



Data Selection Techniques in Machine Learning: Hold-Out, Cross-Validation, and More
Most machine learning models do not fail because of the algorithm itself… they fail because the validation was done incorrectly. Data selection is one of the most important stages when building a predictive model. It consists of splitting a dataset into different subsets to train, validate, and evaluate the model properly. Although it may seem like a basic step, a poor split can seriously affect the quality of the results.
If the data is not divided correctly, the model may appear highly accurate during training but fail when exposed to new information. That is why choosing the right validation strategy is essential to obtain reliable metrics and build models that truly generalize.
What is data selection?
Data selection is the process of deciding which part of the dataset will be used to train the model and which part will be reserved for validation or testing. Its goal is to simulate the model’s behavior in a real-world environment, where it will have to work with data it has never seen before.
Normally, the dataset is divided into three sets:
- Training set: the model learns patterns.
- Validation set: hyperparameters are adjusted and models are compared.
- Test set: final performance is measured.
This separation makes it possible to evaluate whether the model is learning useful patterns or simply memorizing the data.
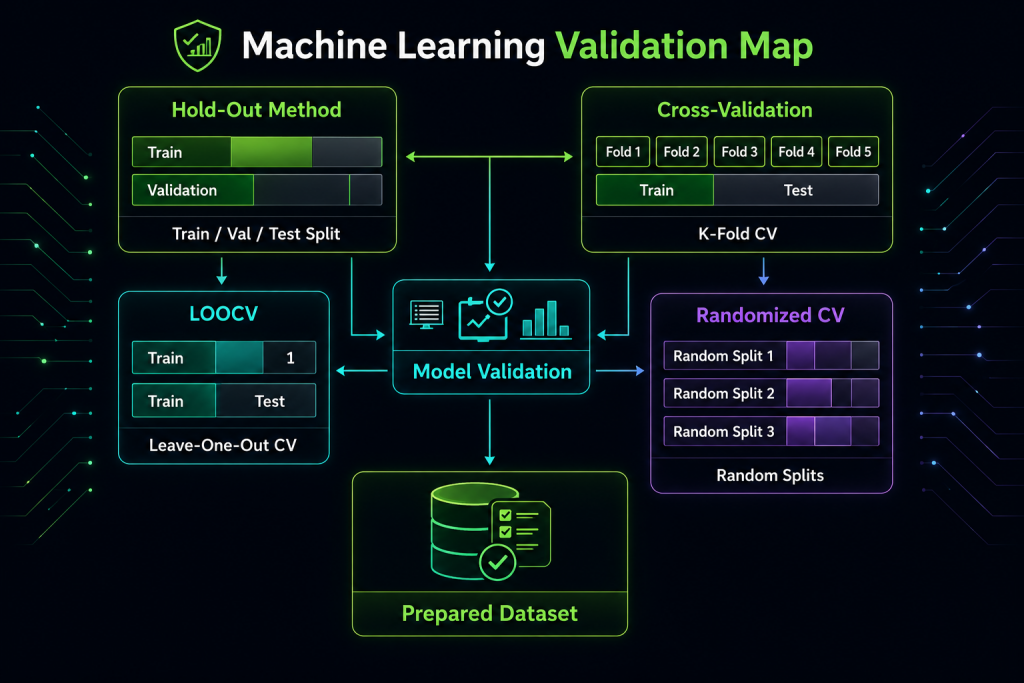
Diagram of data selection and validation techniques in Machine Learning.
Why is it important to validate data properly?
Proper validation allows you to measure the model’s ability to generalize. In other words, it helps determine whether the system will perform well on new data.
In addition, a good data selection strategy helps to:
- Detect overfitting.
- Avoid data leakage.
- Compare models fairly.
- Obtain more realistic metrics.
- Improve confidence in the results.
In real projects, this step is key to avoiding costly mistakes in production.
Main data selection techniques
| Technique | Description | When to use it |
|---|---|---|
| Hold-out | Splits the dataset into training, validation, and test sets. Simple and fast. | Large datasets, quick evaluations. |
| Cross-validation | Splits the data into k parts and repeats training several times. | Medium or small datasets, stable evaluation. |
| LOOCV | Each observation acts as validation once. | Very small datasets. |
| Randomized CV | Uses multiple random splits to measure stability. | When a single split may bias the results. |
Hold-out: the simplest option
The hold-out method is fast and easy to implement. However, the results can depend heavily on the initial split, so it is not always the most stable option.
Cross-validation: a more robust evaluation
Cross-validation reduces dependence on a single split and provides a more stable estimate of model performance. It is ideal when the dataset is not very large.
LOOCV: useful for small datasets
It uses almost all the data for training, but it is computationally expensive. It is only recommended for small datasets.
Randomized Cross-Validation: more flexibility
It allows you to evaluate the model’s stability across multiple random splits. It is very useful when you suspect that a single split may not represent the real behavior of the model well.
Best practices for splitting data
- Keep the target stratified.
- Respect the time order in time series problems.
- Avoid letting test data leak into training.
- Clearly separate validation and test sets.
- Save the random seed.
- Apply preprocessing only on the training set.
Common mistakes
- Training and evaluating on the same data.
- Tuning hyperparameters using the test set.
- Ignoring data leakage.
- Mixing temporal data without respecting order.
Practical example
Dataset with 10,000 records to predict churn:
- 70% training
- 15% validation
- 15% test
If the problem is imbalanced, stratification is mandatory.
Conclusion
Data selection is much more than a simple split. It is an essential part of the training and validation process because it allows you to measure the model’s real performance and avoid mistakes such as overfitting or data leakage.
A well-designed validation strategy helps build more reliable, more stable models that are better prepared for production.
TL;DR
Data selection is used to split the dataset correctly and evaluate whether a model truly generalizes. Techniques such as hold-out, cross-validation, and LOOCV help measure performance more reliably. Good validation prevents overfitting, data leakage, and misleading metrics.