



Regression (Part 6): Ridge & Lasso — Taming Overfitting
When your model has too much freedom, the solution isn’t to take it away — it’s to charge for using it.
In Part 5 we saw something powerful and something dangerous. The powerful part: by adding extra columns — x², x³, x⁴… — our model can learn curves with ease. The dangerous part: the more columns we add, the more the model can twist itself to fit every training point, including the noise.
The result is familiar: a degree‑10 polynomial that hits every training point perfectly… and then produces absurd predictions in between. Huge coefficients, wild oscillations, perfect training error, terrible validation error.
Our only defense so far was caution: keep the degree low, use cross‑validation, start simple. That’s like saying “drive slowly.” It works, but it limits how far you can go.
Regularization is the seat belt that lets the model run fast without losing control.
1. The real problem: coefficients that explode
When a model tries to chase noise, it needs to make sharp bends. Sharp bends require huge coefficients.
Typical symptoms:
- coefficients with massive magnitudes
- alternating signs
- violent oscillations between data points
- training error drops
- validation error skyrockets
If we control the coefficients, we control overfitting.
2. The key idea: penalize complexity
Until now, the model had one goal:
Regularization adds a second goal:
The new cost function is:
- The first term wants to fit the data.
- The second term wants to keep the model humble.
λ (lambda) is the dial that controls how strict we are.
Metaphor:
“I won’t forbid you from using x² or x³… but I’ll charge you for exaggerating.”
3. Ridge Regression (L2): smooth without removing
Ridge penalizes the sum of squared coefficients:
Effect:
- big coefficients pay a heavy price
- small coefficients pay a small price
- all coefficients shrink, but none go to zero
Result:
- smoother curves
- no wild oscillations
- all features remain in the model
Metaphor:
“Ridge is adding shock absorbers: the car stays powerful, but stops bouncing on every bump.”
4. Lasso Regression (L1): keep what matters, drop the rest
Lasso penalizes the sum of absolute values:
Effect:
- constant pressure toward zero
- if a coefficient contributes little, it becomes exactly zero
- the model performs automatic feature selection
Result:
- smooth curves
- simpler equations
- fewer terms, more interpretability
Metaphor:
“Lasso is cleaning a closet: what you don’t use, goes out.”
5. Ridge vs Lasso (quick summary)
| Method | What it does | Best use case |
|---|---|---|
| Ridge (L2) | Shrinks coefficients | When most features matter |
| Lasso (L1) | Eliminates coefficients | When only a few features matter |
| Elastic Net | Mix of L1 + L2 | When features are correlated |
6. The role of λ: the discipline dial
- λ = 0 → no regularization → chaos
- small λ → slight smoothing
- optimal λ → perfect balance
- large λ → overly rigid model → underfitting
We choose λ using cross‑validation, just like we choose polynomial degree.
7. How training works (light version)
Gradient descent stays the same. Only the derivatives change:
Ridge:
→ gentle pull toward zero.
Lasso:
→ constant push until the coefficient hits zero.
That’s all you need for intuition.
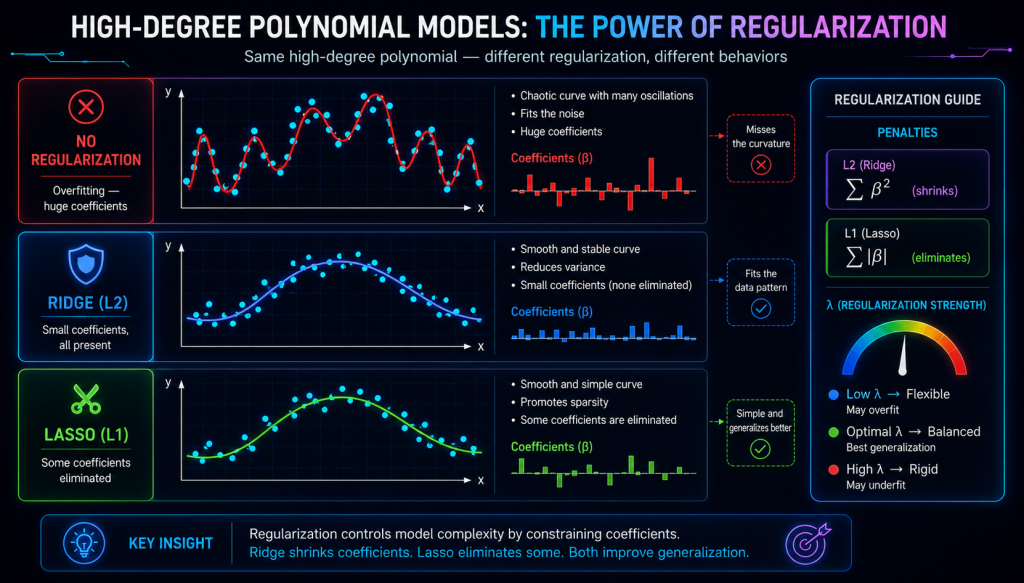
8. A visual example (conceptual)
Imagine the same degree‑10 polynomial:
- No regularization: chaotic curve, huge coefficients.
- Ridge: smooth curve, small coefficients.
- Lasso: smooth curve, simple equation (only x and x² survive).
Three treatments, three outcomes. Only Ridge and Lasso tame the chaos.
9. When to use regularization
Use regularization when:
- validation error ≫ training error
- coefficients are huge
- you have many features
- you use high‑degree polynomials
- features are correlated
- the model is unstable
Skip regularization when:
- you have lots of data and few features
- the model already generalizes well
- the problem is lack of expressiveness, not excess
10. In summary
- Overfitting happens when coefficients explode.
- Regularization penalizes that explosion.
- Ridge shrinks coefficients.
- Lasso eliminates coefficients.
- λ controls how strict we are.
- Training still uses gradient descent.
- Regularization is the seat belt for flexible models.