



Azure ofrece tanto Infraestructura como servicio (IaaS) como Plataforma como servicio (PaaS). Estos tipos de servicios proporcionan a las organizaciones diferentes niveles y controles sobre el almacenamiento, la computación y las redes. El almacenamiento es el recurso que se utiliza cuando se trabaja con el almacenamiento y la transmisión de datos. Azure proporciona muchas opciones para almacenar datos, como Azure Blob Storage, Azure Table Storage, Cosmos DB, Azure SQL Database, Azure Data Lake Storage, etc. Aunque algunas de estas opciones están destinadas al almacenamiento, análisis y presentación de Big Data, otras están destinadas a aplicaciones que procesan transacciones. Azure SQL es el recurso principal en Azure que funciona con datos transaccionales.
Este capítulo se centra en varios aspectos del uso de almacenes de datos transaccionales,
como Azure SQL Database y otras bases de datos de código abierto, que normalmente
se usan en los sistemas de procesamiento de transacciones en línea (OLTP) y abarca
los siguientes temas:
- Aplicaciones OLTP
- Bases de datos relacionales
- Modelos de implementación
- Azure SQL Database
- Instancia única
- Grupos elásticos
- Instancia administrada
- Cosmos DB
Para comenzar este capítulo analizaremos qué son las aplicaciones OLTP y enumeraremos
los servicios OLTP de Azure y sus casos prácticos.
Aplicaciones OLTP
Como se ha mencionado anteriormente, las aplicaciones OLTP ayudan en el procesamiento
y la administración de transacciones. Algunas de las implementaciones de OLTP más
frecuentes pueden encontrarse en ventas minoristas, sistemas de transacciones financieras
e introducción de pedidos. Estas aplicaciones se encargan de capturar, procesar, recuperar,
modificar y almacenar datos. Sin embargo, no es solo eso. Las aplicaciones OLTP tratan
estas tareas de datos como transacciones. Las transacciones tienen algunas propiedades
importantes y las aplicaciones OLTP tienen en cuenta estas propiedades. Estas propiedades
se agrupan bajo el acrónimo ACID. Hablemos de estas propiedades en detalle:
- Atomicidad: esta propiedad indica que una transacción debe constar de instrucciones
y que todas las instrucciones se completarán correctamente o ninguna se ejecutará. Si
se agrupan varias instrucciones, estas forman una transacción. La atomicidad significa
que cada transacción se trata como la menor unidad de ejecución única que se
completa correctamente o no. - Coherencia: esta propiedad se centra en el estado de los datos de una base de datos.
Dicta que cualquier cambio de estado debe completarse y basarse en las reglas y
restricciones de la base de datos, y que no se deben permitir las actualizaciones parciales. - Aislamiento: esta propiedad indica que puede haber varias transacciones ejecutándose
simultáneamente en un sistema y que cada transacción debe tratarse de manera
aislada. Una transacción no debe tener información de ninguna otra ni interferir
con ellas. Si las transacciones debían ejecutarse de manera secuencial, al final,
el estado de los datos debería ser el mismo que antes. - Durabilidad: esta propiedad indica que los datos deben conservarse y estar
disponibles, incluso después de un error, una vez que se confirman en la base
de datos. Una transacción confirmada se convierte en un hecho.
Ahora que ya sabes lo que son las aplicaciones OLTP, vamos a hablar de la función
de las bases de datos relacionales en las aplicaciones OLTP.
Bases de datos relacionales
Las aplicaciones OLTP generalmente se basan en bases de datos relacionales para la
administración y el procesamiento de transacciones. Las bases de datos relacionales
normalmente vienen en un formato de tabla compuesto de filas y columnas. El modelo de
datos se convierte en varias tablas donde cada tabla está conectada a otra tabla (basándose
en reglas) mediante relaciones. Este proceso también se conoce como normalización.
Hay varios servicios en Azure que admiten aplicaciones OLTP y la implementación
de bases de datos relacionales. En la siguiente sección, examinaremos los servicios
de Azure relacionados con las aplicaciones OLTP.
Servicios cloud de Azure
Si se busca sql en Azure Portal, se obtienen varios resultados. He marcado algunos de ellos
para mostrar los recursos que se pueden usar directamente para las aplicaciones OLTP:
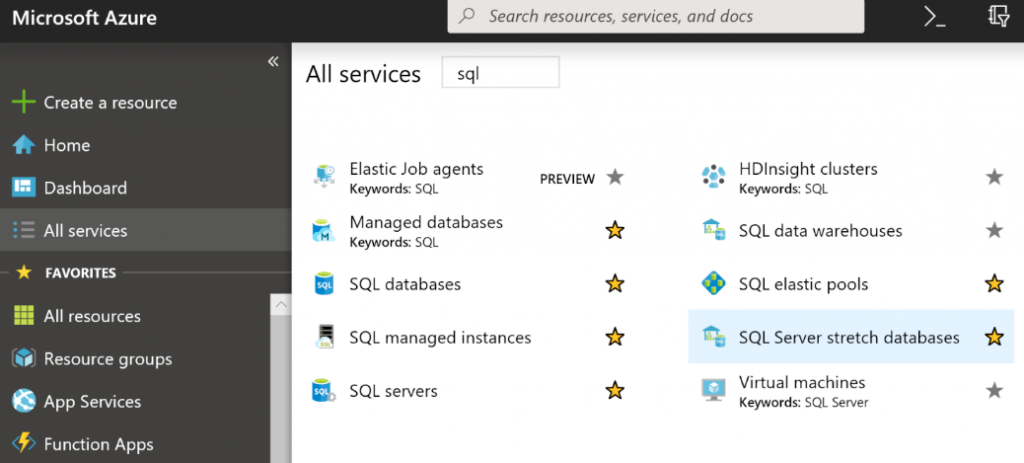
En la Figura 7.1 se muestran las diversas características y opciones disponibles para crear
bases de datos basadas en SQL Server en Azure.
De nuevo, una búsqueda rápida de base de datos en Azure Portal proporciona varios
recursos y los marcados en la Figura 7.2 se pueden usar para aplicaciones OLTP:
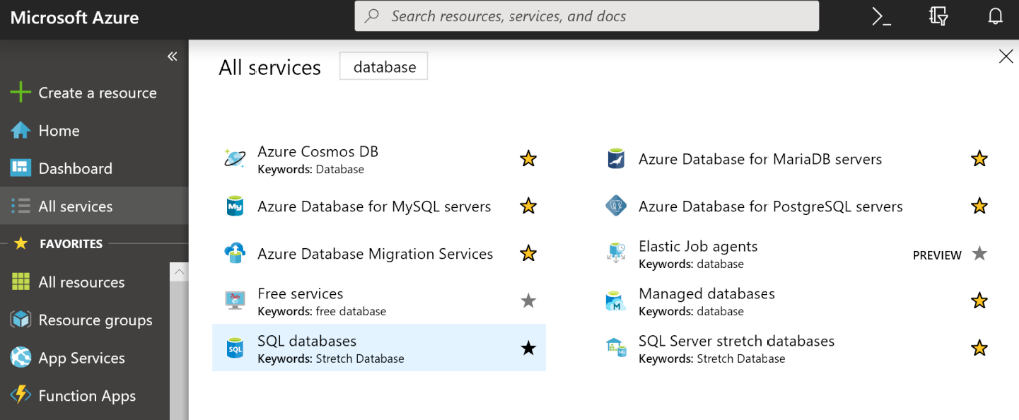
En la Figura 7.2 se muestran los recursos proporcionados por Azure que pueden hospedar
datos en diversas bases de datos, incluidas las siguientes:
- Bases de datos MySQL
- Bases de datos MariaDB
- Bases de datos PostgreSQL
- Cosmos DB
A continuación, vamos a hablar de los modelos de implementación.
Modelos de implementación
Los modelos de implementación en Azure se clasifican en función del nivel de administración
o control. Es el usuario el que selecciona qué nivel de administración o control prefiere; puede
obtener un control total mediante el uso de servicios como las máquinas virtuales, o bien
puede usar servicios administrados donde Azure se encargará de administrarlo todo.
Hay dos modelos de implementación para implementar bases de datos en Azure:
- Bases de datos en Azure Virtual Machines (IaaS)
- Bases de datos hospedadas como servicios administrados (PaaS)
Ahora intentaremos entender la diferencia entre la implementación en Azure Virtual
Machines y las instancias administradas. Empecemos con las máquinas virtuales.
Bases de datos en Azure Virtual Machines
Azure proporciona varias referencias de almacén (SKU) para máquinas virtuales. También
hay disponibles máquinas de alta capacidad de computación y alto rendimiento (IOPS),
junto con máquinas virtuales de uso general. En lugar de hospedar una base de datos SQL
Server, MySQL o de cualquier otro tipo en servidores on-premises, es posible implementar
estas bases de datos en estas máquinas virtuales. La implementación y configuración de
estas bases de datos no son diferentes de la de las implementaciones on-premises. La
única diferencia es que la base de datos se hospeda en el cloud en lugar de usar servidores
on-premises. Los administradores deben realizar los mismos pasos y actividades que
normalmente seguirían para una implementación on-premises. Aunque esta opción
es excelente cuando los clientes desean un control total sobre su implementación,
hay modelos que pueden ser más rentables, escalables y con una alta disponibilidad
en comparación con esta opción, de la que hablaremos más adelante en este capítulo.
Los pasos para implementar cualquier base de datos en Azure Virtual Machines son
los siguientes:
- Crear una máquina virtual con un tamaño adecuado a los requisitos de rendimiento
de la aplicación - Implementar la base de datos sobre ella
- Configurar la máquina virtual y los ajustes de la base de datos
Esta opción no proporciona ninguna alta disponibilidad «out of the box» a menos que
se aprovisionen varios servidores. Tampoco proporciona ninguna característica para
el escalado automático a menos que la automatización personalizada lo admita.
La recuperación ante desastres también es responsabilidad del cliente. Los servidores deben
implementarse en varias regiones conectadas mediante servicios como emparejamiento
global, puertas de enlace de VPN, ExpressRoute o WAN virtual. Es posible que estas máquinas
virtuales se conecten a un centro de datos on-premises a través de VPN de sitio a sitio o
ExpressRoute sin tener ninguna exposición al mundo exterior.
Estas bases de datos también se conocen como bases de datos no administradas. Por
otro lado, las bases de datos hospedadas con Azure, que no sean máquinas virtuales,
las administra Azure y se conocen como servicios administrados. Abordaremos en
detalle todo esto en la siguiente sección.
Bases de datos hospedadas como servicios administrados
«Servicios administrados» quiere decir que Azure proporciona servicios de administración
para las bases de datos. Estos servicios incluyen el hosting de la base de datos, asegurar
que el host tenga una alta disponibilidad, garantizar que los datos se repliquen internamente
para la disponibilidad durante la recuperación ante desastres, asegurar la escalabilidad
dentro de la restricción de una SKU determinada, supervisar los hosts y las bases de datos
y generar alertas para notificaciones o acciones en ejecución, proporcionar servicios
de registro y auditoría para solucionar problemas, y ocuparse de las alertas de seguridad
y administración del rendimiento.
En resumen, hay muchos servicios que los clientes obtienen «out of the box» al usar
servicios administrados de Azure, por lo que no necesitan realizar una administración activa
de estas bases de datos. En este capítulo, vamos a ver Azure SQL Database en profundidad
y proporcionaremos información sobre otras bases de datos, como MySQL y Postgres.
Además, hablaremos de bases de datos no relacionales como Cosmos DB, que es una base
de datos NoSQL.
Azure SQL Database
Azure SQL Server proporciona una base de datos relacional hospedada como un PaaS.
Los clientes pueden aprovisionar este servicio, traer su propio esquema y datos de base de
datos y conectar sus aplicaciones a él. Proporciona todas las características de SQL Server
que se obtienen al implementarse en una máquina virtual. Estos servicios no proporcionan
una interfaz de usuario para crear tablas y su esquema, ni tampoco ninguna capacidad de
consulta directamente. Se debe usar SQL Server Management Studio y las herramientas
de la CLI de SQL para conectar a estos servicios y trabajar directamente con ellos.
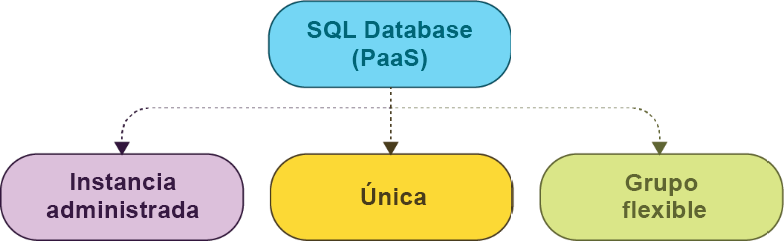
Azure SQL Database incluye tres modelos de implementación distintos:
- Instancia única: en este modelo de implementación, se implementa una única base
de datos en un servidor lógico. Esto implica la creación de dos recursos en Azure:
un servidor lógico SQL y una base de datos SQL. - Grupo elástico: en este modo, se implementan varias bases de datos en un servidor
lógico. De nuevo, implica la creación de dos recursos en Azure: un servidor lógico
SQL y un grupo elástico de bases de datos SQL, que contiene todas las bases de datos. - Instancia administrada: se trata de un modelo de implementación relativamente
nuevo del equipo de Azure SQL. Esta implementación refleja una colección de
bases de datos en un servidor lógico, que proporciona un control completo sobre
los recursos en términos de bases de datos del sistema. Por lo general, las bases de
datos del sistema no son visibles en otros modelos de implementación, pero están
disponibles en el modelo. Este modelo se acerca mucho a la implementación de
SQL Server on-premises:
Si no estás seguro de cuándo usar cada modelo, debes consultar una comparación
de características entre SQL Database y SQL Managed Instance. Hay disponible una
comparación completa de características en https://docs.microsoft.com/azure/azure-sql/
database/features-comparison.
A continuación, vamos a describir algunas de las características de SQL Database.
Empecemos con las características de aplicación.
Características de aplicación
Azure SQL Database proporciona varias características específicas de la aplicación que
atienden a los diferentes requisitos de los sistemas OLTP:
- Almacén de columnas: esta característica permite que el almacenamiento de datos
esté en formato de columnas en lugar de en formato de filas. - OLTP in-memory: generalmente, los datos se almacenan en archivos de back-end
en SQL y los datos se extraen de ellos cuando la aplicación lo necesita. De manera
opuesta, OLTP in-memory pone todos los datos en la memoria y no hay latencia
en la lectura del almacenamiento de datos. Almacenar datos de OLTP in-memory
en SSD proporciona el mejor rendimiento posible para Azure SQL. - Todas las características de SQL Server on-premises
La siguiente característica que vamos a describir es la alta disponibilidad.
Alta disponibilidad
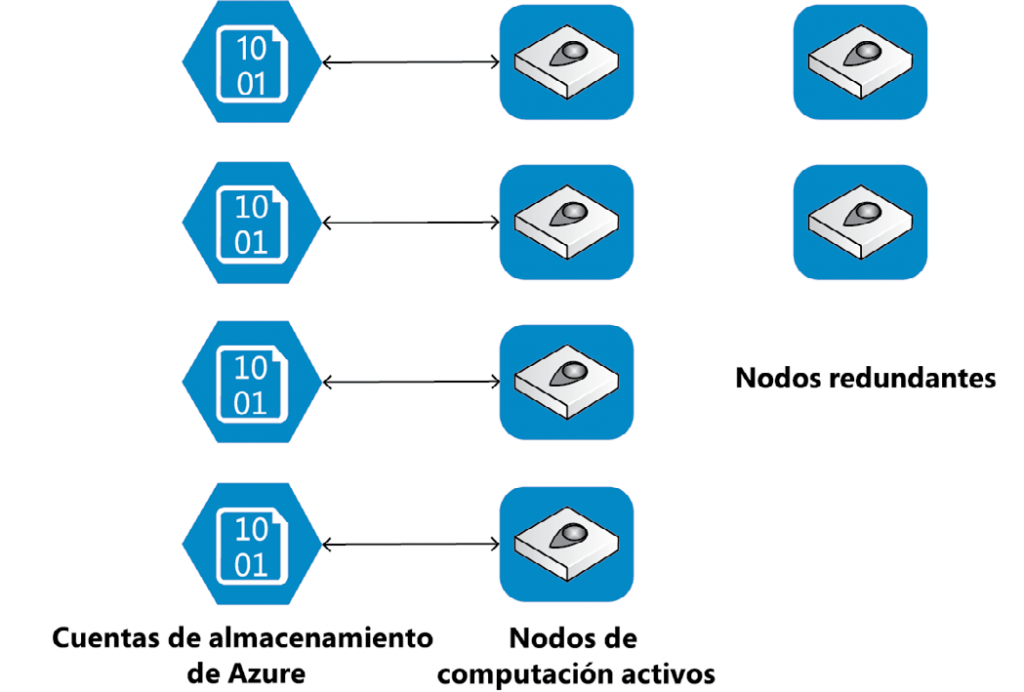
De forma predeterminada, Azure SQL tiene un 99,99 % de alta disponibilidad. Cuenta con
dos arquitecturas diferentes para mantener la alta disponibilidad basadas en SKU. Para las
SKU Básica, Estándar y General, toda la arquitectura se desglosa en las dos capas siguientes.
- Capa de computación
- Capa de almacenamiento
Hay redundancia incorporada para ambas capas para proporcionar la alta disponibilidad:
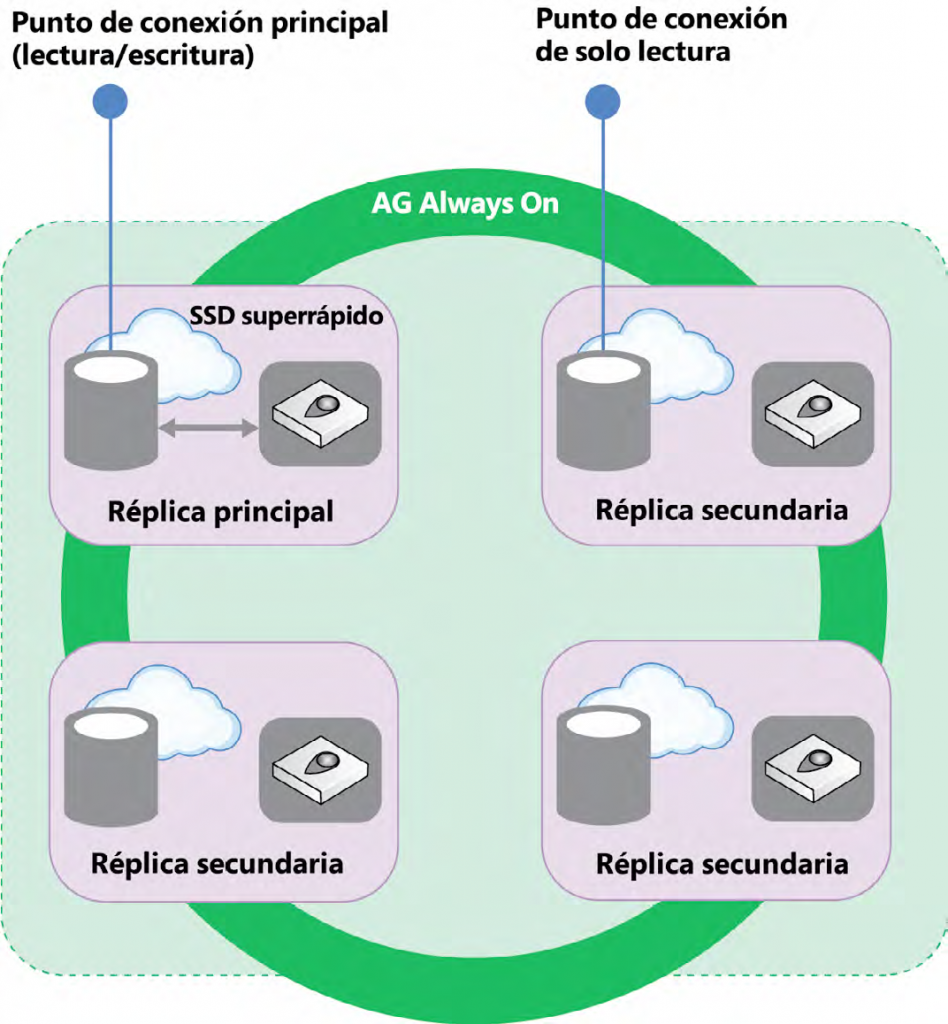
Para las SKU Premium y fundamentales para el negocio, tanto
la computación como el almacenamiento están en la misma capa. La alta disponibilidad se
logra mediante la replicación de la computación y el almacenamiento implementados en un
clúster de cuatro nodos, utilizando tecnología similar a los grupos de disponibilidad Always
On de SQL Server:
Ahora que ya sabes cómo se gestiona la alta disponibilidad, vamos a pasar a la siguiente
característica: las copias de seguridad.
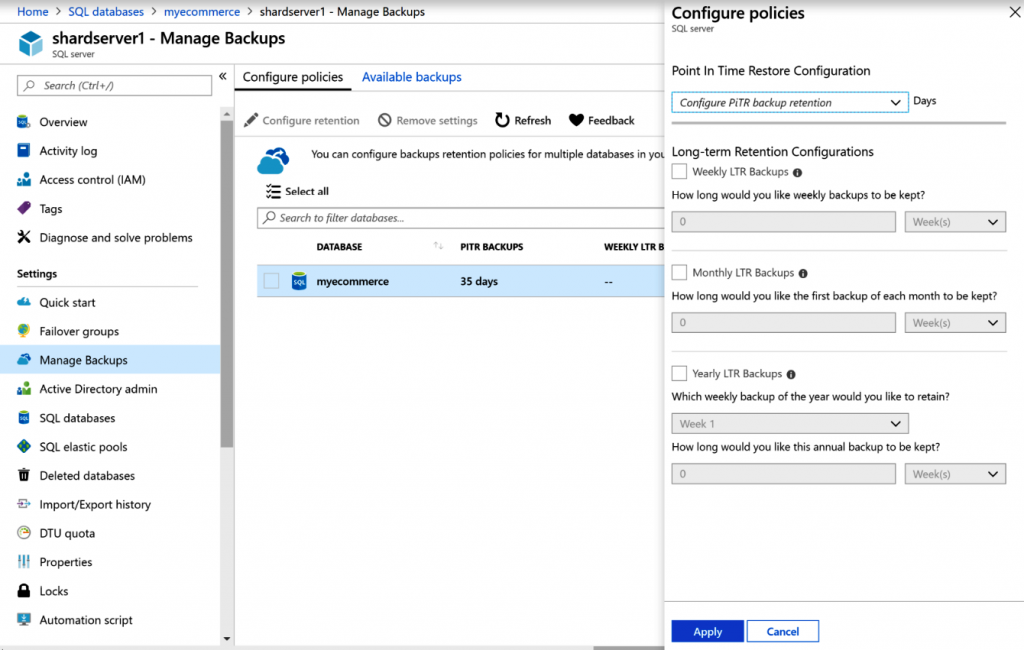
Copias de seguridad
Azure SQL Database también ofrece características para realizar automáticamente copias
de seguridad de las bases de datos y almacenarlas en cuentas de almacenamiento. Esta
característica es importante, especialmente en los casos en que una base de datos se daña
o un usuario elimina accidentalmente una tabla. Está disponible en el nivel de servidor,
como se muestra en la Figura 7.6:
Los arquitectos deben preparar una estrategia de copias de seguridad para que las copias
se puedan usar cuando se necesiten. Al configurar las copias de seguridad, asegúrate
de que las copias de seguridad se produzcan con la frecuencia adecuada. En función de
las necesidades del negocio, se debe configurar una copia de seguridad semanal, diaria
o incluso con mayor frecuencia, si es necesario. Estas copias de seguridad se pueden
utilizar con fines de restauración.
Las copias de seguridad ayudarán en la continuidad del negocio y en la recuperación de
datos. También puedes utilizar la replicación geográfica para recuperar los datos durante
un error en una región. Abordaremos la replicación geográfica en la siguiente sección.
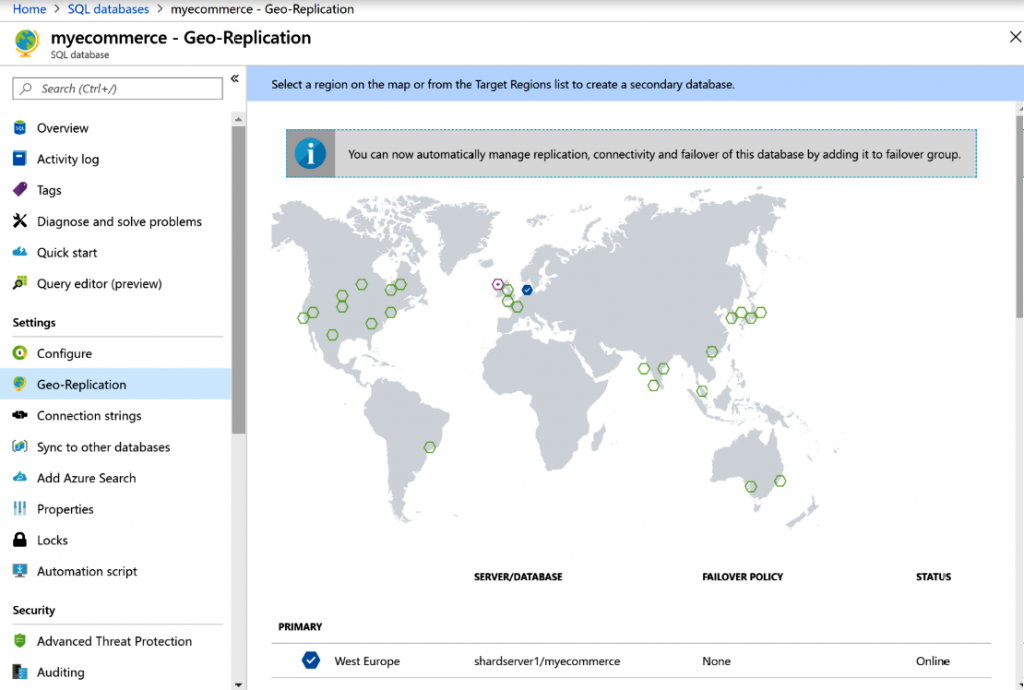
Replicación geográfica
Azure SQL Database también proporciona la ventaja de poder replicar una base
de datos en una región diferente, también conocida como región secundaria; esto se
basa completamente en el plan que elijas. Las aplicaciones pueden leer la base de datos
de la región secundaria. Azure SQL Database permite bases de datos secundarias legibles.
Esta es una gran solución de continuidad del negocio ya que una base de datos legible
está disponible en cualquier momento. Con la replicación geográfica, es posible tener
hasta cuatro secundarias de una base de datos en diferentes regiones o en la misma
región. Con la replicación geográfica, también es posible conmutar por error a una base
de datos secundaria en el caso de que se produzca un desastre. La replicación geográfica
se configura en el nivel de base de datos, como se muestra en la Figura 7.7:
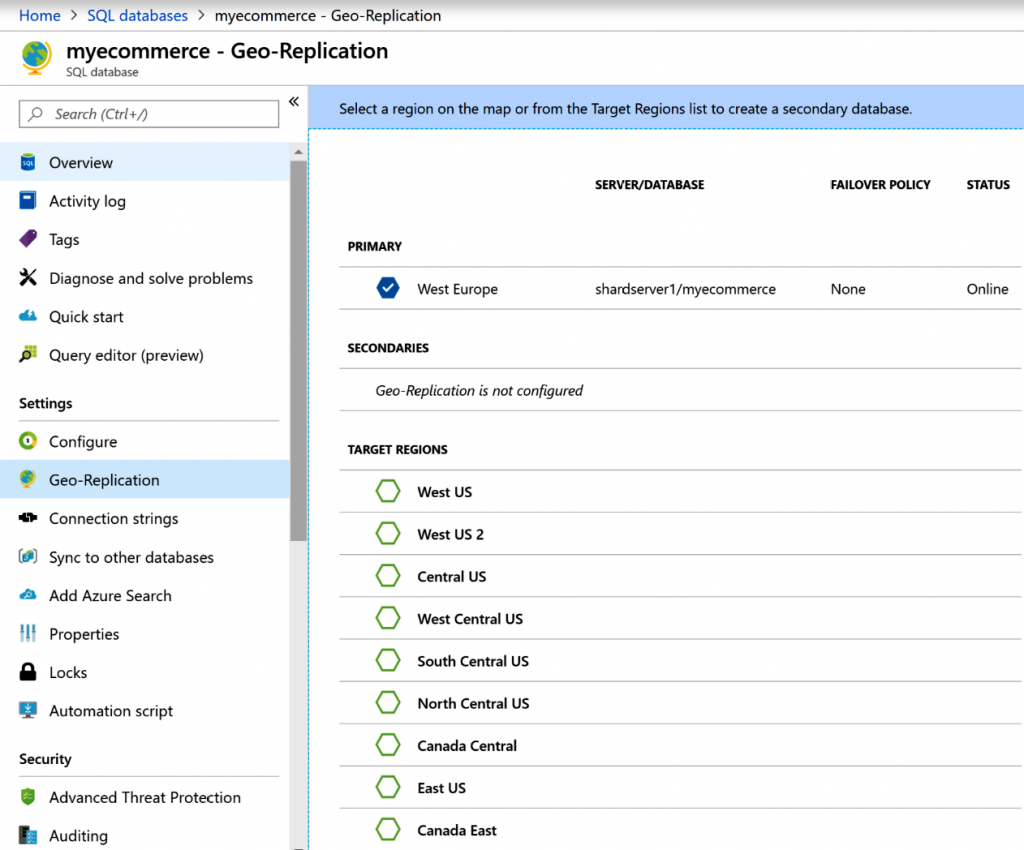
Si te desplazas hacia abajo en esta pantalla, las regiones que pueden actuar como
secundarias aparecen enumeradas, como se muestra en la Figura 7.8:
Antes de diseñar soluciones que impliquen la replicación geográfica, tenemos que validar
la residencia de datos y las regulaciones de cumplimiento. Si no se permite que los datos de
los clientes se almacenen fuera de una región por motivos de cumplimiento, no deberíamos
replicarlos en otras regiones.
En la siguiente sección, explicaremos las opciones de escalabilidad.
Escalabilidad
Azure SQL Database proporciona escalabilidad vertical mediante la adición de más
recursos (como computación, memoria e IOPS). Esto se puede hacer al aumentar el
número de unidades de rendimiento de base de datos (DTU) o recursos de computación
y almacenamiento en el caso del modelo de núcleo virtual:
Describiremos las diferencias entre el modelo basado en DTU y el modelo basado en
núcleos virtuales más adelante en este capítulo.
En la siguiente sección, hablaremos de la seguridad, lo que te ayudará a entender cómo
crear soluciones de datos seguras en Azure.
Seguridad
La seguridad es un factor importante para cualquier solución o servicio de base de datos.
Azure SQL proporciona seguridad de nivel empresarial para Azure SQL y en esta sección
se enumerarán algunas de las características de seguridad importantes de Azure SQL.
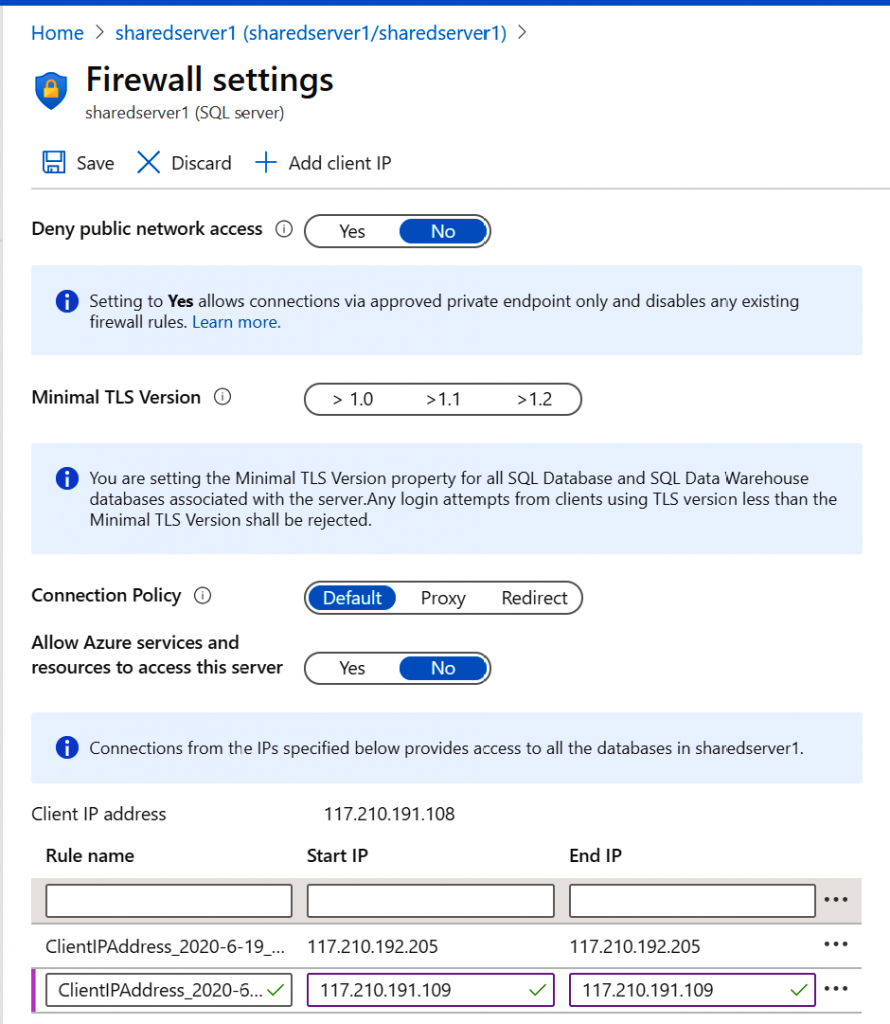
Firewall
De forma predeterminada, Azure SQL Database no proporciona acceso a ninguna solicitud.
Las direcciones IP de origen se deben aceptar expresamente para obtener acceso a SQL
Server. Hay una opción para permitir que todos los servicios basados en Azure también
puedan acceder a la base de datos SQL. Esta opción incluye máquinas virtuales hospedadas
en Azure.
El firewall se puede configurar en el nivel de servidor en lugar del nivel de base de datos.
La opción Permitir el acceso a servicios de Azure permite que todos los servicios, incluidas
las máquinas virtuales, accedan a la base de datos hospedada en un servidor lógico.
De forma predeterminada, esta opción estará desactivará por motivos de seguridad;
si se habilita, se permitirá el acceso desde todos los servicios de Azure:
Azure SQL Server en redes dedicadas
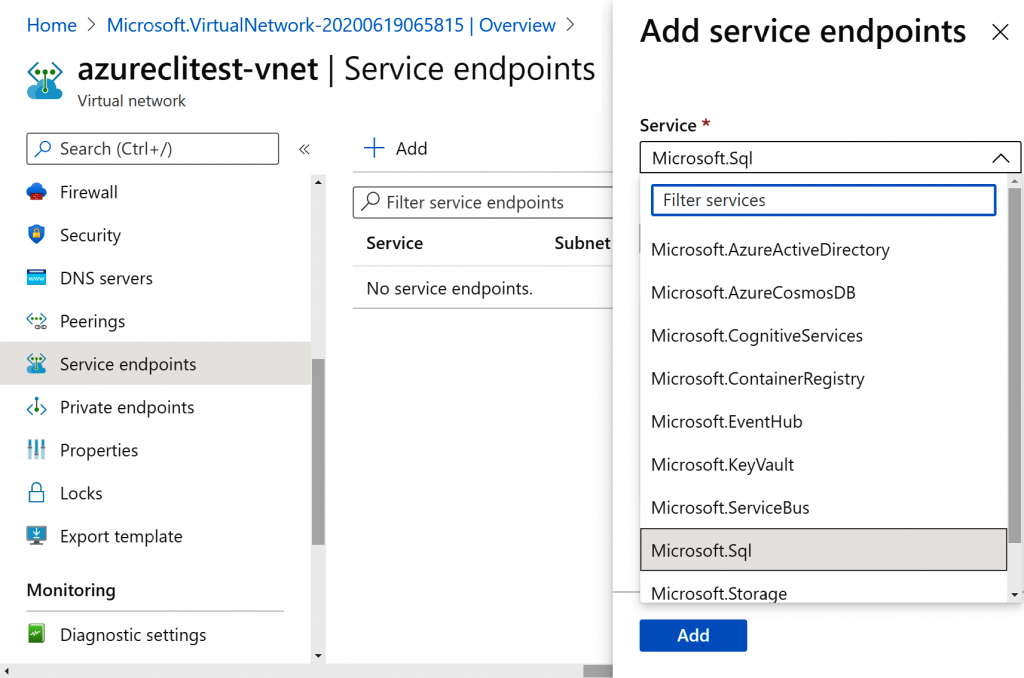
Aunque normalmente se puede acceder a SQL Server a través de Internet, es posible que el
acceso se limite a las solicitudes procedentes de redes virtuales. Esta es una característica
relativamente nueva de Azure. Esto ayuda a acceder a los datos de SQL Server desde una
aplicación de otro servidor de la red virtual sin que la solicitud pase por Internet.
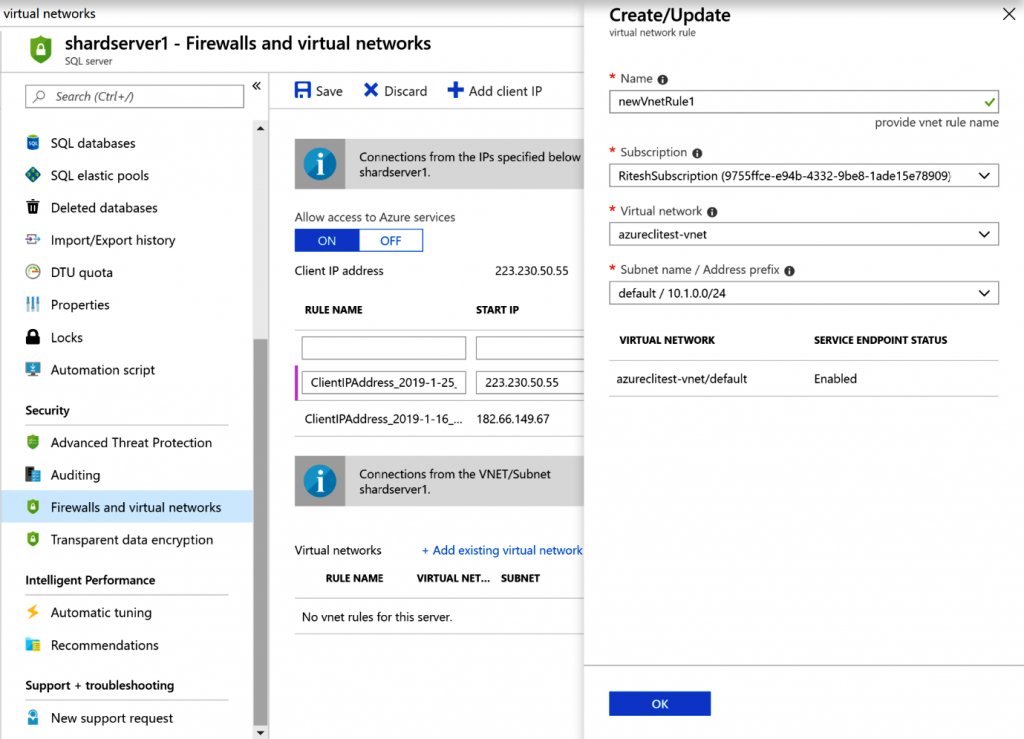
Para ello, se debe agregar un punto de conexión de servicio del tipo Microsoft.Sql dentro
de la red virtual y esta debe encontrarse en la misma región que la de Azure SQL Database:
Se debe elegir una subred apropiada dentro de la red virtual:
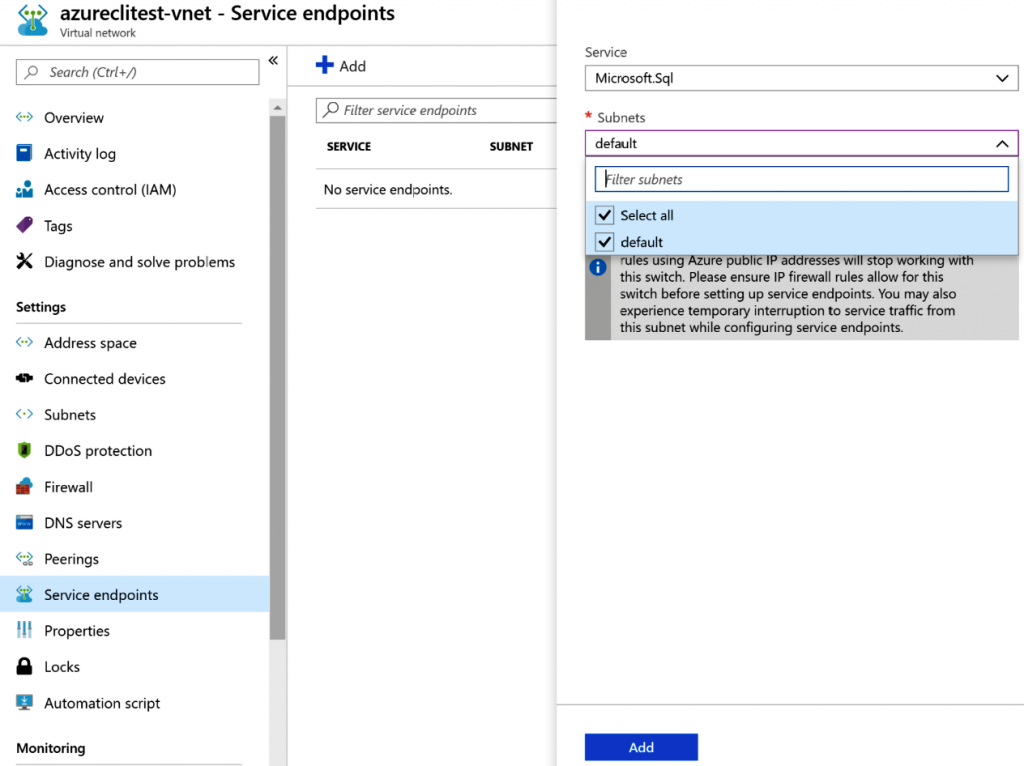
Por último, en la hoja de configuración de Azure SQL Server, se debe agregar una red virtual
existente que tenga un punto de conexión de servicio Microsoft.Sql habilitado:
Bases de datos cifradas en reposo
Las bases de datos deben estar en forma cifrada cuando estén en reposo. En reposo significa
que los datos están en la ubicación de almacenamiento de la base de datos. Aunque es posible
que no tengas acceso a SQL Server y su base de datos, es preferible cifrar el almacenamiento
de la base de datos.
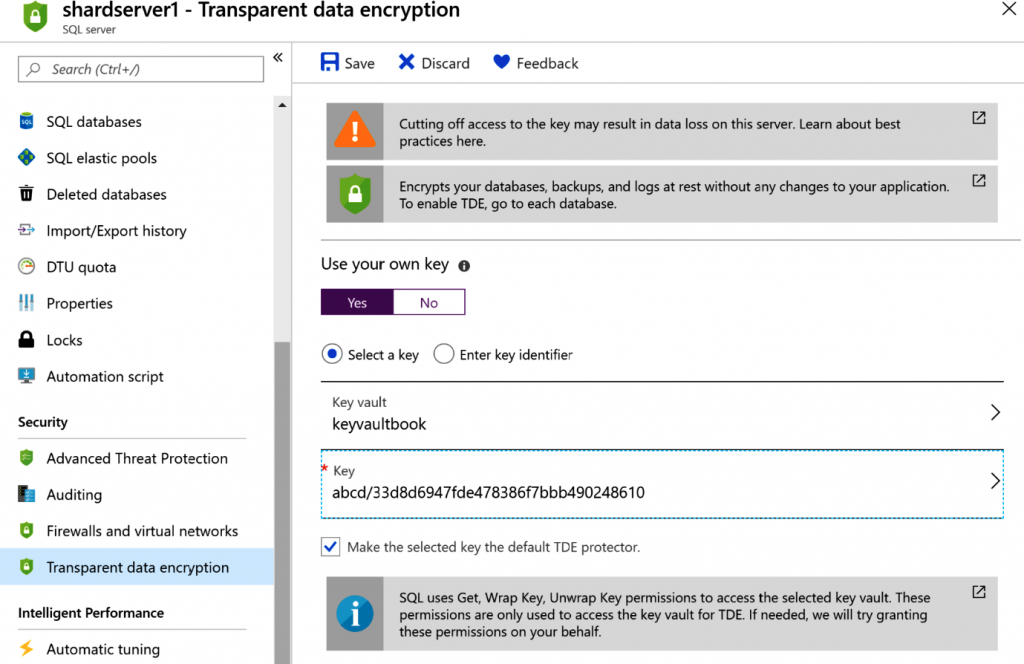
Las bases de datos de un sistema de archivos se pueden cifrar mediante claves. Estas claves
deben almacenarse en Azure Key Vault y el almacén debe estar disponible en la misma
región que la de Azure SQL Server. Para cifrar el sistema de archivos, utiliza el elemento
de menú Cifrado de datos transparente de la hoja de configuración de SQL Server
y selecciona Sí para Usar su propia clave.
La clave es una clave RSA 2048 y debe existir dentro del almacén. SQL Server descifrará
los datos en el nivel de página cuando desee leerlos y enviarlos al autor de la llamada y,
a continuación, los cifrará después de escribirlos en la base de datos. No se requieren
cambios en las aplicaciones y es completamente transparente para ellas:
Enmascaramiento dinámico de datos
SQL Server también proporciona una característica que enmascara las columnas
individuales que contienen datos confidenciales para que nadie, aparte de los usuarios con
privilegios, pueda ver los datos reales mediante una consulta en SQL Server Management
Studio. Los datos permanecerán enmascarados y solo se desenmascararán cuando una
aplicación o un usuario autorizado consulte la tabla. Los arquitectos deben asegurarse
de que se enmascaren los datos confidenciales, como los detalles de la tarjeta de crédito,
números de la seguridad social, números de teléfono, direcciones de correo electrónico
y otros detalles financieros.
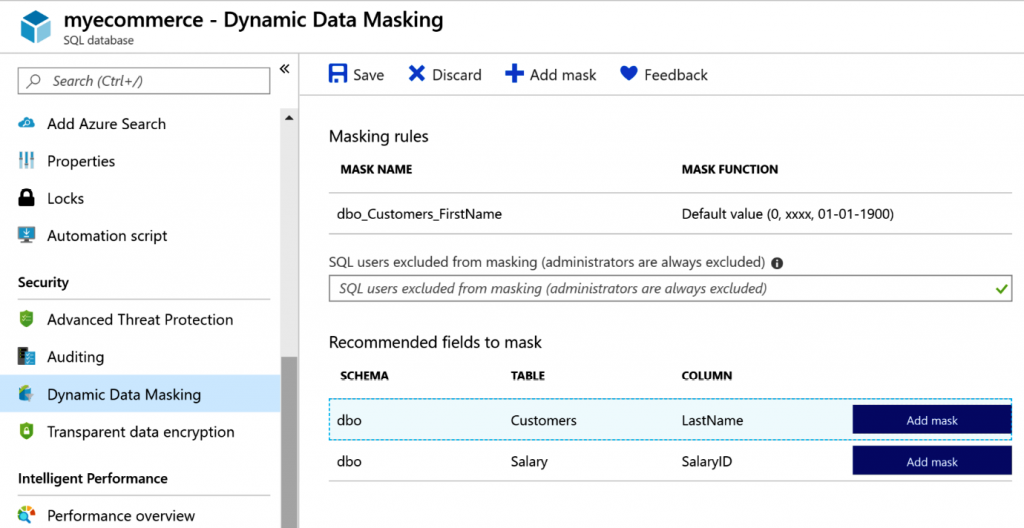
Las reglas de enmascaramiento se pueden definir en una columna de una tabla. Hay cuatro
tipos principales de máscaras, las cuales puedes consultar aquí: https://docs.microsoft.
com/sql/relational-databases/security/dynamic-data-masking?view=sql-serverver15#
defining-a-dynamic-data-mask.
En la Figura 7.15 se muestra cómo se agrega el enmascaramiento de datos:
Integración de Azure Active Directory
Otra característica de seguridad importante de Azure SQL es que se puede integrar con
Azure Active Directory (AD) con fines de autenticación. Sin la integración con Azure AD,
el único mecanismo de autenticación disponible para SQL Server es mediante nombre
de usuario y contraseña; es decir, la autenticación de SQL. No es posible utilizar la
autenticación integrada de Windows. La cadena de conexión para la autenticación de
SQL consta de nombre de usuario y contraseña en texto sin formato, que no es seguro.
La integración con Azure AD permite la autenticación de aplicaciones con la autenticación
de Windows, un nombre de entidad de servicio o una autenticación basada en token.
Se considera una buena práctica utilizar Azure SQL Database integrado con Azure AD.
Hay otras características de seguridad, como Advanced Threat Protection, la auditoría del
entorno y la supervisión, que deben habilitarse en cualquier implementación de Azure SQL
Database de nivel empresarial.
Con esto, hemos concluido nuestro estudio de las características de Azure SQL Database
y ahora podemos pasar a los tipos de bases de datos SQL.
Instancia única
Las bases de datos de instancia única se hospedan como una sola base de datos en un
único servidor lógico. Estas bases de datos no tienen acceso a las características completas
proporcionadas por SQL Server. Cada base de datos está aislada y es portátil. Las instancias
únicas admiten los modelos de compra basados en vCPU y DTU que hemos explicado
anteriormente.
Otra ventaja añadida de una sola base de datos es la rentabilidad. Si utilizas un modelo
basado en núcleos virtuales, puedes optar por reducir los recursos de computación y
almacenamiento para optimizar los costes. Si necesitas más potencia de computación
o almacenamiento, siempre puedes escalar verticalmente. La escalabilidad dinámica
es una característica destacada de las instancias únicas que ayuda a escalar recursos
dinámicamente en función de los requisitos del negocio. Las instancias únicas permiten
a los clientes de SQL Server existentes trasladar mediante «lift-and-shift» sus aplicaciones
on-premises al cloud.
Otras características incluyen disponibilidad, supervisión y seguridad.
Cuando comenzamos nuestra sección sobre Azure SQL Database, mencionamos también
los grupos elásticos. También puedes hacer la transición de una sola base de datos a un
grupo elástico para el uso compartido de recursos. Si te preguntas qué son los recursos
compartidos y qué son los grupos elásticos, en la siguiente sección hablaremos de ello.
Grupos elásticos
Un grupo elástico es un contenedor lógico que puede hospedar varias bases de datos
en un único servidor lógico. Los grupos elásticos están disponibles en los modelos de
compra basados en núcleos virtuales y DTU. El modelo de compra basado en vCPU es el
método de implementación predeterminado y recomendado, donde tendrás la libertad de
elegir tus recursos de computación y almacenamiento en función de tus cargas de trabajo
empresariales. Como se muestra en la Figura 7.16, puedes seleccionar cuántos núcleos
y cuánto almacenamiento necesitas para tu base de datos:
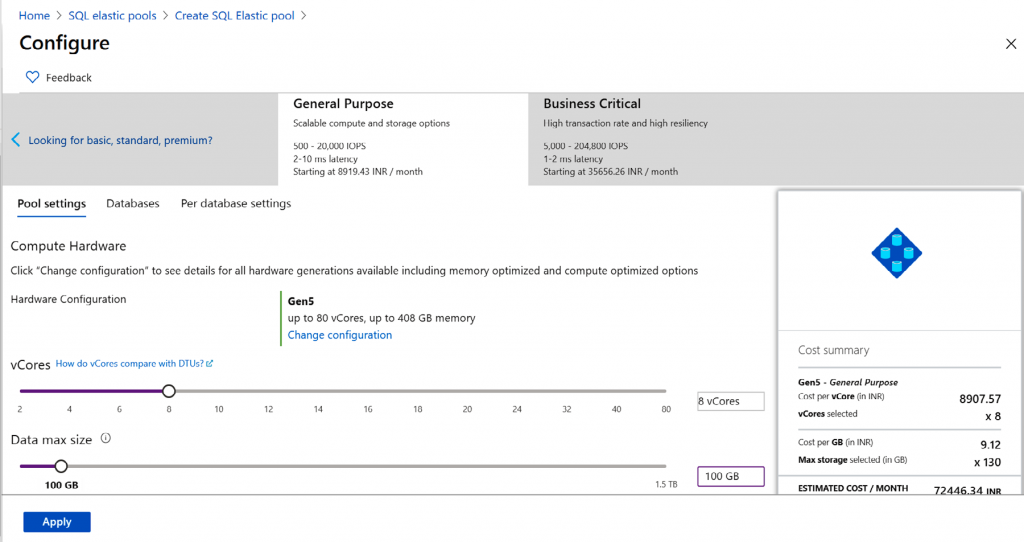
Además, en la parte superior de la figura anterior, puedes ver que hay una opción que
dice ¿Buscas básico, estándar, premium? (Looking for basic, standard, premium?).
Si la seleccionas, el modelo se cambiará al modelo DTU.
Las SKU disponibles para los grupos elásticos en el modelo basado en DTU son las siguientes:
- Básico
- Estándar
- Premium
En la Figura 7.17 se muestra la cantidad máxima de DTU que se puede aprovisionar para
cada SKU:
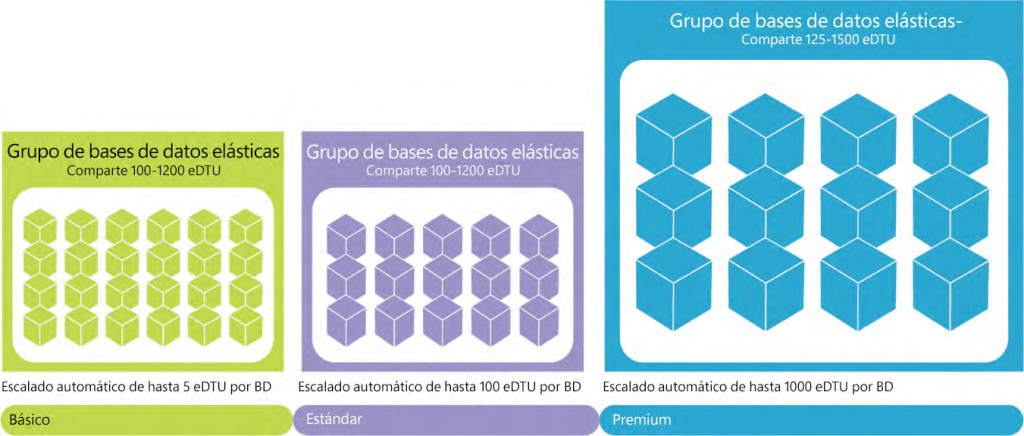
Todas las características descritas para instancias únicas de Azure SQL también están
disponibles para los grupos elásticos; sin embargo, la escalabilidad horizontal es una
característica adicional que permite el particionamiento. El particionamiento hace
referencia a la partición vertical u horizontal de los datos y al almacenamiento de los
datos en bases de datos independientes. También es posible realizar escalado automático
de bases de datos individuales en un grupo elástico mediante el consumo de más DTU que
las asignadas realmente a esa base de datos.
Los grupos elásticos también proporcionan otra ventaja en términos de coste. En una
sección posterior veremos que el precio de Azure SQL Database se fija usando el concepto
de DTU y que las DTU se aprovisionan en cuanto se aprovisiona el servicio SQL Server. Las
DTU se cobran independientemente de si se consumen o no. Si hay varias bases de datos,
es posible colocarlas en grupos elásticos, de forma que puedan compartir las DTU entre ellas.
Toda la información para implementar el particionamiento con grupos elásticos de Azure
SQL se proporciona en https://docs.microsoft.com/azure/sql-database/sql-databaseelastic-
scale-introduction.
A continuación, analizaremos la opción de implementación Instancia administrada, que
es una base de datos escalable, inteligente, basada en el cloud y totalmente administrada.
Instancia administrada
Instancia administrada es un servicio único que proporciona un SQL Server administrado
similar al que está disponible en los servidores on-premises. Los usuarios tienen acceso
a la base de datos maestra, modelo y otras del sistema. Instancia administrada es ideal
cuando hay varias bases de datos y los clientes están migrando sus instancias a Azure.
Instancia administrada se compone de varias bases de datos.
Azure SQL Database proporciona un nuevo modelo de implementación conocido como
Instancia administrada de Azure SQL Database que proporciona casi un 100 % de
compatibilidad con el motor de base de datos de SQL Server Enterprise Edition. Este
modelo proporciona una implementación de red virtual nativa que da respuesta a los
problemas de seguridad habituales y es un modelo de negocio muy recomendado para los
clientes de SQL Server on-premises. Instancia administrada permite a los clientes de SQL
Server elevar y desplazar sus aplicaciones on-premises al cloud con cambios mínimos en
las aplicaciones y bases de datos, conservando al mismo tiempo todas las capacidades de
PaaS. Estas capacidades de PaaS reducen drásticamente la sobrecarga de administración
y el coste total de propiedad, como se muestra en la Figura 7.18:
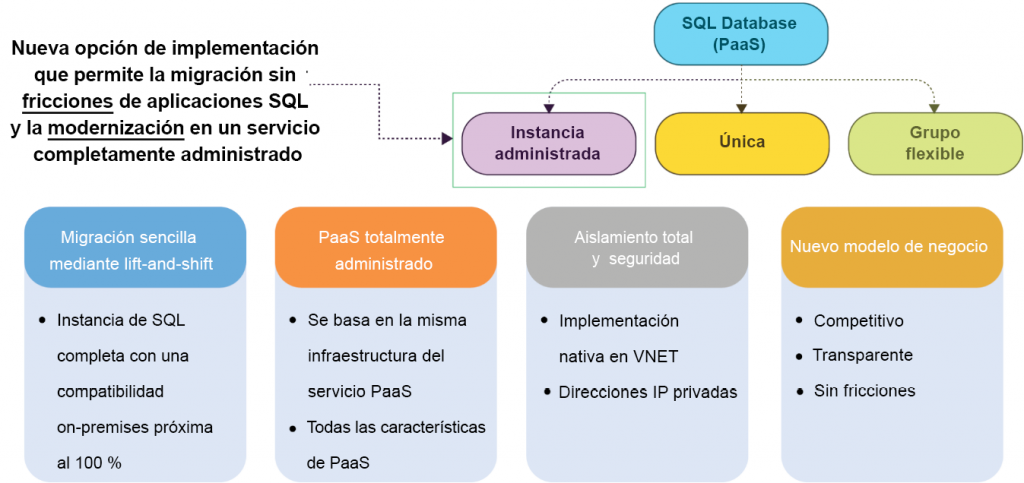
La comparación completa entre Azure SQL Database, Azure SQL Managed Instance y SQL
Server en una máquina virtual de Azure está disponible aquí: https://docs.microsoft.com/
azure/azure-sql/azure-sql-iaas-vs-paas-what-is-overview#comparison-table
Las características clave de Instancia administrada se muestran en la Figura 7.19:
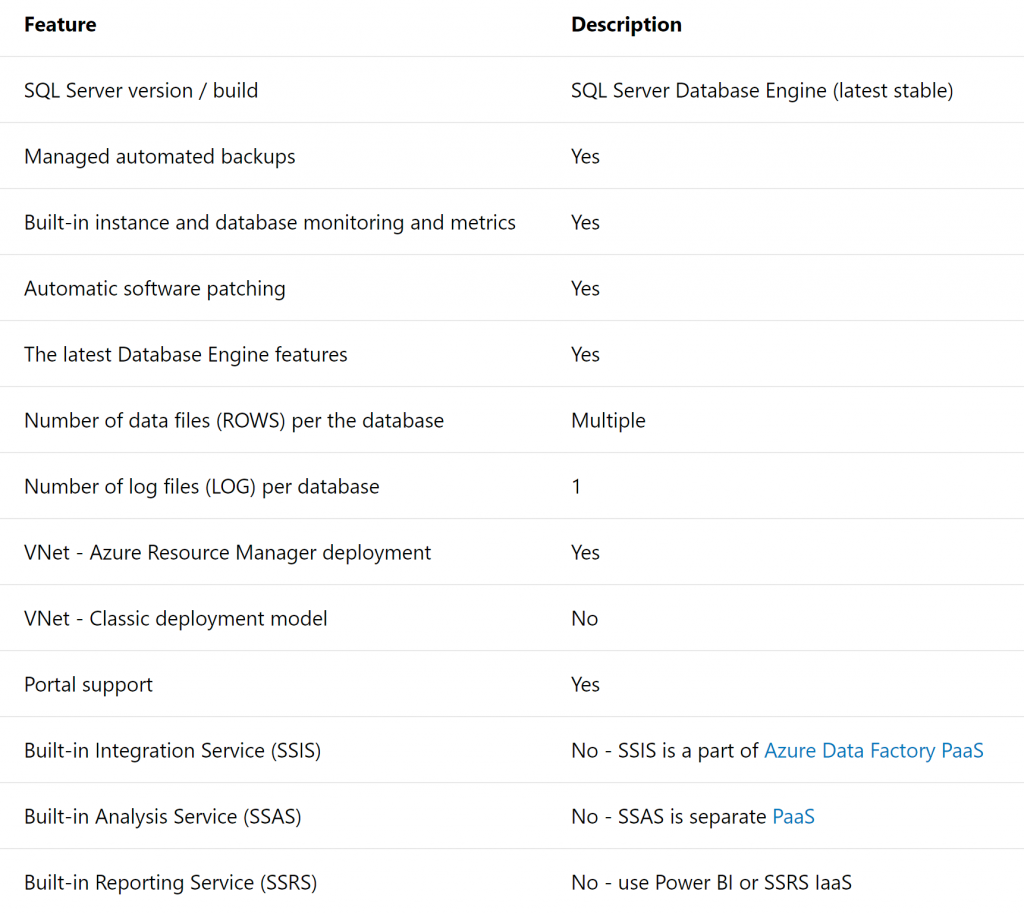
Hemos mencionado los términos del modelo de precios basado en vCPU y del modelo
de precios basado en DTU en varios puntos a lo largo del capítulo. Ha llegado el momento
de examinar más de cerca estos modelos de precios.
Información de precios de base de datos SQL
Azure SQL anteriormente solo tenía un modelo de precios, que se basaba en DTU, pero
se ha lanzado un modelo de precios alternativo más reciente basado en vCPU. El modelo
de precios se selecciona en función de los requisitos del cliente. El modelo basado en DTU
se selecciona cuando el cliente desea opciones de recursos simples y preconfiguradas. Por
otro lado, el modelo basado en núcleos virtuales ofrece la flexibilidad de elegir recursos
de computación y almacenamiento. También proporciona control y transparencia.
Veamos con más detenimiento cada uno de estos modelos.
Precios basados en DTU
La DTU es la unidad de medida de rendimiento más pequeña de Azure SQL Database.
Cada DTU se corresponde con cierta cantidad de recursos. Estos recursos incluyen
almacenamiento, ciclos de CPU, IOPS y ancho de banda de red. Por ejemplo, una sola
DTU podría proporcionar tres IOPS, varios ciclos de CPU y latencias de E/S de 5 ms
para las operaciones de lectura y 10 ms para las operaciones de escritura.
Azure SQL Database proporciona varias SKU para crear bases de datos y cada una de estas
SKU tiene restricciones definidas para la cantidad máxima de DTU. Por ejemplo, la SKU básica
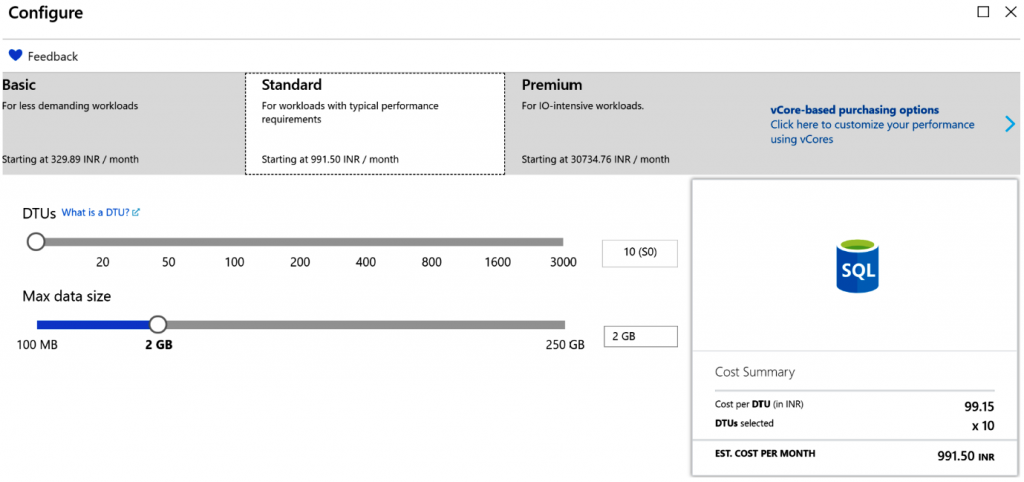
proporciona solo 5 DTU con un máximo de 2 GB de datos, como se muestra en la Figura 7.20:
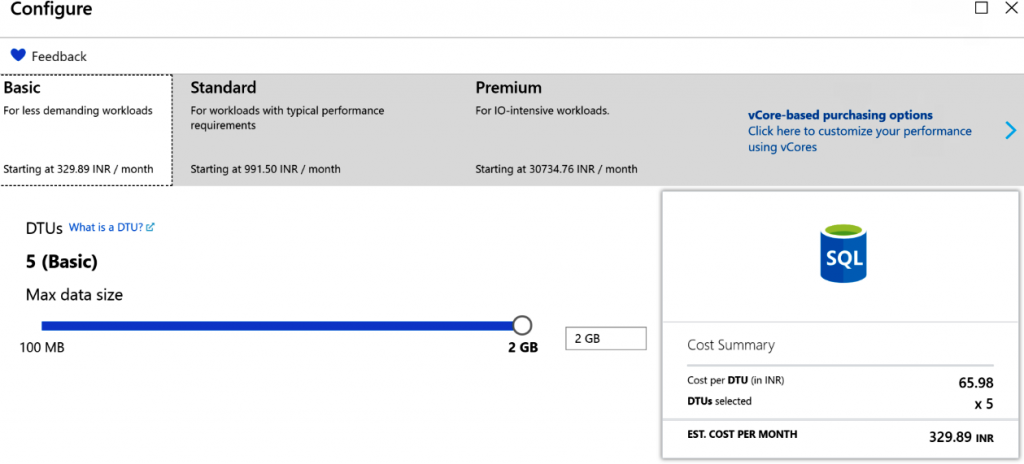
Por otro lado, la SKU estándar proporciona cualquier valor entre 10 y 300 con un
máximo de 250 de datos. Como puedes ver aquí, cada DTU cuesta alrededor de 991 rupias
o alrededor de 1,40 USD:
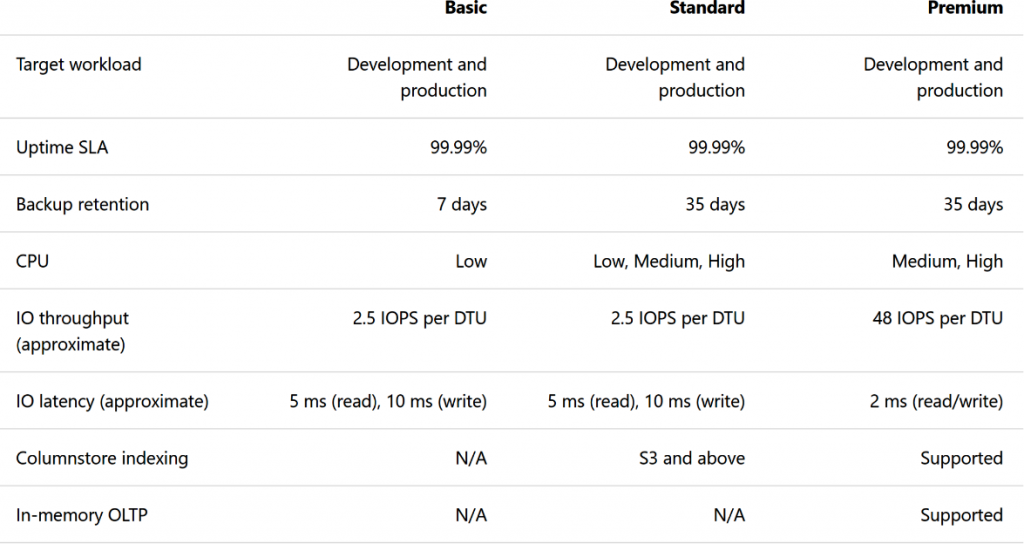
Microsoft proporciona una comparación de estas SKU en términos de rendimiento
y recursos, como se muestra en la Figura 7.22:
Una vez que aprovisiona un determinado número de DTU, los recursos de back-end (CPU,
IOPS y memoria) se asignan y se cobran, tanto si se consumen como si no. Si se adquieren
más DTU de las que realmente se necesitan, da lugar a desperdicio, mientras que habrá
cuellos de botella de rendimiento si no se aprovisionan las suficientes.
Azure también proporciona grupos elásticos para este propósito. Como ya sabes, en un
grupo elástico hay varias bases de datos y las DTU se asignan a grupos elásticos en lugar
de a bases de datos individuales. Es posible que todas las bases de datos de un grupo
compartan las DTU. Esto significa que si una base de datos tiene baja utilización y está
consumiendo solo 5 DTU, habrá otra base de datos que consumirá 25 DTU para compensar.
Es importante tener en cuenta que, colectivamente, el consumo de DTU no puede superar
la cantidad de DTU aprovisionada para el grupo elástico. Además, hay una cantidad mínima
de DTU que se debe asignar a cada base de datos dentro del grupo elástico y este recuento
mínimo de DTU se asigna previamente.
Un grupo elástico incluye sus propias SKU:
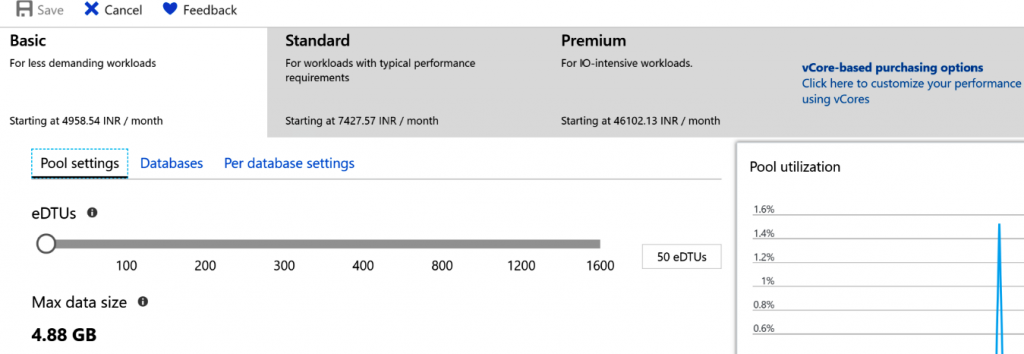
Además, hay un límite en el número máximo de bases de datos que se pueden crear dentro
de un único grupo elástico. Los límites completos se pueden revisar aquí: https://docs.
microsoft.com/azure/azure-sql/database/resource-limits-dtu-elastic-pools.
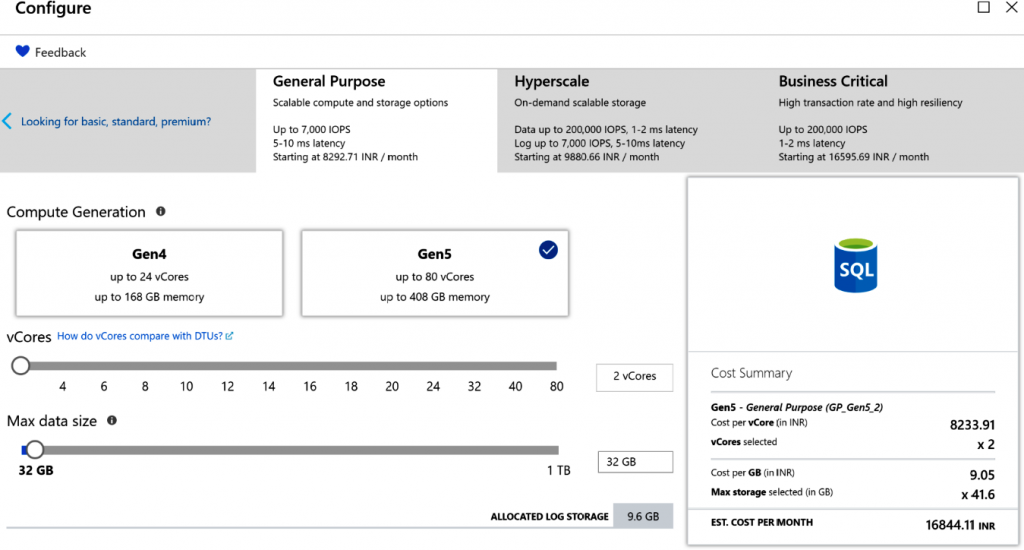
Precios basados en vCPU
Este es el nuevo modelo de precios de Azure SQL. Este modelo de precios proporciona
opciones para adquirir el número de CPU virtuales (vCPU) asignadas para el servidor en
lugar de configurar la cantidad de DTU necesarias para una aplicación. Una vCPU es una
CPU lógica con hardware conectado, como almacenamiento, memoria y núcleos de CPU.
En este modelo, hay tres SKU: Uso general, Hiperescala y Crítico para la empresa, con un
número variado de vCPU y recursos disponibles. Este precio está disponible para todos los
modelos de implementación de SQL:
Cómo elegir el modelo de precios adecuado
Los arquitectos deberían poder elegir un modelo de precios adecuado para Azure SQL
Database. Las DTU son un mecanismo excelente para fijar los precios cuando hay un patrón
de uso aplicable y disponible para la base de datos. Dado que la disponibilidad de recursos
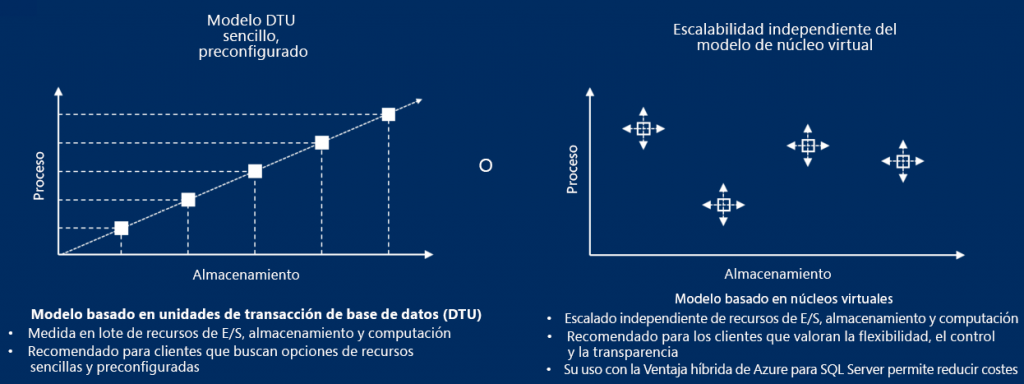
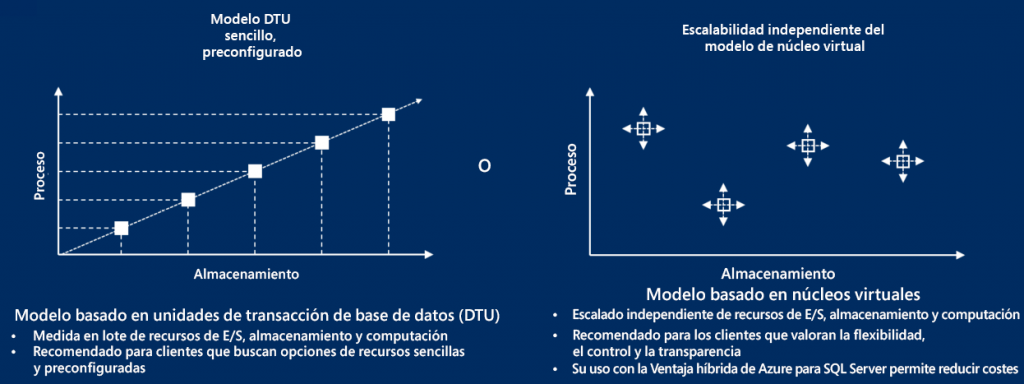
en el esquema de DTU es lineal, como se muestra en el siguiente diagrama, es muy posible
que el uso sea más intensivo con respecto a la memoria que a la CPU. En tales casos, es
posible elegir diferentes niveles de CPU, memoria y almacenamiento para una base de datos.
En las DTU, los recursos vienen empaquetados y no es posible configurar estos recursos
en un nivel pormenorizado. Con un modelo de vCPU, es posible elegir diferentes niveles
de memoria y CPU para las distintas bases de datos. Si se conoce el patrón de uso de una
aplicación, el modelo de precios de vCPU podría ser mejor opción que el modelo de DTU.
De hecho, el modelo de vCPU también ofrece la ventaja de las licencias híbridas si una
organización ya tiene licencias de SQL Server on-premises. A estas instancias de
SQL Server se proporciona un descuento de hasta el 30 %.
En la Figura 7.25, puedes ver en el gráfico de la izquierda que a medida que aumenta la
cantidad de DTU, la disponibilidad de recursos también crece linealmente. Sin embargo,
con los precios de vCPU (en el gráfico de la derecha), es posible elegir configuraciones
independientes para cada base de datos:
Con esto, podemos concluir nuestra cobertura de Azure SQL Database. Hemos hablado de
diferentes métodos de implementación, características, precios y planes relacionados con
Azure SQL Database. En la siguiente sección, hablaremos de Cosmos DB, que es un servicio
de base de datos NoSQL.
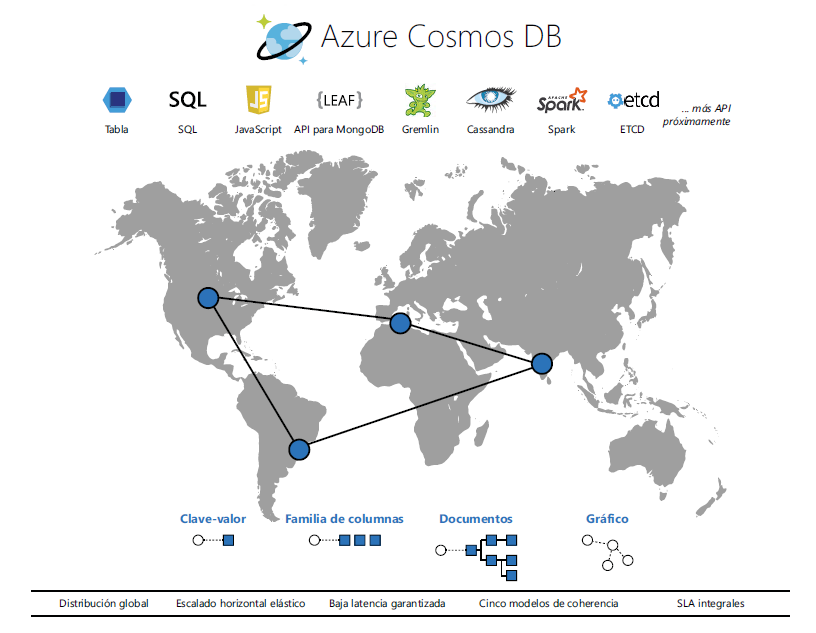
Azure Cosmos DB
Cosmos DB es el verdadero servicio de base de datos entre regiones, altamente disponible,
distribuido y multimodelo de Azure. Cosmos DB es la opción que debes elegir si quieres que
tu solución tenga una gran capacidad de respuesta y esté siempre disponible. Al ser una
base de datos multimodelo entre regiones, podemos implementar aplicaciones más cerca
de la ubicación del usuario y lograr baja latencia y alta disponibilidad.
Con solo hacer clic en un botón, el rendimiento y el almacenamiento se pueden escalar en
cualquier número de regiones de Azure. Hay algunos modelos de base de datos diferentes
para cubrir casi todos los requisitos de bases de datos no relacionales, incluidos los
siguientes:
- SQL (documentos)
- MongoDB
- Cassandra
- Table
- Gremlin Graph
La jerarquía de los objetos dentro de Cosmos DB comienza con la cuenta de Cosmos DB.
Una cuenta puede tener varias bases de datos y cada base de datos puede tener varios
contenedores. En función del tipo de base de datos, el contenedor puede constar de
documentos, como en el caso de SQL; datos de clave-valor semiestructurados dentro
del almacenamiento de tablas; o entidades y relaciones entre esas entidades, si se usa
Gremlin y Cassandra para almacenar datos NoSQL.
Cosmos DB se puede utilizar para almacenar datos OLTP. Equivale a ACID con respecto
a los datos de transacciones, con algunas salvedades.
Cosmos DB proporciona los requisitos ACID en el nivel de documento único. Esto significa
que los datos de un documento, cuando se actualizan, eliminan o insertan, mantienen su
atomicidad, coherencia, aislamiento y durabilidad. Sin embargo, además de los documentos,
la coherencia y la atomicidad tienen que ser gestionadas por el propio desarrollador.
Los precios de Cosmos DB se pueden encontrar aquí: https://azure.microsoft.com/pricing/
details/cosmos-db.
En la Figura 7.26 se muestran algunas características de Azure Cosmos DB:
En la siguiente sección, trataremos algunas características clave de Azure Cosmos DB.
Características
Algunas de las principales ventajas de Azure Cosmos DB son:
- Distribución global: las aplicaciones con gran capacidad de respuesta y altamente
disponibles se pueden crear en todo el mundo mediante Azure Cosmos DB. Con la
ayuda de la replicación, se pueden almacenar réplicas de datos en regiones de Azure
cerca de los usuarios, lo que proporciona menos latencia y una distribución global. - Replicación: puedes optar por la replicación o rechazarla en una región cuando así
lo prefieras. Supongamos que tienes una réplica de los datos disponibles en la región
Este de EE. UU. y tu organización tiene previsto cerrar sus procesos en el este de EE.
UU. y migrar al sur del Reino Unido. Con solo unos clics, se puede eliminar Este de
EE. UU. y se puede agregar Sur de Reino Unido a la cuenta para su replicación. - Always On: Cosmos DB proporciona un 99,999 % de alta disponibilidad tanto para
lectura como para escritura. La conmutación por error regional de una cuenta de
Cosmos DB a otra región se puede invocar a través de Azure Portal o mediante
programación. Esto garantiza la continuidad del negocio y la planificación de
la recuperación ante desastres de la aplicación durante un error en una región. - Escalabilidad: Cosmos DB ofrece una escalabilidad flexible inigualable para escritura
y lectura en todo el mundo. La respuesta de escalabilidad es masiva, lo que significa
que se puede escalar de miles a cientos de millones de solicitudes por segundo con
una sola llamada a la API. Lo interesante es que esto se hace en todo el mundo, pero
solo hay que pagar por el rendimiento y el almacenamiento. Este nivel de escalabilidad
es ideal para gestionar picos inesperados. - Baja latencia: como se ha mencionado anteriormente, la replicación de copias de
datos en ubicaciones más cercanas a los usuarios reduce drásticamente la latencia;
esto significa que los usuarios pueden acceder a sus datos en milisegundos. Cosmos
DB garantiza menos de 10 ms de latencia tanto para lecturas como para escrituras
en todo el mundo. - Ahorro de TCO: como Cosmos DB es un servicio totalmente administrado, el nivel de
administración requerido al cliente es bajo. Además, el cliente no tiene que configurar
centros de datos en todo el mundo para dar cabida a usuarios de otras regiones. - SLA: ofrece un SLA de alta disponibilidad del 99,999 %.
- Compatibilidad con API de software de código abierto (OSS): la compatibilidad con
las API de OSS es otra ventaja añadida de Cosmos DB. Cosmos DB implementa API
para Cassandra, Mongo DB, Gremlin y Azure Table Storage.
Escenarios de casos prácticos
Si tu aplicación implica altos niveles de lecturas y escrituras de datos a escala global,
Cosmos DB es la opción ideal. Los tipos comunes de aplicaciones que tienen estos
requisitos incluyen aplicaciones web, móviles, de videojuegos y del Internet de las cosas.
Estas aplicaciones se beneficiarían de la alta disponibilidad, baja latencia y presencia global
de Cosmos DB.
Además, el tiempo de respuesta proporcionado por Cosmos DB es casi en tiempo real.
Los SDK de Cosmos DB se pueden aprovechar para desarrollar aplicaciones iOS y Android
utilizando la plataforma Xamarin.
Algunos de los juegos más populares que usan Cosmos DB son The Walking Dead: No Man’s
Land de Next Games y Halo 5: Guardians.
Aquí puedes encontrar una lista completa de escenarios y ejemplos de casos prácticos:
https://docs.microsoft.com/azure/cosmos-db/use-cases.
Cosmos DB es el servicio de referencia en Azure para almacenar datos semiestructurados
como parte de aplicaciones OLTP. Podría escribir un libro completo únicamente sobre las
características y capacidades de Cosmos DB; la intención de esta sección era ofrecerte una
introducción a Cosmos DB y al papel que desempeña en la gestión de aplicaciones OLTP.
Resumen
En este capítulo, has aprendido que Azure SQL Database es uno de los servicios insignia
de Azure. Una gran cantidad de clientes utilizan hoy en día este servicio que proporciona
todas las capacidades empresariales necesarias para un sistema de administración de bases
de datos esenciales.
Has aprendido que hay varios tipos de implementación en Azure SQL Database, como
Instancia única, Instancia administrada y los grupos elásticos. Los arquitectos deben
realizar una evaluación completa de sus requisitos y elegir el modelo de implementación
adecuado. Después de elegir un modelo de implementación, deben elegir una estrategia
de precios, entre DTU y vCPU. También deben configurar todos los requisitos de seguridad,
disponibilidad, recuperación ante desastres, supervisión, rendimiento y escalabilidad de
Azure SQL Database con respecto a los datos.
En el siguiente capítulo, analizaremos cómo crear aplicaciones seguras en Azure.
Hablaremos de las prácticas y características de seguridad de la mayoría de los servicios.