



¡Los eventos están en todas partes! Cualquier actividad o tarea que cambie el estado de un elemento de trabajo genera un evento. Debido a la falta de infraestructura y a la no disponibilidad de dispositivos baratos, anteriormente no había mucha simpatía hacia el Internet de las cosas (IoT). Tradicionalmente, las organizaciones utilizaban entornos hospedados en proveedores de servicios de Internet (ISP) que solo tenían sistemas de supervisión sobre ellos. Estos sistemas de supervisión generaban eventos que eran escasos y aislados.
Sin embargo, con la llegada del cloud, las cosas están cambiando con rapidez. Con el aumento de las implementaciones en el cloud, especialmente de servicios de plataforma como servicio (PaaS), las organizaciones ya no necesitan disponer de un gran control sobre el hardware y la plataforma, y ahora cada vez que hay un cambio en un entorno, se genera un evento. Con la aparición de eventos en el cloud, IoT ha cobrado una mayor importancia y los eventos han comenzado a acaparar protagonismo.
Otro fenómeno reciente que se ha producido ha sido el rápido estallido de crecimiento en la disponibilidad de datos. La velocidad, la variedad y el volumen de datos han repuntado al igual que lo ha hecho la necesidad de soluciones para almacenar y procesar datos. Han aparecido múltiples soluciones y plataformas, como Hadoop, data lakes para almacenamiento, data lakes para análisis y servicios de machine learning.
Además de almacenamiento y análisis, también hay una necesidad de servicios que sean
capaces de ingerir millones de millones de eventos y mensajes de diversos orígenes.
Asimismo, también hay una necesidad de servicios que puedan trabajar en datos
temporales, en lugar de trabajar con la instantánea completa de datos. Por ejemplo, los
datos de eventos/datos de IoT se utilizan en aplicaciones que toman decisiones basadas en
datos en tiempo real o casi en tiempo real, como sistemas de gestión del tráfico o sistemas
que supervisan la temperatura.
Azure proporciona una gran cantidad de servicios que ayudan a capturar y analizar datos
en tiempo real de los sensores. En este capítulo, analizaremos un par de servicios de
eventos en Azure, como se indica aquí:
- Azure Event Hubs
- Azure Stream Analytics
Hay otros servicios de eventos, como Azure Event Grid, que no se tratan en este capítulo;
sin embargo, se han abordado ampliamente en el capítulo 10, Azure Integration Services con
funciones de Azure (Durable Functions y funciones de proxy).
Introducción a los eventos
Los eventos son construcciones importantes tanto en Azure como en la arquitectura
de aplicaciones de Azure. Los eventos están en todas partes dentro del ecosistema de
software. En general, cualquier acción que se realice da como resultado un evento que se
puede capturar y, a continuación, se puede realizar una nueva acción. Para avanzar en esta
explicación, es importante comprender primero los conceptos básicos de los eventos.
Los eventos ayudan a capturar el nuevo estado de un recurso de destino. Un mensaje es una
notificación ligera de una condición o un cambio de estado. Los eventos son diferentes a los
mensajes. Los mensajes están relacionados con la funcionalidad del negocio, como el envío
de detalles de pedido a otro sistema. Contienen datos sin procesar y pueden ser de gran
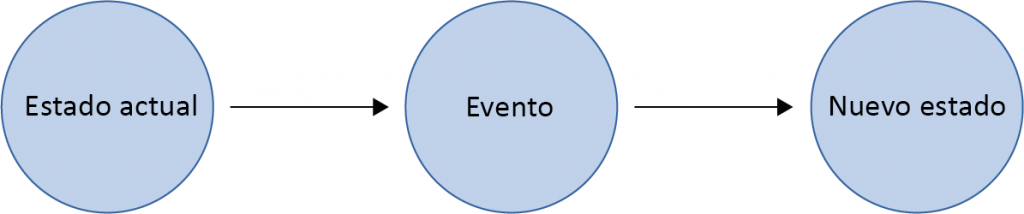
tamaño. Si los comparamos, los eventos son diferentes; por ejemplo, una máquina virtual
que se está deteniendo es un evento. En la Figura 12.1 se muestra esta transición del estado
actual al estado de destino:
Los eventos se pueden almacenar en un almacenamiento duradero, ya que los datos y eventos
históricos también se pueden utilizar para encontrar patrones que están surgiendo de forma
continua. Los eventos se pueden considerar datos que se transmiten constantemente. Para
capturar, ingerir y realizar análisis de una secuencia de datos, se necesitan componentes de
infraestructura especiales que puedan leer una pequeña ventana de datos y proporcionar
conocimientos, y ahí es donde entra en escena el servicio Stream Analytics.
Streaming de eventos
El procesamiento de eventos a medida que se ingieren y se transmiten durante un periodo
de tiempo proporciona información en tiempo real sobre los datos. El periodo de tiempo
podría ser de 15 minutos o una hora: el periodo lo define el usuario y depende de la
información que se extraiga de los datos. Tomemos, por ejemplo, las lecturas de las tarjetas
de crédito: cada minuto se realizan millones de lecturas de tarjetas de crédito y se puede
llevar a cabo la detección de fraudes a través de eventos transmitidos durante un periodo
de uno o dos minutos.
El streaming de eventos hace referencia a servicios que pueden aceptar los datos cuando
surgen, en lugar de aceptarlos periódicamente. Por ejemplo, los flujos de eventos deben ser
capaces de aceptar información de temperatura de dispositivos cuando la envían, en lugar
de hacer que los datos esperen en una cola o en un entorno de ensayo.
El streaming de eventos también tiene la capacidad de consultar los datos durante el tránsito.
Se trata de datos temporales que se almacenan durante un tiempo y las consultas se producen
en los datos en movimiento; por lo tanto, los datos no son estacionarios. Esta capacidad no
está disponible en otras plataformas de datos, que solo pueden consultar datos almacenados
y no datos temporales que acaban de ingerirse.
Los servicios de streaming de eventos deben poder escalar fácilmente para aceptar millones
o incluso miles de millones de eventos. Deben estar altamente disponibles para que los
orígenes puedan enviarles eventos y datos en cualquier momento. La ingesta de datos
en tiempo real y la posibilidad de trabajar en esos datos, en lugar de en datos que están
almacenados en una ubicación diferente, es la clave para el streaming de eventos.
Sin embargo, cuando ya contamos con tantas plataformas de datos con capacidades
avanzadas de ejecución de consultas, ¿por qué necesitamos el streaming de eventos?
Una de las principales ventajas del streaming de eventos es que proporciona conocimientos
e información en tiempo real cuya utilidad depende del tiempo. La misma información
encontrada después de unos minutos u horas podría no ser tan útil. Veamos algunos
escenarios en los que es muy importante trabajar con datos entrantes. Estos escenarios no
se pueden resolver de forma eficaz y eficiente mediante las plataformas de datos existentes:
- Detección de fraudes en tarjetas de crédito: esta debe ocurrir cuando se produce una
transacción fraudulenta. - Información de telemetría de sensores: en el caso de dispositivos de IoT que envían
información esencial sobre sus entornos, se debe notificar al usuario en cuanto se
detecta una anomalía. - Paneles en vivo: el streaming de eventos es necesario para crear paneles que
muestren información en vivo. - Telemetría del entorno de centro de datos: esto permitirá al usuario conocer
cualquier intrusión, infracción de seguridad, fallo de componentes y mucho más.
Hay muchas posibilidades para aplicar el streaming de eventos dentro de una empresa y su
importancia no se puede destacar lo bastante.
Event Hubs
Azure Event Hubs es una plataforma de streaming que proporciona la funcionalidad
relacionada con la ingesta y el almacenamiento de eventos relacionados con el streaming.
Puede ingerir datos de una variedad de orígenes; estos orígenes podrían ser sensores de IoT
o cualquier aplicación que use el kit de desarrollo de software (SDK) de Event Hubs. Admite
varios protocolos para ingerir y almacenar datos. Estos protocolos son un estándar de la
industria e incluyen lo siguiente:
- HTTP: esta es una opción sin estado y no requiere una sesión activa.
- Advanced Messaging Queuing Protocol (AMQP): esta opción requiere una sesión
activa (es decir, una conexión establecida mediante sockets) y funciona con Seguridad
de la capa de transporte (TLS) y Capa de sockets seguros (SSL). - Apache Kafka: se trata de una plataforma de streaming distribuida similar a Stream
Analytics. Sin embargo, Stream Analytics está diseñado para ejecutar análisis en
tiempo real en múltiples secuencias de datos de diversos orígenes, como sensores
de IoT y sitios web.
Event Hubs es un servicio de ingesta de eventos. No puede consultar una solicitud y generar
resultados de consulta en otra ubicación. Esa es la responsabilidad de Stream Analytics,
que se describe en la siguiente sección.
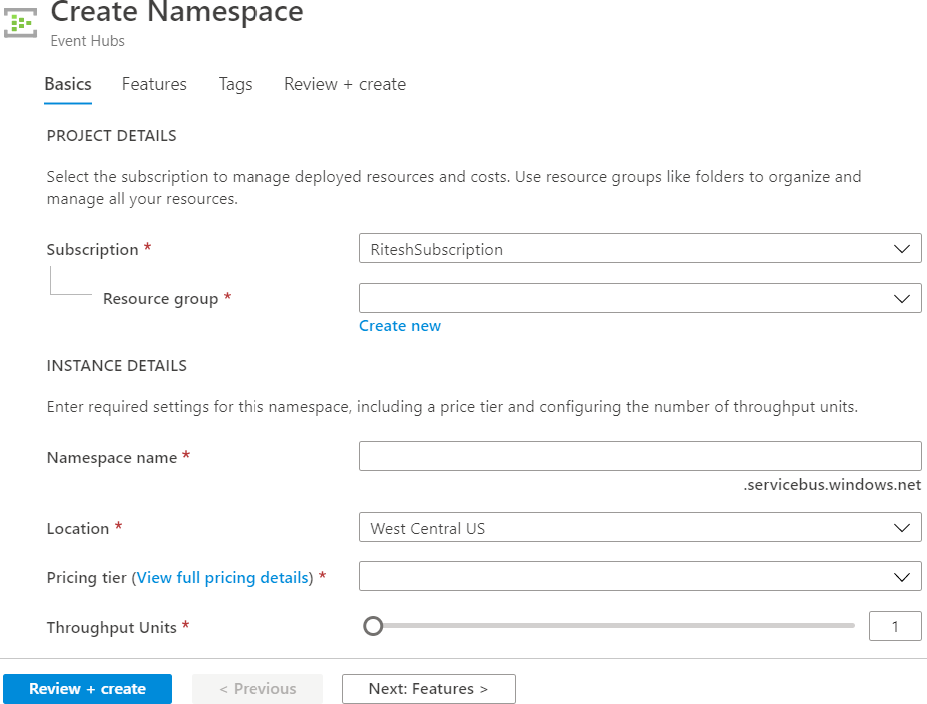
Para crear una instancia de Event Hubs desde el portal, busca Event Hubs en Marketplace
y haz clic en Crear. Selecciona una suscripción y un grupo de recursos existente (o crea
uno nuevo). Proporciona un nombre para el espacio de nombres de Event Hubs, la región
de Azure preferida en la que se hospedará, el nivel de precios (Básico o Estándar, que se
explicará más adelante) y el número de unidades de rendimiento (se explicará más adelante):
Event Hubs, al ser un servicio PaaS, es altamente distribuido, altamente disponible
y escalable.
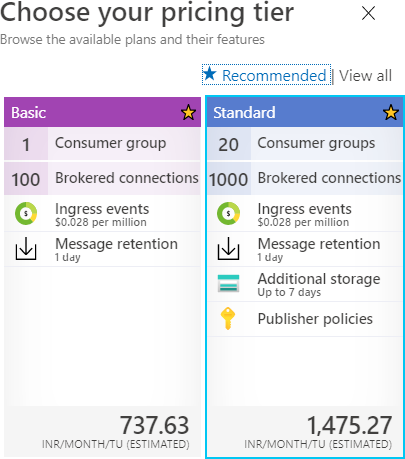
Event Hubs incluye las dos siguientes SKU o niveles de precios:
- Básico: incluye un grupo de consumidores y puede retener mensajes durante 1 día.
Puede tener un máximo de 100 conexiones desacopladas. - Estándar: incluye un máximo de 20 grupos de consumidores y puede retener mensajes
durante 1 día con almacenamiento adicional durante 7 días. Puede tener un máximo de
1000 conexiones desacopladas. También es posible definir políticas en esta SKU.
En la Figura 12.3 se muestran los diferentes SKU disponibles al crear un nuevo espacio
de nombres de Event Hubs. Proporciona una opción para elegir un nivel de precios
adecuado, junto con otros detalles importantes:
El rendimiento también puede configurarse en el nivel de espacio de nombres. Los espacios
de nombres son contenedores que constan de varios centros de eventos en la misma
suscripción y región. El rendimiento se calcula como unidades de rendimiento (TU).
Cada TU proporciona:
- Hasta 1 MB por segundo de entrada o un máximo de 1000 eventos de entrada
y operaciones de administración por segundo. - Hasta 2 MB por segundo de salida o un máximo de 4096 eventos y operaciones
de administración por segundo. - Hasta 84 GB de almacenamiento.
Las TU pueden variar entre 1 y 20 y se facturan por hora.
Es importante destacar que la SKU no se puede cambiar después de aprovisionar un espacio
de nombres de Event Hubs. Se debe tener la debida consideración y planificación antes de
seleccionar una SKU. El proceso de planificación debe incluir la planificación del número de
grupos de consumidores necesarios y el número de aplicaciones interesadas en leer eventos
desde el centro de eventos.
Además, la SKU estándar no está disponible en todas las regiones. Debe comprobarse si está
disponible en el momento del diseño e implementación del centro de eventos. La dirección
URL para comprobar la disponibilidad de la región es https://azure.microsoft.com/globalinfrastructure/
services/?products=event-hubs.
Arquitectura de Event Hubs
Hay tres componentes principales de la arquitectura de Event Hubs: los productores de eventos,
el centro de eventos y el consumidor de eventos, como se muestra en el siguiente diagrama:

Los productores de eventos generan eventos y los envían al centro de eventos. El centro de
eventos almacena los eventos ingeridos y proporciona esos datos al consumidor de eventos.
El consumidor de eventos es cualquier cosa que esté interesada en esos eventos y se
conecta al centro de eventos para capturar los datos.
Los centros de eventos no se pueden crear sin un espacio de nombres de Event Hubs.
El espacio de nombres de Event Hubs actúa como contenedor y puede hospedar varios
centros de eventos. Cada espacio de nombres de Event Hubs proporciona un punto de
conexión único basado en REST que los clientes consumen para enviar datos a Event
Hubs. Este espacio de nombres es el mismo espacio de nombres que se necesita para
los artefactos de Service Bus, como los temas y las colas.
La cadena de conexión de un espacio de nombres de Event Hubs se compone de su
dirección URL, nombre de política y clave. En el siguiente bloque de código se muestra
una cadena de conexión de ejemplo:
Endpoint=sb://demoeventhubnsbook.servicebus.windows.
net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=M/
E4eeBsr7DAlXcvw6ziFqlSDNbFX6E49Jfti8CRkbA=
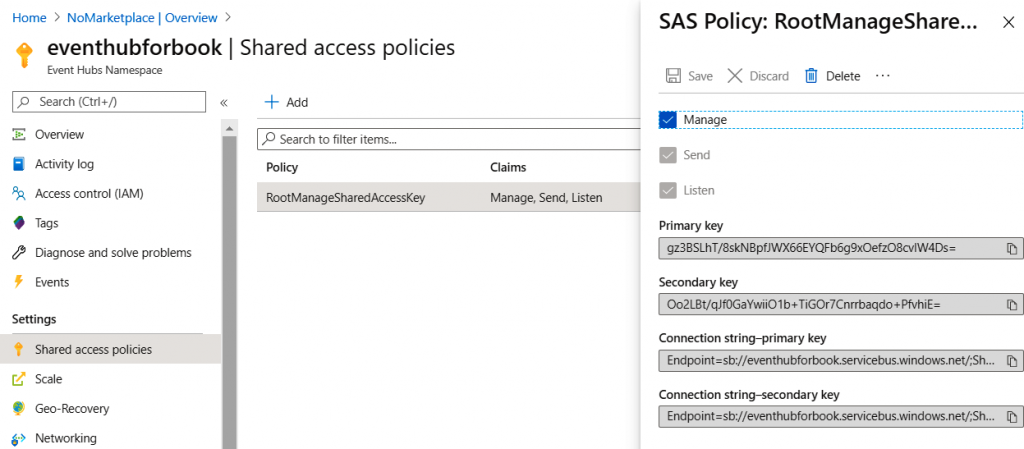
Esta cadena de conexión se puede encontrar en el elemento de menú Firma de acceso
compartido (SAS) del espacio de nombres. Puede haber varias políticas definidas para
un espacio de nombres, cada una con diferentes niveles de acceso al espacio de nombres.
Los tres niveles de acceso son los siguientes:
- Administrar: este nivel puede administrar el centro de eventos desde una perspectiva
administrativa. También tiene derechos para enviar y escuchar eventos. - Enviar: este nivel puede escribir eventos en Event Hubs.
- Escuchar: este nivel puede leer eventos de Event Hubs.
De forma predeterminada, la política RootManageSharedAccessKey se crea al crear un centro
de eventos, como se muestra en la Figura 12.5. Las políticas ayudan a crear un control de
acceso granular en Event Hubs. Los consumidores utilizan la clave asociada a cada política
para determinar su identidad; también se pueden crear políticas adicionales con cualquier
combinación de los tres niveles de acceso mencionados anteriormente:
Los centros de eventos se pueden crear desde el servicio de espacio de nombres de Event
Hubs realizando las siguientes acciones:
- Haz clic en Event Hubs en el menú de la izquierda y, a continuación, en + Centro de
eventos en la pantalla resultante:
- A continuación, proporciona valores para los campos Recuento de particiones
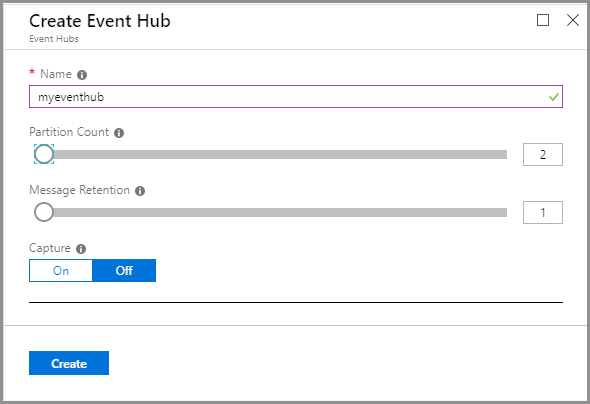
y Retención de mensajes, junto con el nombre que elijas. A continuación,
selecciona Desactivado para Capture, como se muestra en la Figura 12.7:
Figura
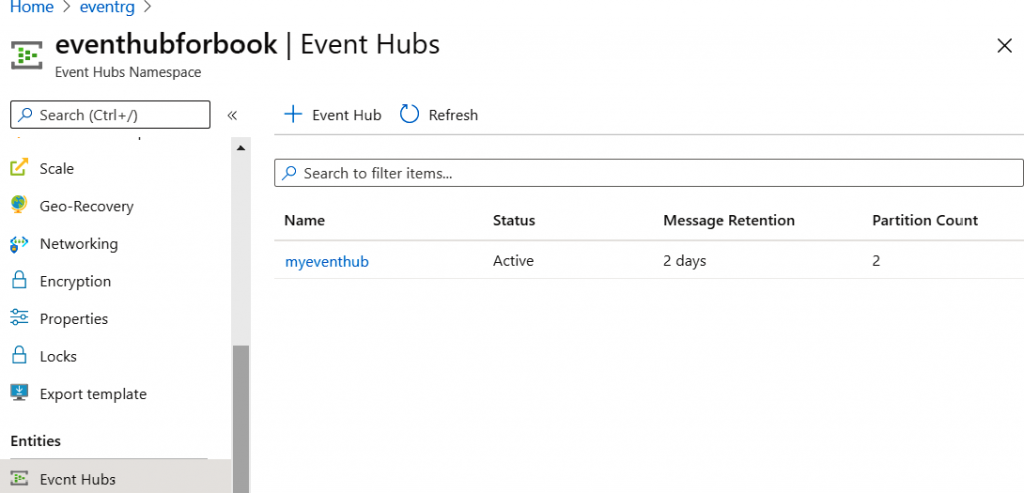
Después de crear el centro de eventos, lo verás en la lista de centros de eventos, como se
muestra en la Figura 12.8:
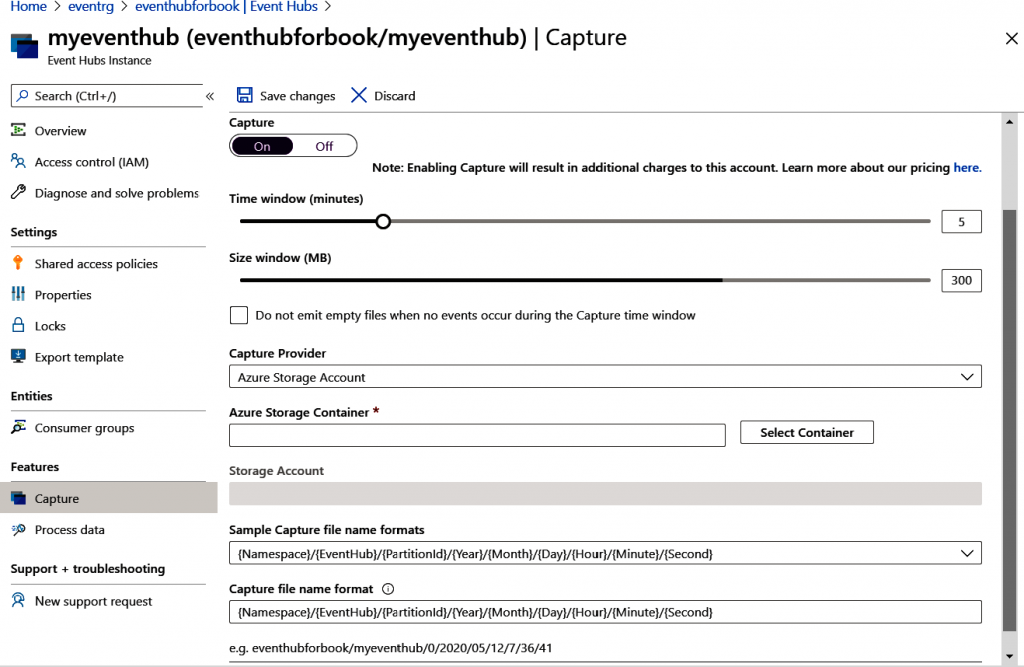
Event Hubs también permite el almacenamiento de eventos en una cuenta de almacenamiento
o data lake directamente mediante una característica conocida como Capture.
Capture ayuda en el almacenamiento automático de los datos ingeridos en una cuenta
de Azure Storage o en un data lake de Azure. Esta característica garantiza que la ingesta
y el almacenamiento de eventos tenga lugar en un solo paso, en lugar de transferir datos
al almacenamiento como una actividad independiente:
Se pueden asignar políticas independientes a cada centro de eventos si se agrega una
política nueva al nivel de centro de eventos.
Después de crear la política, la cadena de conexión está disponible desde el elemento
del menú izquierdo Firma de acceso seguro en Azure Portal.
Puesto que un espacio de nombres puede constar de varios centros de eventos, la cadena
de conexión para un centro de eventos individual será similar al siguiente bloque de código.
La diferencia aquí se encuentra en el valor de clave y la adición de EntityPath con el
nombre del centro de eventos:
Endpoint=sb://azuretwittereventdata.servicebus.windows
=rxEu5K4Y2qsi5wEeOKuOvRnhtgW8xW35UBex4VlIKqg=;EntityPath=myeventhub
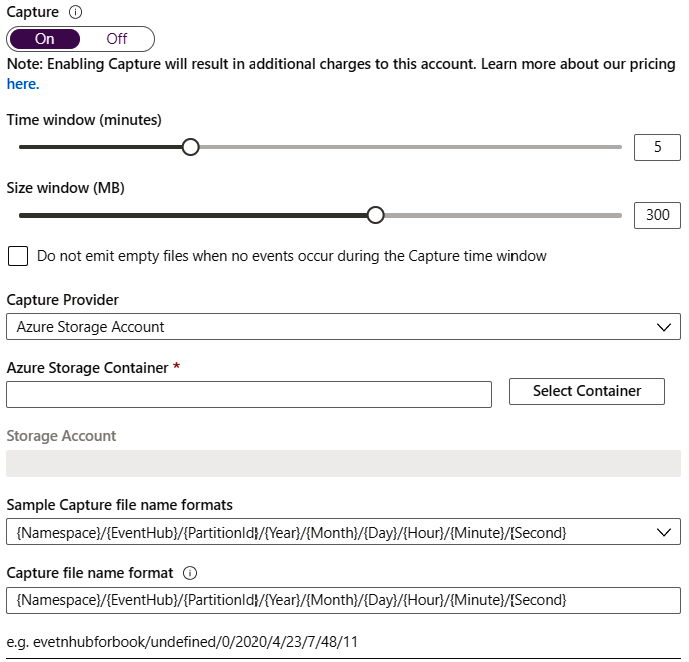
Hemos tenido que mantener la opción Capture establecida en Desactivado al crear
el centro de eventos pero se puede volver a activar después de crear el centro de eventos.
Ayuda a guardar los eventos en Azure Blob Storage o en una cuenta de Azure Data Lake
Storage automáticamente. La configuración del tamaño y del intervalo de tiempo se
muestra en la Figura 12.10:
No hemos tratado los conceptos de particiones y las opciones de retención de mensajes
al crear centros de eventos.
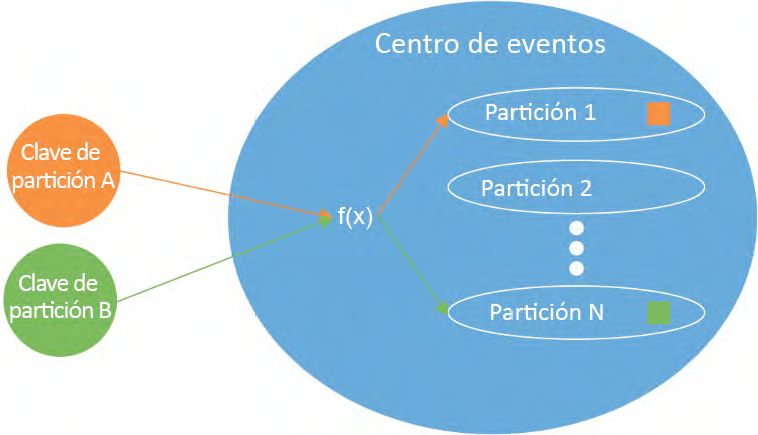
La partición es un concepto importante relacionado con la escalabilidad de cualquier
almacén de datos. Los eventos se conservan dentro de los centros de eventos durante un
período de tiempo específico. Si todos los eventos se almacenan en el mismo almacén de
datos, se vuelve extremadamente difícil escalar ese almacén de datos. Cada productor de
eventos se conectará al mismo almacén de datos y le enviará sus eventos. Compara esto
con un almacén de datos que puede particionar los mismos datos en varios almacenes
de datos más pequeños, cada uno identificado de forma única con un valor.
El almacén de datos más pequeño se denomina partición y el valor que define la partición
se conoce como la clave de partición. Esta clave de partición forma parte de los datos del
evento.
Ahora los productores de eventos pueden conectarse al centro de eventos y, en función
del valor de la clave de partición, el centro de eventos almacenará los datos en una partición
adecuada. Esto permitirá que el centro de eventos ingiera varios eventos al mismo tiempo
en paralelo.
La decisión sobre el número de particiones es un aspecto crucial de la escalabilidad de un
centro de eventos. En la Figura 12.11 se muestra que los datos ingeridos se almacenan en la
partición adecuada de manera interna por Event Hubs mediante la clave de partición:
Es importante entender que una partición podría tener varias claves. El usuario decide
cuántas particiones son necesarias y el centro de eventos decide de manera interna la mejor
manera de asignar las claves de partición entre ellas. Cada partición almacena los datos de
forma ordenada mediante una marca de tiempo y los eventos más recientes se anexan al
final de la partición.
Es importante tener en cuenta que no es posible cambiar el número de particiones una vez
creado el centro de eventos.
Asimismo, es importante recordar que las particiones también ayudan a aportar paralelismo
y simultaneidad para las aplicaciones que leen los eventos. Por ejemplo, si hay 10 particiones,
10 lectores paralelos pueden leer los eventos sin ninguna degradación en el rendimiento.
La retención de mensajes hace referencia al periodo de tiempo para el que deben almacenarse
los eventos. Después de la caducidad del periodo de retención, los eventos se descartan.
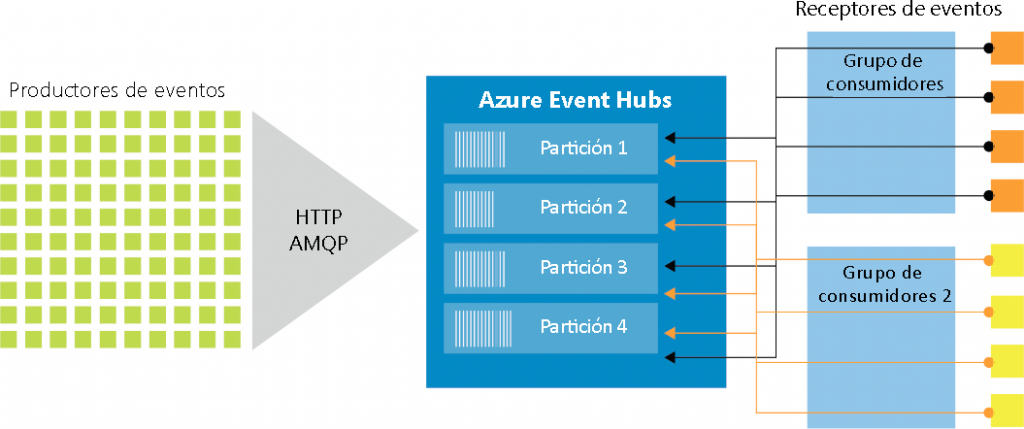
Grupos de consumidores
Los consumidores son aplicaciones que leen eventos desde un centro de eventos. Los
grupos de consumidores se crean para que los consumidores se conecten a ellos con el
fin de leer los eventos. Puede haber varios grupos de consumidores para un centro de
eventos y cada grupo de consumidores tiene acceso a todas las particiones dentro de un
centro de eventos. Cada grupo de consumidores forma una consulta sobre los eventos
en los centros de eventos. Las aplicaciones pueden usar grupos de consumidores y cada
aplicación obtendrá una vista diferente de los eventos del centro de eventos. Al crear un
centro de eventos, se crea un grupo de consumidores $default predeterminado. Es una
buena práctica que un consumidor esté asociado a un grupo de consumidores para
obtener un rendimiento óptimo. Sin embargo, es posible tener cinco lectores en cada
partición de un grupo de consumidores:
Ahora que ya comprendes los grupos de consumidores, es hora de profundizar en el
concepto de rendimiento de Event Hubs.
Rendimiento
Las particiones ayudan con la escalabilidad, mientras que el rendimiento ayuda con la
capacidad por segundo. Por lo tanto, ¿qué es la capacidad en términos de Event Hubs?
Es la cantidad de datos que se pueden gestionar por segundo.
En Event Hubs, una sola TU permite lo siguiente:
- 1 MB de datos de ingesta por segundo o 1000 eventos por segundo (lo que ocurra
primero) - 2 MB de datos de salida por segundo o 4096 eventos por segundo (lo que ocurra
primero)
La opción de inflado automático ayuda a aumentar el rendimiento automáticamente
si el número de eventos entrantes/salientes o el tamaño total entrante/saliente cruza
un umbral. En lugar de limitarse, el rendimiento se escalará hacia arriba y hacia abajo.
La configuración del rendimiento en el momento de la creación del espacio de nombres
se muestra en la Figura 12.13. De nuevo, las TU se deben decidir con cuidado:

Introducción de Stream Analytics
Event Hubs es una plataforma de streaming de datos altamente escalable, por lo que
necesitamos otro servicio que pueda procesar estos eventos como un flujo en lugar de
simplemente como datos almacenados. Stream Analytics ayuda a procesar y examinar un
flujo de Big Data y los trabajos de Stream Analytics ayudan a ejecutar el procesamiento de
eventos.
Stream Analytics puede procesar millones de eventos por segundo y es muy fácil empezar
a usarlo. Azure Stream Analytics es una PaaS que está completamente administrada
por Azure. Los clientes de Stream Analytics no tienen que administrar el hardware y la
plataforma subyacentes.
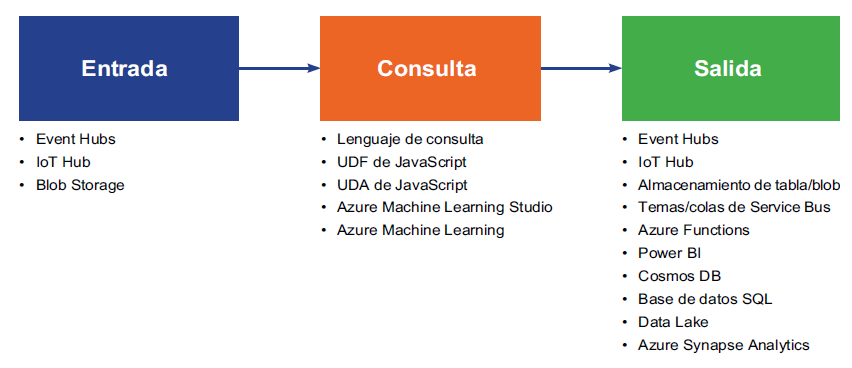
Cada trabajo consta de varias entradas, salidas y una consulta, que transforma los datos
entrantes en una nueva salida. En la Figura 12.14 se muestra la arquitectura completa de
Stream Analytics:
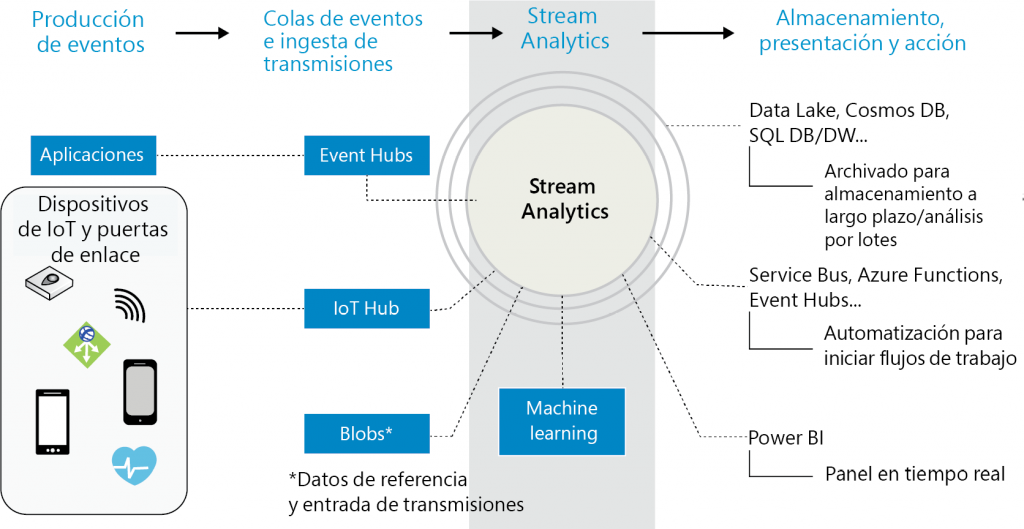
En la Figura 12.14, los orígenes de eventos se muestran en la parte extrema izquierda. Estos
son los orígenes que producen los eventos. Podrían ser dispositivos de IoT, aplicaciones
personalizadas escritas en cualquier lenguaje de programación o eventos procedentes de
otras plataformas de Azure, como Log Analytics o Application Insights.
Estos eventos primero deben ingerirse en el sistema y hay numerosos servicios de Azure
que pueden ayudar a ingerir estos datos. Ya hemos analizado Event Hubs y cómo ayuda
a ingerir datos. Hay otros servicios, como IoT Hub, que también ayudan a ingerir datos
específicos de dispositivo y de sensores. IoT Hub y la ingesta se han abordado en detalle en
el capítulo 11, Diseño de soluciones de IoT. Estos datos ingeridos se someten a procesamiento
a medida que llegan en un flujo y este procesamiento se realiza mediante Stream Analytics.
La salida de Stream Analytics podría introducirse en una plataforma de presentación, como
Power BI, para que muestre datos en tiempo real a las partes interesadas, o una plataforma
de almacenamiento como Cosmos DB, Data Lake Storage o Azure Storage, desde la que las
colas de Azure Functions y Service Bus pueden leer los datos y tomar medidas sobre ellos.
Stream Analytics ayuda a recopilar conocimientos de los datos ingeridos en tiempo real
dentro de un marco de tiempo y ayuda a identificar patrones.
Lo hace a través de tres tareas diferentes:
- Entrada: los datos deben introducirse en el proceso de análisis. Los datos pueden
originarse en Event Hubs, IoT Hub o Azure Blob Storage. Se pueden usar varias
entradas de referencia independientes mediante una cuenta de almacenamiento
y SQL Database para la búsqueda de datos en consultas. - Consulta: aquí es donde Stream Analytics realiza el trabajo principal de analizar los
datos ingeridos y extraer conocimientos y patrones significativos. Lo hace con la ayuda
de las funciones definidas por el usuario de JavaScript, los agregados definidos por el
usuario de JavaScript, Azure Machine Learning y Azure Machine Learning Studio. - Salida: el resultado de las consultas se puede enviar a varios tipos diferentes de
destinos y, entre ellos, destacan Cosmos DB, Power BI, Synapse Analytics, Data
Lake Storage y Functions:
Stream Analytics es capaz de ingerir millones de eventos por segundo y puede ejecutar
consultas por encima de ellos.
Los datos de entrada se admiten en cualquiera de los tres formatos siguientes:
- JavaScript Object Notation (JSON): se trata de un formato ligero basado en texto sin
formato que es legible por humanos. Se compone de pares nombre-valor; un ejemplo
de un evento JSON es el siguiente:
{
«SensorId» : 2,
«humidity» : 60,
«temperature» : 26C
}
- Valores separados por comas (CSV): también son valores de texto sin formato, que están
separados por comas. Se muestra un ejemplo de CSV en la Figura 12.16. La primera fila es
el encabezado, que contiene tres campos, seguido de dos filas de datos:
Figura 12.16: - Avro: este formato es similar a JSON; sin embargo, se almacena en un formato binario
en lugar de un formato de texto:
{
«firstname»: «Ritesh»,
«lastname»: «Modi»,
«email»: «ritesh.modi@outlook.com»
}
No obstante, esto no significa que Stream Analytics solo pueda ingerir datos utilizando estos
tres formatos. También puede crear deserializadores personalizados basados en .NET, con
los que se puede ingerir cualquier formato de datos, en función de la implementación de los
deserializadores. Los pasos que puedes seguir para escribir un deserializador personalizado
están disponibles en https://docs.microsoft.com/azure/stream-analytics/customdeserializer-
examples.
Stream Analytics no solo puede recibir eventos, sino que también proporciona capacidad
de consulta avanzada para los datos que recibe. Las consultas pueden extraer conocimiento
importante de los flujos de datos temporales y mostrarlos.
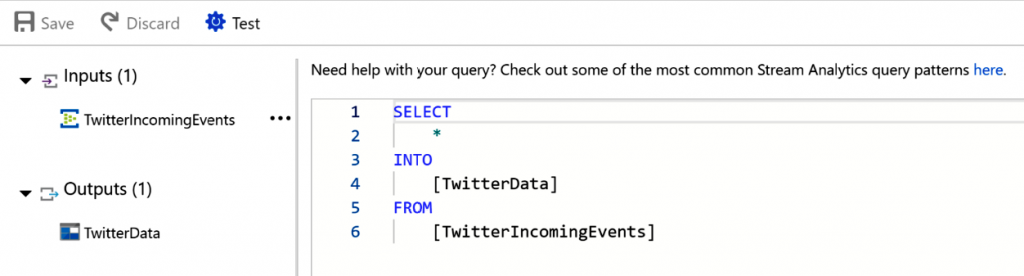
Como se muestra en la Figura 12.17, hay un conjunto de datos de entrada y de salida;
la consulta mueve los eventos de la entrada a la salida. La cláusula INTO hace referencia
a la ubicación de salida y la cláusula FROM hace referencia a la ubicación de entrada.
Las consultas son muy parecidas a las consultas SQL, por lo que la curva de aprendizaje
no es demasiado pronunciada para los programadores de SQL:
Event Hubs proporciona mecanismos para enviar salidas desde las consultas hasta los
destinos. En el momento de redactar este documento, Stream Analytics admite varios
destinos para eventos y salidas de consulta, como se ha mostrado anteriormente.
También es posible definir funciones personalizadas que se pueden reutilizar en las
consultas. Hay cuatro opciones proporcionadas para definir funciones personalizadas.
- Azure Machine Learning
- Funciones definidas por el usuario de JavaScript
- Agregados definidos por el usuario de JavaScript
- Azure Machine Learning Studio
El entorno de hosting
Los trabajos de Stream Analytics se pueden ejecutar en hosts que se ejecutan en el cloud
o pueden ejecutarse en dispositivos de IoT Edge. Los dispositivos IoT Edge son dispositivos
que están cerca de los sensores de IoT, en lugar de en el cloud. En la Figura 12.18 se muestra
el panel Nuevo trabajo de Stream Analytics:
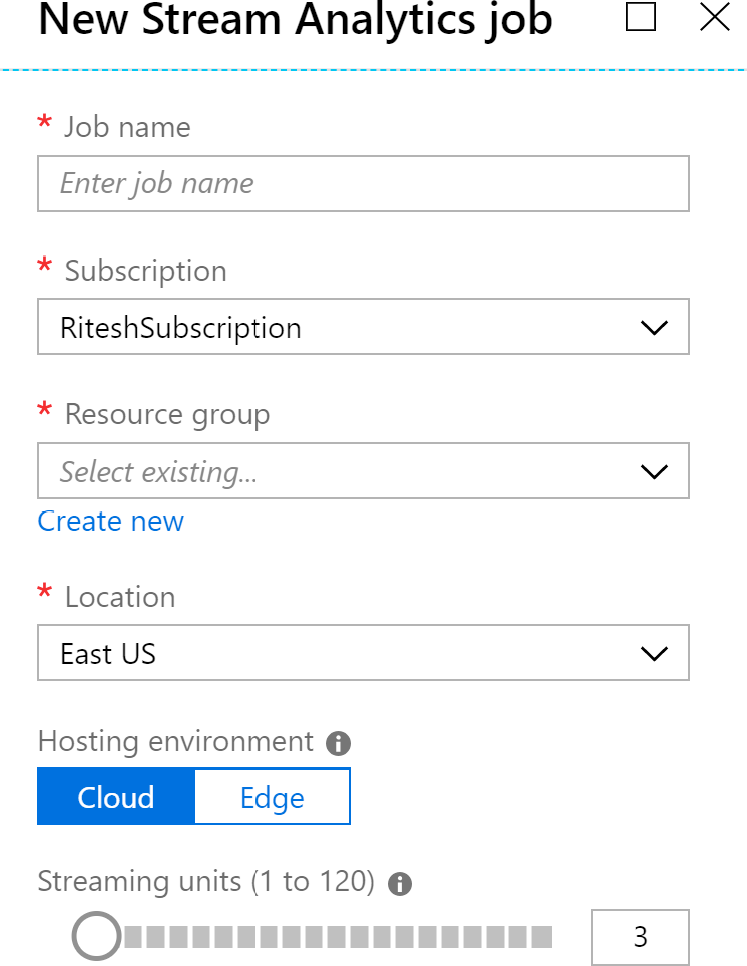
Echemos un vistazo en detalle a las unidades de streaming.
Unidades de streaming
En la Figura 12.18, puedes ver que la única configuración que es exclusiva de Stream
Analytics es unidades de streaming. Las unidades de streaming hacen referencia a los
recursos (es decir, CPU y memoria) que se asignan para ejecutar un trabajo de Stream
Analytics. Las unidades de streaming mínimas y máximas son 1 y 120, respectivamente.
Las unidades de streaming deben estar preasignadas conforme a la cantidad de datos y el
número de consultas ejecutadas en esos datos; en caso contrario, se producirá un error en
el trabajo.
Es posible escalar las unidades de streaming hacia arriba y hacia abajo desde Azure Portal.
Una aplicación de ejemplo que usa Event Hubs y Stream Analytics
En esta sección, vamos a crear una aplicación de ejemplo que comprende varios servicios de
Azure, como Azure Logic Apps, Azure Event Hubs, Azure Storage y Azure Stream Analytics.
En esta aplicación de ejemplo, vamos a leer todos los tweets que contienen la palabra
«Azure» y almacenarlos en una cuenta de Azure Storage.
Para crear esta solución, primero necesitamos aprovisionar todos los recursos necesarios.
Aprovisionar un nuevo grupo de recursos
Dirígete a Azure Portal, inicia sesión con unas credenciales válidas, haz clic en + Crear
un recurso y busca Grupo de recursos. Selecciona Grupo de recursos en los resultados
de búsqueda y crea un nuevo grupo de recursos. A continuación, proporciona un nombre
y elige una ubicación adecuada. Ten en cuenta que todos los recursos se deben hospedar
en el mismo grupo de recursos y ubicación para que resulte fácil eliminarlos:
A continuación, crearemos un espacio de nombres de Event Hubs.
Crear un espacio de nombres de Event Hubs
Haz clic en + Crear un recurso y busca Event Hubs. Selecciona Event Hubs en los
resultados de la búsqueda y crea un nuevo centro de eventos. A continuación, proporciona
un nombre y una ubicación y selecciona una suscripción basada en el grupo de recursos
que hemos creado anteriormente. Selecciona Estándar como el nivel de precios y también
Habilitar el inflado automático, como se muestra en la Figura 12.20:
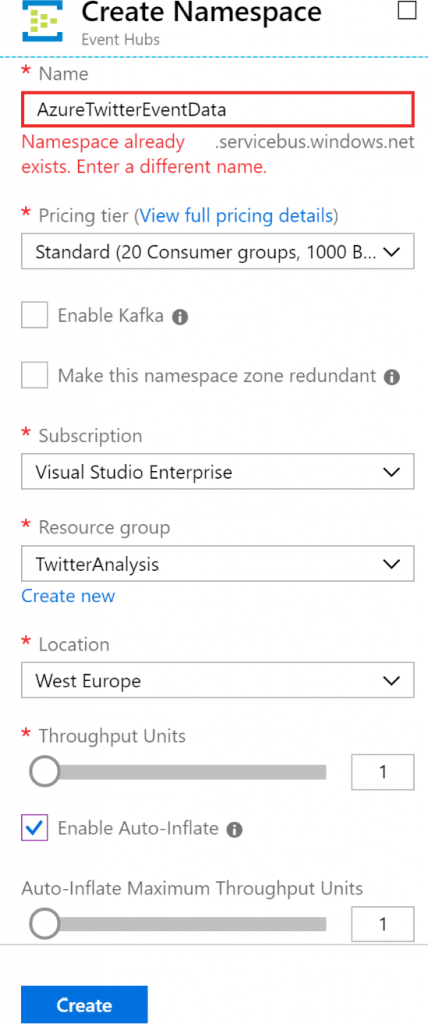
A estas alturas, debería haberse creado un espacio de nombres de Event Hubs. Es un
requisito previo tener un espacio de nombres antes de poder crear un centro de eventos.
El siguiente paso es aprovisionar un centro de eventos.
Crear un centro de eventos
En el servicio de espacio de nombres de Event Hubs, haz clic en Events Hubs en el menú de
la izquierda y, a continuación, haz clic en + Centros de eventos para crear un nuevo centro
de eventos. Denomínalo azuretwitterdata y proporciona un número óptimo de particiones
y un valor de Retención de mensajes:
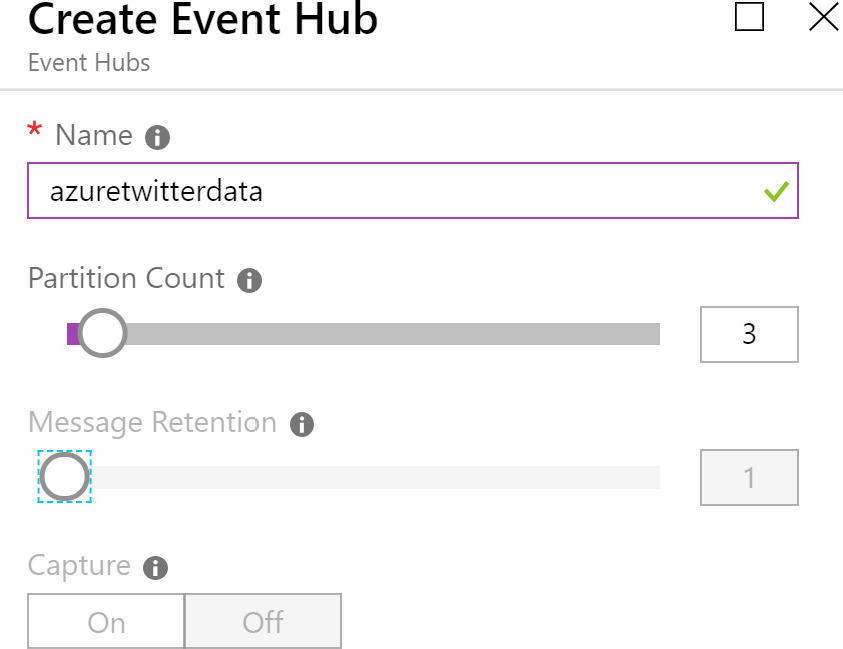
Después de este paso, tendrás un centro de eventos que se puede utilizar para enviar datos
de eventos, que se almacenan en un almacenamiento duradero como un data lake o una
cuenta de Azure Storage, para que los utilicen los servicios posteriores.
Aprovisionar una aplicación lógica
Después de aprovisionar el grupo de recursos, haz clic en + Crear un recurso y busca
Logic Apps. Selecciona Logic Apps en los resultados de la búsqueda y crea una nueva
aplicación lógica. A continuación, proporciona un nombre y una ubicación y selecciona
una suscripción basada en el grupo de recursos creado anteriormente. Es una buena
práctica habilitar Log Analytics. Logic Apps se aborda con más detalle en el capítulo 11,
Soluciones de Azure que utilizan Azure Logic Apps, Event Grid y Functions. La aplicación
lógica es responsable de conectarse a Twitter mediante una cuenta y de recuperar todos
los tweets con Azure en ellos:
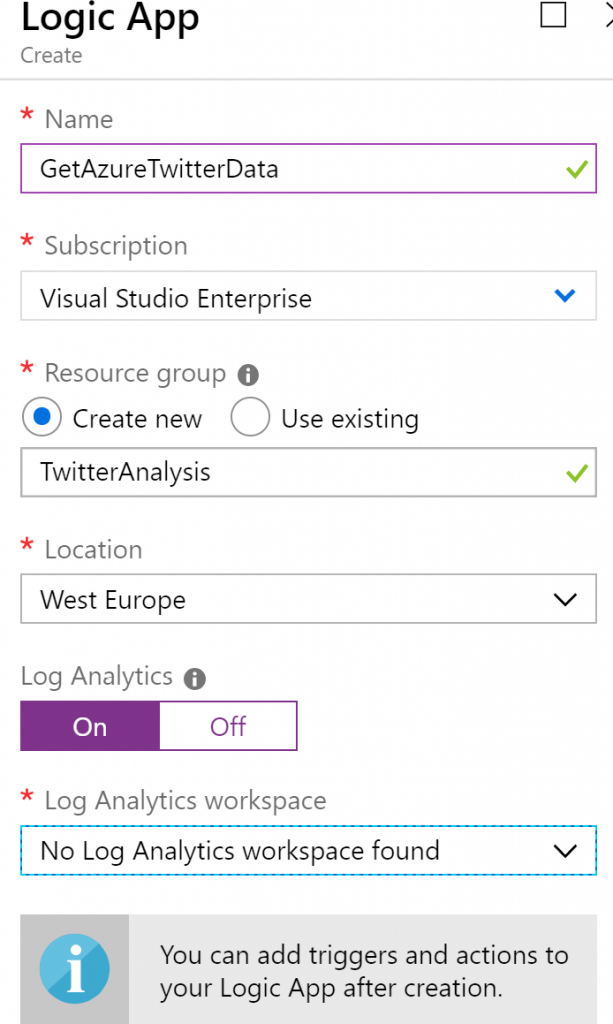
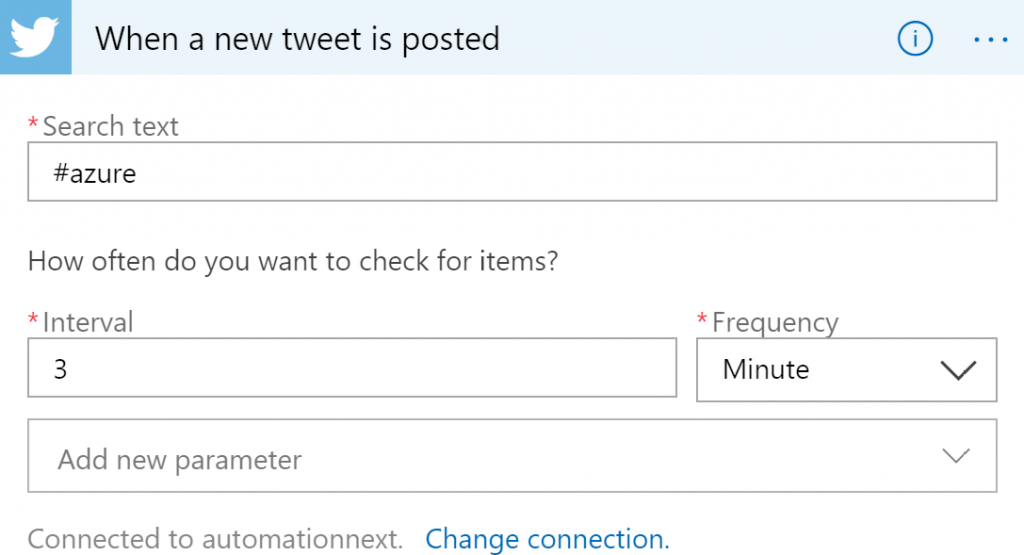
Una vez se ha creado la aplicación lógica, selecciona el desencadenador Cuando se publica
un tweet nuevo en la superficie de diseño, inicia sesión y, a continuación, configúralo como
se muestra en la Figura 12.23. Necesitarás una cuenta de Twitter válida antes de configurar
este desencadenador:
A continuación, coloca la acción Enviar evento en la superficie del diseñador; esta acción es
responsable de enviar tweets al centro de eventos:
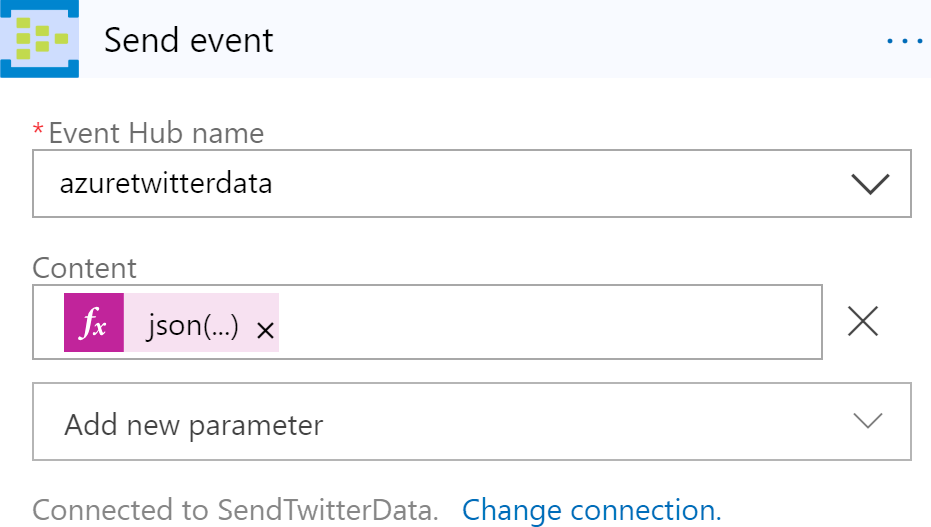
Selecciona el nombre del centro de eventos que se creó en un paso anterior.
El valor especificado en el cuadro de texto de contenido es una expresión que se ha
compuesto dinámicamente mediante las funciones facilitadas por Logic Apps y los datos
de Twitter. Al hacer clic en Agregar contenido dinámico se proporciona un cuadro de
diálogo mediante el cual se puede componer la expresión:
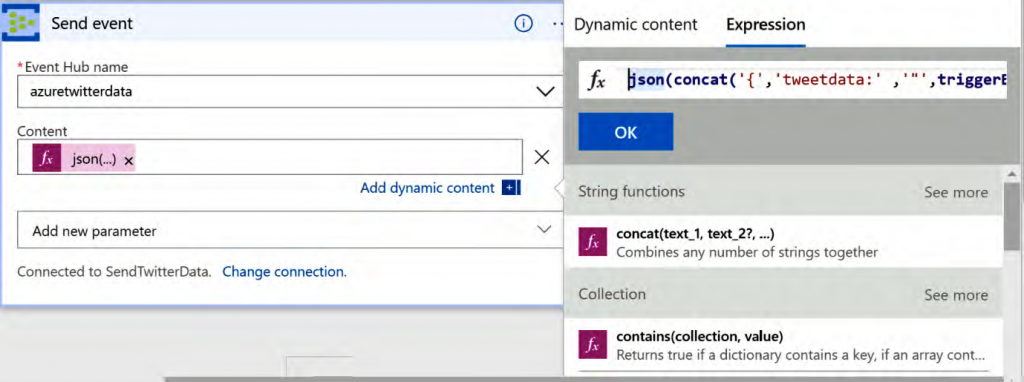
El valor de la expresión es el siguiente:
json(concat(‘{‘,’tweetdata:’ ,'»‘,triggerBody()?[‘TweetText’],'»‘, ‘}’))
En la siguiente sección, aprovisionaremos la cuenta de almacenamiento.
Aprovisionar la cuenta de almacenamiento
Haz clic en + Crear un recurso y busca Cuenta de almacenamiento. Selecciona Cuenta
de almacenamiento en los resultados de la búsqueda y crea una nueva cuenta de
almacenamiento. A continuación, proporciona un nombre y una ubicación y selecciona una
suscripción basada en el grupo de recursos que hemos creado anteriormente. Por último,
selecciona StorageV2 para Tipo de cuenta, Estándar para Rendimiento y Almacenamiento
con redundancia local (LRS) para el campo Replicación.
A continuación, crearemos un contenedor de Azure Blob Storage para almacenar los datos
procedentes de Stream Analytics.
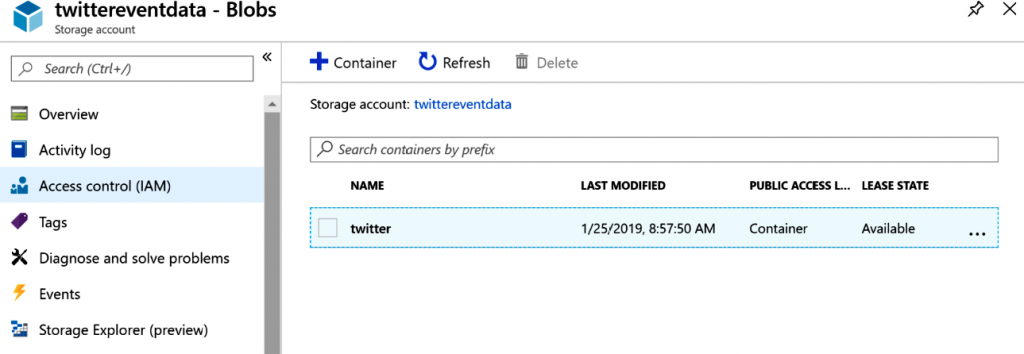
Crear un contenedor de almacenamiento
Stream Analytics mostrará los datos como archivos, que se almacenarán en un contenedor
de Azure Blob Storage. Se crea un contenedor denominado twitter en Azure Blob Storage,
como se muestra en la Figura 12.26:
Vamos a crear un nuevo trabajo de Stream Analytics con un entorno de hosting en el cloud
y estableceremos las unidades de streaming en la configuración predeterminada.
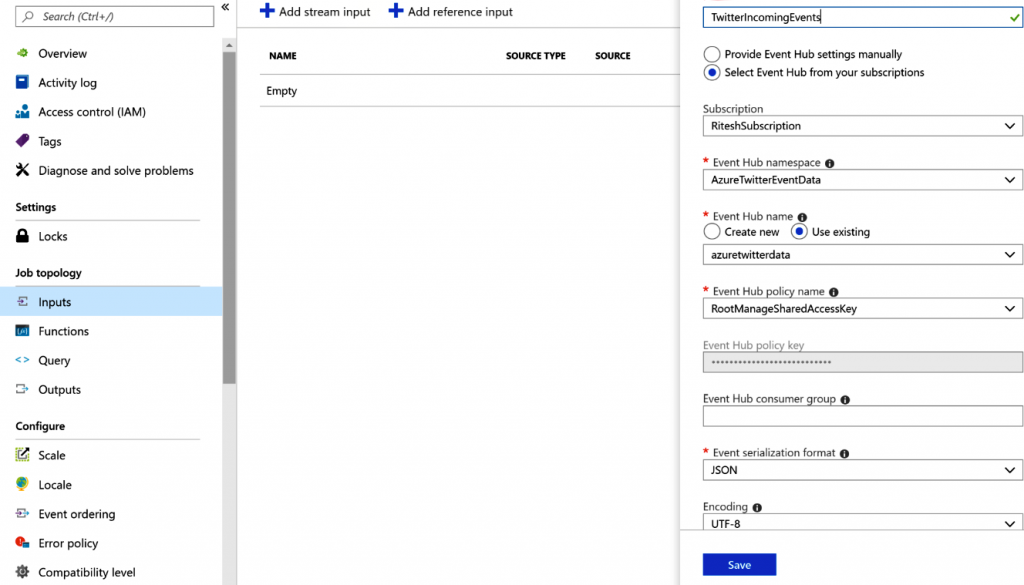
Crear trabajos de Stream Analytics
La entrada de este trabajo de Stream Analytics procede del centro de eventos, por lo que
necesitamos configurarla desde el menú Entradas:
La salida del trabajo de Stream Analytics es una cuenta de Azure Blob Storage, por lo que
tienes que configurar la salida en consecuencia. Proporciona un patrón de ruta de acceso
que sea adecuado para este ejercicio; por ejemplo, {datetime:ss} es el patrón de ruta de
acceso que estamos usando para este ejercicio:
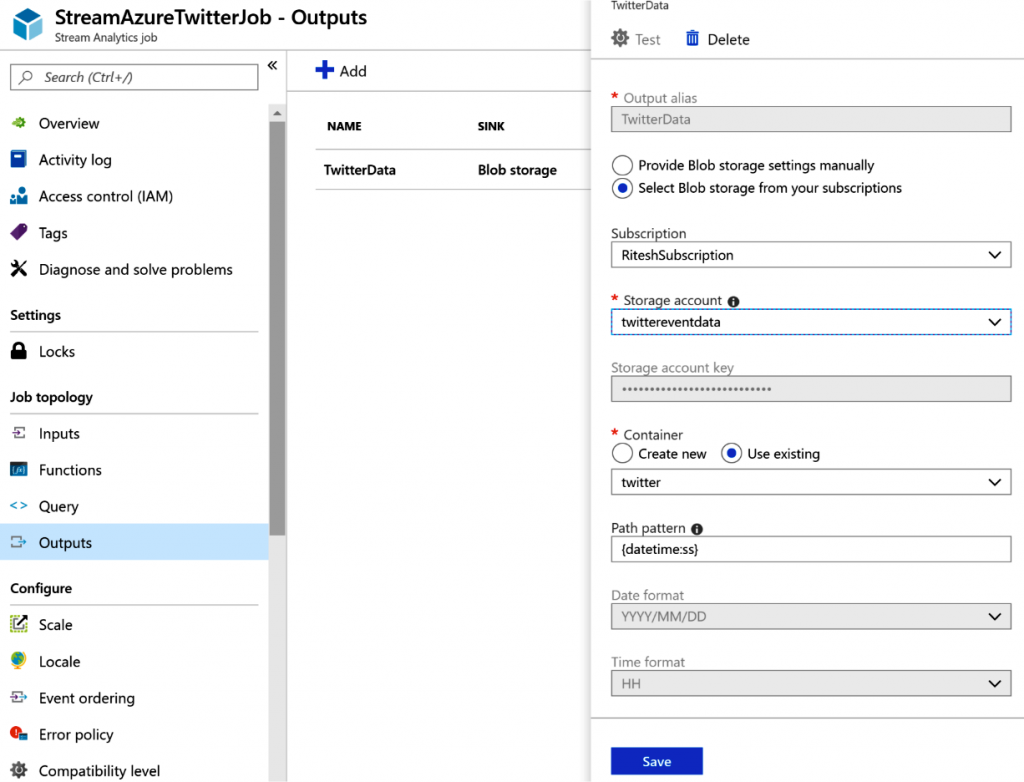
La consulta es bastante sencilla; solo copias los datos de la entrada en la salida:
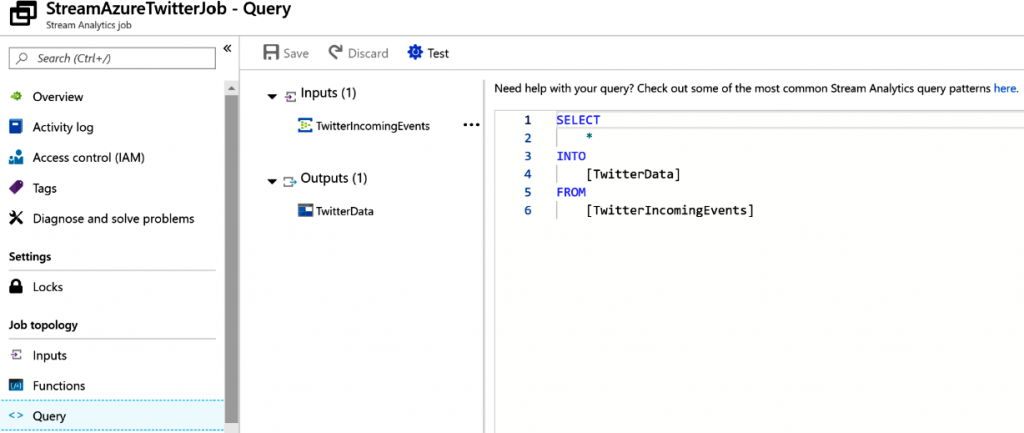
Aunque este ejemplo solo implica copiar datos, puede haber consultas más complejas para
realizar la transformación antes de cargar los datos en un destino.
Con esto se concluyen todos los pasos de la aplicación; ahora deberías poder ejecutarla.
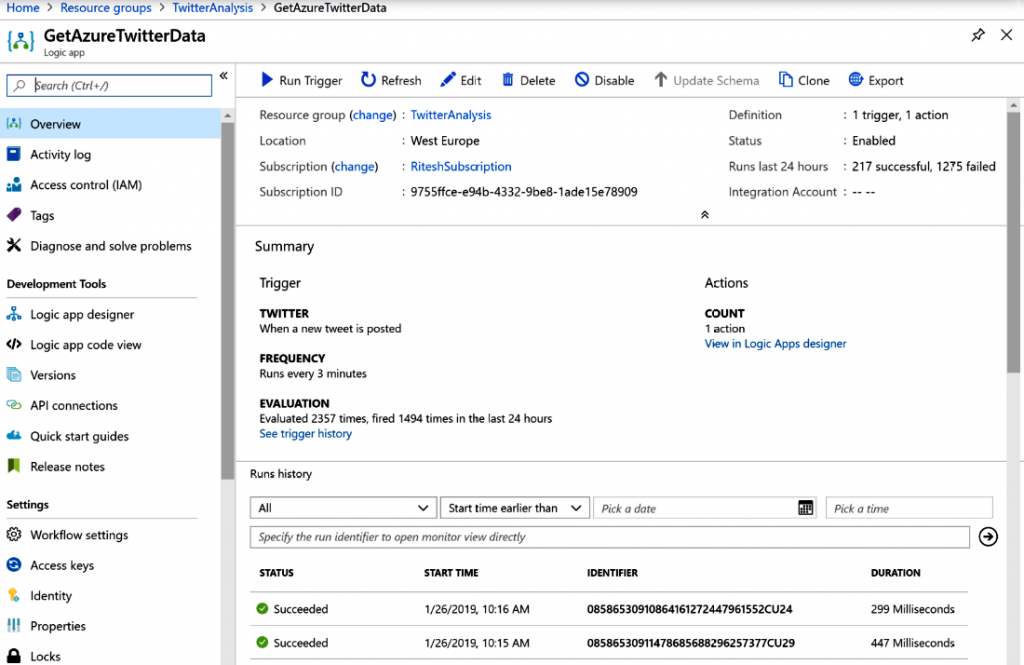
Ejecutar la aplicación
La aplicación lógica se debe habilitar y Stream Analytics debe estar en ejecución. Ahora,
ejecuta la aplicación lógica; creará un trabajo para ejecutar todas las actividades dentro
de él, como se muestra en la Figura 12.30:
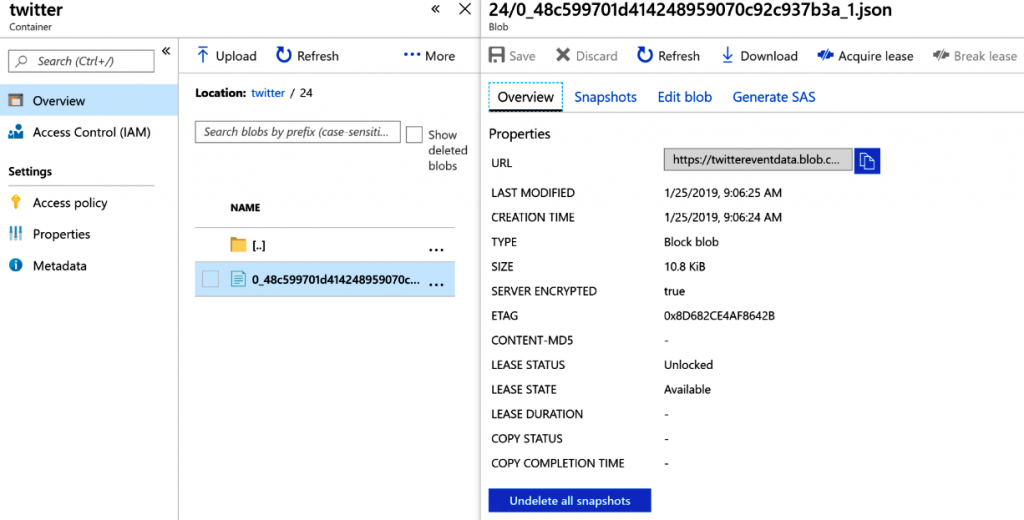
El contenedor Cuenta de almacenamiento debe obtener los datos, como se muestra en la
Figura 12.31:
Como ejercicio, puedes ampliar esta solución de ejemplo y evaluar la opinión de los tweets
cada tres minutos. El flujo de trabajo de Logic Apps para un ejercicio de este tipo sería
el siguiente:
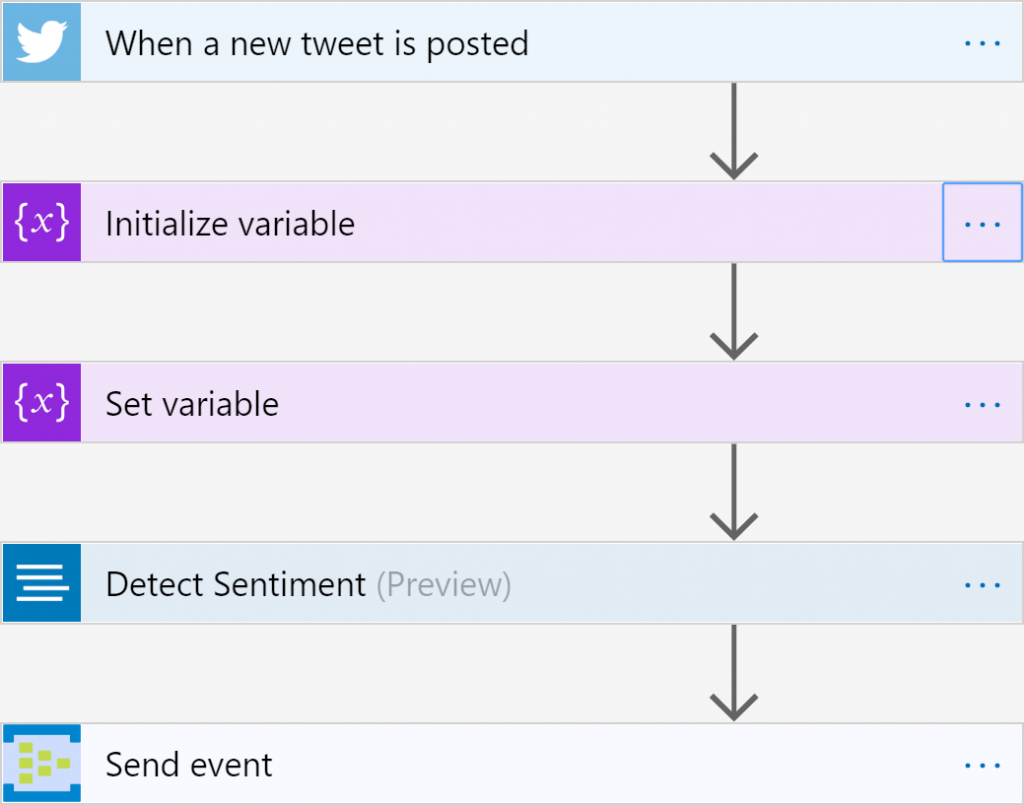
Para detectar las opiniones, deberás usar la API de Text Analytics, que debe configurarse
antes de poder usarse en Logic Apps.
Resumen
Este capítulo se ha centrado en temas relacionados con el streaming y el almacenamiento
de eventos. Los eventos se han convertido en un factor importante en la arquitectura
general de la solución. Hemos abordado recursos importantes, como Event Hubs y
Stream Analytics, y conceptos fundamentales, como los grupos de consumidores y los
rendimientos, además de crear una solución integral que los utilice junto con Logic Apps.
Has aprendido que los eventos se generan en varios orígenes y, con el fin de obtener
conocimiento en tiempo real sobre las actividades y sus eventos relacionados, los servicios
como Event Hubs y Stream Analytics desempeñan un papel importante. En el siguiente
capítulo, aprenderemos a integrar Azure DevOps y Jenkins e implementar algunas de las
prácticas recomendadas del sector al desarrollar soluciones.