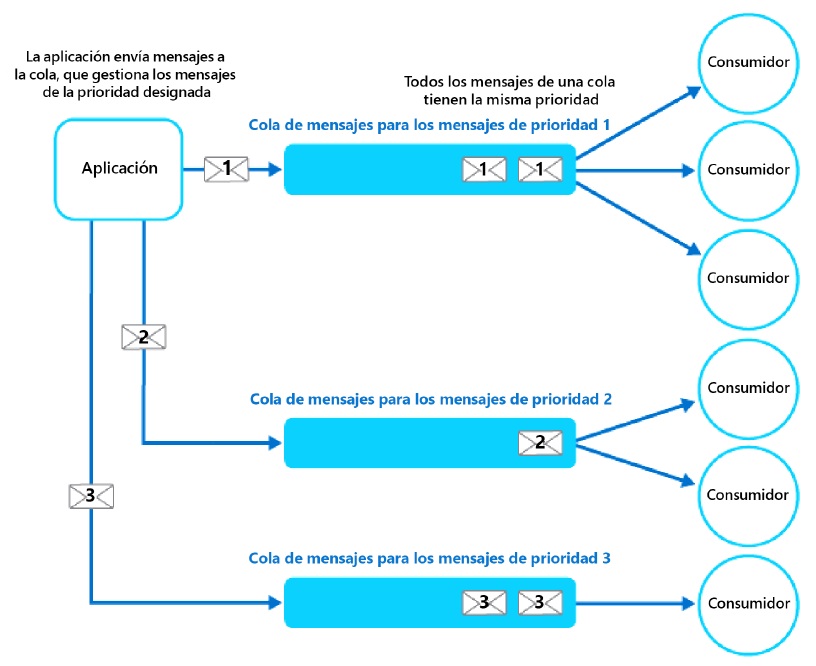
De hecho, si es necesario, este patrón puede usar el patón de consumidores en competencia
para un procesamiento acelerado de mensajes de cada cola que utilice varios consumidores.
Consulta la documentación de Microsoft en https://docs.microsoft.com/azure/
architecture/patterns/priority-queue para obtener más información sobre el patrón
de colas de prioridad.
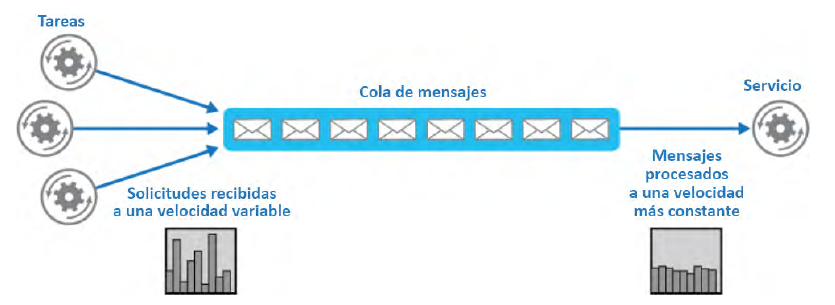
Patrón de nivelación de carga basada en cola
El patrón de nivelación de carga basada en cola reduce el impacto de los picos de demanda
en la disponibilidad y la alerta de tareas y servicios. Entre una tarea y un servicio, una cola
actuará como búfer. Se puede invocar para gestionar las cargas elevadas inesperadas que
pueden provocar interrupciones del servicio o tiempos de espera. Este patrón ayuda a
solucionar problemas de rendimiento y fiabilidad. Para evitar que el servicio se sobrecargue,
introduciremos una cola que almacenará un mensaje hasta que el servicio lo recupere.
El servicio tomará los mensajes de la cola de manera coherente y los procesará.
En la Figura 3.13 se muestra cómo funciona el patrón de nivelación de carga basada en cola:
Aunque este patrón ayuda a gestionar picos de demanda inesperados, no es la mejor opción
cuando se está diseñando un servicio con una latencia mínima. Con respecto a la latencia,
que es una medición del rendimiento, en la siguiente sección nos centraremos en los
patrones de rendimiento y escalabilidad.
Patrones de rendimiento y escalabilidad
El rendimiento y la escalabilidad van juntos. El rendimiento es la medida de la rapidez con
la que un sistema puede ejecutar una acción en un intervalo de tiempo determinado de
forma positiva. Por otro lado, la escalabilidad es la capacidad de un sistema para gestionar
una carga inesperada sin afectar al rendimiento del sistema o la rapidez con la que se
puede ampliar el sistema con los recursos disponibles. En esta sección, se describen
un par de patrones de diseño relacionados con el rendimiento y la escalabilidad.
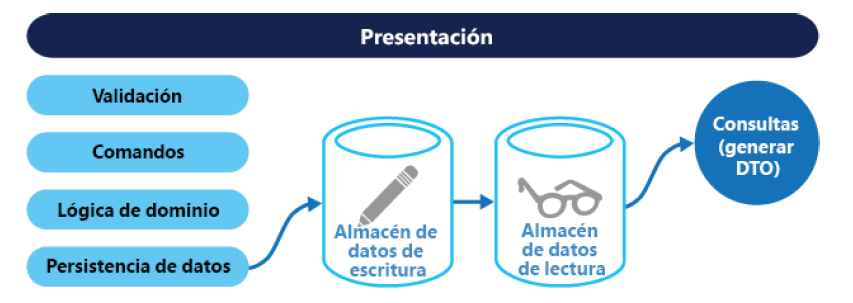
Patrón CQRS (Command and Query Responsibility Segregation)
CQRS no es un patrón específico de Azure, sino un patrón general que se puede aplicar
en cualquier aplicación. Aumenta el rendimiento general y la capacidad de respuesta
de una aplicación.
CQRS es un patrón que separa las operaciones que leen datos en una aplicación (consultas)
de las operaciones que actualizan datos (comandos) mediante interfaces separadas. Esto
significa que los modelos de datos que se utilizan para realizar consultas y actualizaciones
son diferentes. Por tanto, los modelos se pueden aislar, como se muestra en la Figura 3.14,
aunque esto no sea un requisito absoluto.
Este patrón debe usarse cuando se ejecutan reglas de negocio grandes y complejas
al actualizar y recuperar datos. Además, este patrón tiene un excelente caso práctico en
el que un equipo de desarrolladores puede centrarse en el modelo de dominios complejos
que forma parte del modelo de escritura y otro equipo puede centrarse en el modelo de
lectura y las interfaces de usuario. También es prudente utilizar este patrón cuando la
relación de lectura y escritura está sesgada. El rendimiento de las lecturas de datos debe
ajustarse por separado del rendimiento de las escrituras de datos.
El patrón CQRS no solo mejora el rendimiento de una aplicación, sino que también ayuda en
el diseño y la implementación de varios equipos. Debido a su naturaleza de uso de modelos
separados, CQRS no es adecuado si utilizas herramientas de generación de modelos
y Scaffold:
Consulta la documentación de Microsoft en https://docs.microsoft.com/azure/
architecture/patterns/cqrs para obtener más información sobre este patrón.
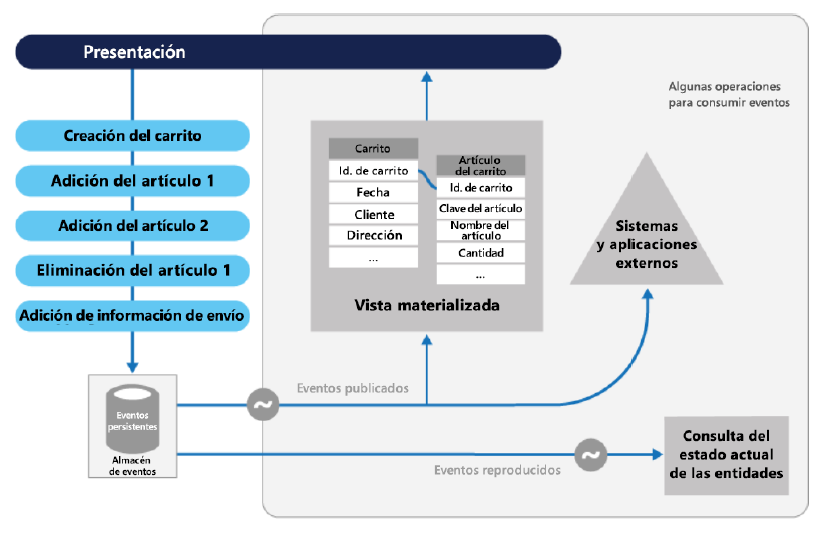
Patrón de abastecimiento de eventos
Como la mayoría de las aplicaciones trabajan con datos y los usuarios trabajan con ellos,
el enfoque clásico para la aplicación sería mantener y actualizar el estado actual de los datos.
Leer datos del origen, modificarlos y actualizar el estado actual con el valor modificado es
el enfoque de procesamiento de datos típico. Sin embargo, existen algunas limitaciones:
- A medida que las operaciones de actualización se realizan directamente en el almacén
de datos, esto ralentizará el rendimiento general y la capacidad de respuesta. - Si hay varios usuarios trabajando en los datos y actualizándolos, se pueden producir
conflictos y algunas de las actualizaciones pertinentes pueden fallar.
La solución es implementar el patrón de abastecimiento de eventos, donde los cambios se
registrarán en un almacén solo de anexos. El código de la aplicación insertará una serie de
eventos en el almacén de eventos, donde se conservarán. Los eventos persistentes en un
almacén de eventos actúan como un sistema de registro sobre el estado actual de los datos.
Se notificará a los consumidores y estos pueden gestionar los eventos si es necesario una
vez que se publiquen.
El patrón de abastecimiento de eventos se muestra en la Figura 3.15:
Hay disponible más información sobre este patrón en https://docs.microsoft.com/azure/
architecture/patterns/event-sourcing.
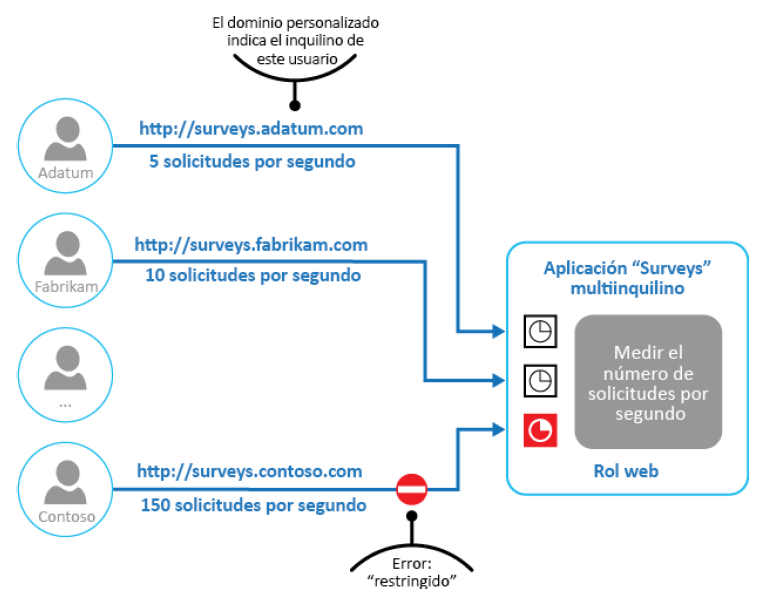
Patrón de limitación
A veces, hay aplicaciones que tienen requisitos de SLA muy estrictos en cuanto a
rendimiento y escalabilidad, independientemente del número de usuarios que consuman
el servicio. En estas circunstancias, es importante implementar el patrón de limitación
porque este puede limitar el número de solicitudes que se permite ejecutar. La carga
en las aplicaciones no se puede predecir con precisión en todas las circunstancias. Cuando
la carga en una aplicación alcanza su nivel máximo, la limitación reduce la presión sobre los
servidores y los servicios mediante el control del consumo de recursos. La infraestructura
de Azure es un buen ejemplo de este patrón.
Este patrón debe utilizarse cuando el cumplimiento del SLA sea una prioridad para las
aplicaciones con el fin de evitar que algunos usuarios consuman más recursos de los que
tienen asignados, además de optimizar los picos de demanda y optimizar los costes en
relación con el consumo de recursos. Estos son escenarios plausibles para aplicaciones
diseñadas para su implementación en el cloud.
Puede haber múltiples estrategias para controlar la limitación en una aplicación. La estrategia
de limitación puede rechazar nuevas solicitudes una vez que se supere un umbral o bien
puede comunicar al usuario que su solicitud está en cola y que tendrá la oportunidad de
ejecutarse cuando se reduzca el número de solicitudes.
En la Figura 3.16 se ilustra la implementación del patrón de limitación en un sistema
multiinquilino donde a cada inquilino se le asigna un límite de utilización de recursos fijo.
Cuando se exceda este límite, se restringirá cualquier demanda adicional de recursos,
con lo que se logrará mantener unos recursos suficientes para otros inquilinos:
Puedes obtener más información sobre este patrón en https://docs.microsoft.com/azure/
architecture/patterns/throttling.
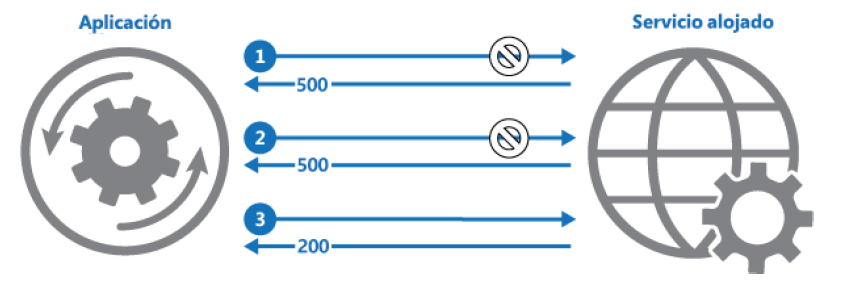
Patrón de reintento
El patrón de reintento es un patrón extremadamente importante que permite que las
aplicaciones y los servicios ofrezcan una mayor resistencia a fallos transitorios. Imagina
una situación en la que intentas conectar a un servicio y utilizarlo, y el servicio no está
disponible por cualquier motivo. Si el servicio va a estar disponible pronto, tiene sentido
seguir intentando lograr establecer una conexión. Esto hace que la aplicación sea más
sólida, tolerante a errores y estable. En Azure, la mayoría de los componentes se ejecuta
en Internet y esa conexión a Internet puede experimentar errores transitorios de manera
intermitente. Dado que estos fallos se pueden corregir en cuestión de segundos, no
se debería permitir que una aplicación quedase bloqueada. La aplicación debe diseñarse
de manera que implique que puede intentar repetidamente volver a utilizar el servicio
en caso de error y dejar de reintentarlo cuando logra hacerlo o, finalmente, determine
que hay un error que llevará tiempo rectificar.
Este patrón debe implementarse cuando una aplicación pueda experimentar errores
transitorios al interactuar con un servicio remoto o acceder a un recurso remoto. Se
espera que estos errores sean de corta duración y que la repetición de una solicitud
que previamente ha fallado pueda llevarse a cabo correctamente en un intento posterior.
El patrón de reintento puede adoptar diferentes estrategias de reintento en función de
la naturaleza de los errores y de la aplicación:
- Número fijo de intentos: indica que la aplicación intentará comunicarse con el
servicio un número concreto de veces antes de que pueda determinar que hay un fallo
y emitir una excepción. Por ejemplo, volverá a intentar conectarse a otro servicio tres
veces. Si se establece una conexión correctamente en unos de estos tres intentos,
se considerará que la operación se ha llevado a cabo correctamente; no obstante,
después de que hayan transcurrido estos tres intentos, se emitirá una excepción. - Reintento basado en horario: indica que la aplicación intentará comunicarse con
el servicio repetidamente durante un número determinado de segundos o minutos
y esperará a que haya transcurrido un número determinado de segundos o minutos
antes de volver a intentarlo. Por ejemplo, la aplicación intentará conectarse al servicio
cada tres segundos durante 60 segundos. Si se conecta correctamente en este
tiempo, toda la operación se realizará correctamente. De lo contrario, se emitirá
una excepción. - Aplazamiento y retardo del reintento: indica que la aplicación intentará comunicarse
con el servicio repetidamente basándose en un periodo de tiempo y que seguirá
agregando un retardo incremental en los intentos posteriores. Por ejemplo, durante
un total de 60 segundos, el primer reintento se producirá después de un segundo;
el segundo reintento, dos segundos después del reintento anterior; el tercero, cuatro
segundos después del último intento; y así sucesivamente. De esta forma, se logra
reducir el número total de reintentos.
En la Figura 3.17 se ilustra el patrón de reintento. La primera solicitud obtiene una respuesta
HTTP 500, el segundo reintento vuelve a obtener una respuesta HTTP 500 y, por último,
la solicitud se realiza correctamente y obtiene HTTP 200 como respuesta:
Consulta la siguiente documentación de Microsoft en https://docs.microsoft.com/azure/
architecture/patterns/retry para obtener más información sobre este patrón.
Patrón de interruptor de circuito
Se trata de un patrón muy útil. Imagina de nuevo una situación en la que intentas conectar
a un servicio y utilizarlo, y el servicio no está disponible por cualquier motivo. Si el servicio
no va a estar disponible pronto, no tiene sentido seguir reintentando la conexión. Por
otra parte, mantener ocupados otros recursos mientras se realizan reintentos supone
un desperdicio de muchos recursos que potencialmente podrían estar siendo utilizados
para otros fines.
El patrón de interruptor de circuito ayuda a eliminar este desperdicio de recursos. Se puede
evitar que las aplicaciones intenten reiteradamente conectarse y utilizar un servicio que
no está disponible. También ayuda a las aplicaciones a detectar si el servicio vuelve a estar
activo y en funcionamiento y permite que las aplicaciones se conecten a él.
Para implementar el patrón de interruptor de circuito, todas las solicitudes al servicio deben
pasar a través de un servicio que actúe como proxy en relación con el servicio original. El
objetivo de este servicio de proxy es mantener una máquina de estados y actuar como una
puerta de enlace al servicio original. Hay tres estados que mantiene. Podría incorporar más
estados, según los requisitos de la aplicación.
Los estados mínimos necesarios para implementar este patrón son los siguientes:
- Open: indica que el servicio está inactivo y la aplicación muestra una excepción
inmediatamente en lugar de permitir un reintento o esperar a que transcurra el tiempo
de espera. Cuando el servicio vuelve a estar activo, el estado pasa al estado Half-Open. - Closed: este estado indica que el servicio funciona correctamente y que la aplicación
puede seguir adelante y conectarse a él. Por lo general, se muestra un contador del
número de fallos antes de que pueda pasar al estado Open. - Half-Open: en algún momento, cuando el servicio esté activo y funcionando, este
estado permitirá que un número limitado de solicitudes pasen a través de él. Este
estado es una prueba decisiva que comprueba si las solicitudes que pasan a través de
este se llevan a cabo correctamente o no. Si las solicitudes se realizan correctamente,
el estado cambia de Half-Open a Closed. Este estado también puede implementar
un contador para permitir que solo se lleven a cabo un número determinado de
solicitudes antes de que se pueda pasar a Closed.
Los tres estados y sus transiciones se ilustran en la Figura 3.18:
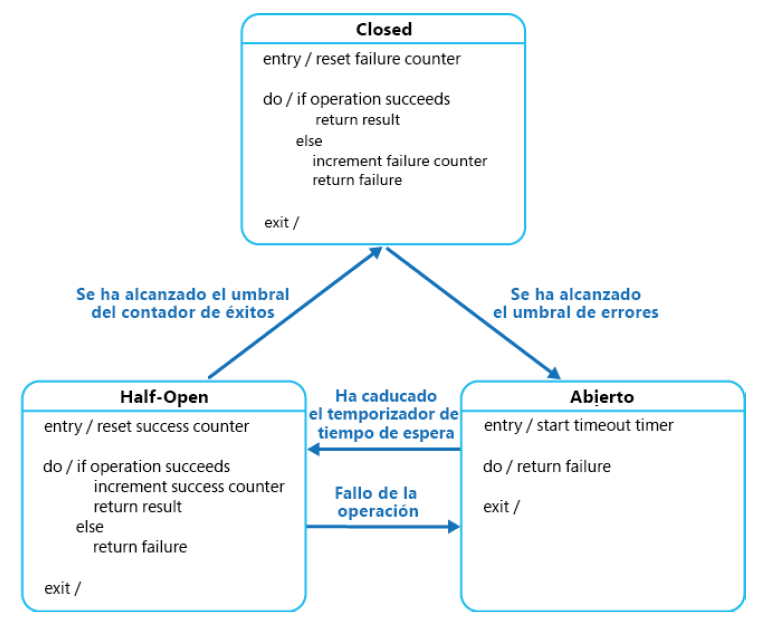
Lee más sobre este patrón en la documentación de Microsoft en https://docs.microsoft.
com/azure/architecture/patterns/circuit-breaker.
En esta sección, hemos analizado patrones de diseño que se pueden usar para diseñar
aplicaciones fiables, escalables y seguras en el cloud. Sin embargo, hay otros patrones
que puedes explorar en https://docs.microsoft.com/azure/architecture/patterns.
Resumen
Hay numerosos servicios disponibles en Azure y la mayoría de ellos puede combinarse para
crear soluciones reales. En este capítulo se han explicado los tres servicios más importantes
que proporciona Azure: las regiones, el almacenamiento y las redes. Estos conforman
casi la totalidad de las soluciones implementadas en todos los clouds. Este capítulo ha
proporcionado detalles acerca de estos servicios y acerca de cómo su configuración
y aprovisionamiento pueden afectar a las decisiones de diseño.
Las consideraciones importantes que hay que tener en cuenta en términos de almacenamiento
y redes se han descrito en este capítulo. Tanto las redes como los almacenamientos ofrecen un
gran número de opciones y, por tanto, es esencial elegir una configuración apropiada según
tus requisitos.
Finalmente, se han descrito algunos de los patrones de diseño más importantes relacionados
con la mensajería, como los consumidores en competencia, las colas de prioridad y la nivelación
de carga. También se han explicado los patrones relacionados con CQRS y la limitación, junto
con otros patrones como los patrones de reintento y de interruptor de circuito. Guardaremos
estos patrones como la línea de referencia cuando implementemos nuestras soluciones.
En el siguiente capítulo, analizaremos cómo automatizar las soluciones que vamos a diseñar.
A medida que avanzamos en el mundo de la automatización, todas las organizaciones quieren
eliminar la sobrecarga de crear recursos uno por uno, lo cual es muy exigente. Como la
automatización es la solución para esto, en el siguiente capítulo aprenderás más sobre ella.